Supplementary Information (doc 170K)
advertisement
")
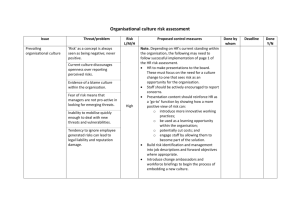
Supplemental Methods Experimental Paradigm Subjects completed a total of 200 trials (4 conditions * 50 trials per condition) for each drug/placebo session, with the order of the conditions counterbalanced across runs and subjects. Within each run of 50 trials, an intertrial interval of 0-8 seconds separated each trial. Although subjects were not directly cued to the nature of the reward space, the clock face changed color between runs to indicate that a different task condition was present. A different set of four colors was used on the second day to avoid cuing subjects to the reward structure. Power Analysis For power computations, the primary data analysis endpoint for the exploration parameter was the interaction between factors of drug and genotype in a two-way repeatedmeasures ANOVA. Specifically, using the G*Power statistics tool (http://gpower.hhu.de) for a repeated measure with two levels (drug condition) and a between-subjects factor with three levels (genotype), we calculated the number of subjects needed to detect an effect with 80% power at an alpha of 0.05, assuming a moderate effect size (0.25) and a modest correlation between repeated measures (0.25). Based on these parameters, the critical F value was 3.15, and the necessary number of subjects was 63. Selecting greater than 80% power, a smaller effect size, or a smaller correlation between repeated measures would naturally increase the number of subjects required. Computational Model: Overview Previous studies have shown that RTs in the exploration-exploitation task can be well predicted by assuming that participants track the outcome statistics associated with two general classes of responses (‘fast’ vs. ‘slow’ – they are instructed in advance that sometimes they will do better by responding faster and sometimes slower). However, this assumption does not limit the ability of the model to account for continuous variations in RT. By tracking statistics only with these two classes, subjects can nevertheless adjust their RTs in a continuous way as a function of the relative difference in the expected values of these options (Badre et al, 2012; Cavanagh et al, 2012; Frank et al, 2009; Strauss et al, 2011). Indeed, the exploitation component of the model estimates the degree to which responses are adjusted as a function of the relative difference in the mean expected values for fast and slow responses. More specifically, both exploitation of the RTs producing the highest rewards and exploration for even better rewards are driven by errors of prediction in tracking expected reward value V. On trial t, the expected reward for each clock face is calculated as V(t) = V(t-1) + αδ(t-1) where α determines how rapidly V is updated and δ is the reward prediction error (RPE). This V value represents the average expected value of rewards in each clock face, but the goal of the learner is to try to maximize their rewards and hence select RTs that produce the largest number of positive deviations from this average. Because it is unreasonable to assume that learners track a separate value for each RT from 0 to 5000ms, a simplifying assumption is that the learners can track the values of responses that are faster or slower than average. A strategic exploitation component thus tracks the reward structure associated with distinct response classes (fast or slow, respectively). This component is intended to capture how participants track the probability of realizing a better than expected outcome (positive RPE) following faster or slower responses, allowing them to continuously adjust RTs in proportion to their relative value differences. The model contains two factors relevant to exploitation: the parameter ρ and the quantity αG - αN (described below). Unlike the explore parameter ε, which scales the difference in the uncertainties of the two (fast/slow) distributions, the parameter ρ scales the degree to which subjects adjust their responses as a function of the relative difference in the mean expected values: ρ [ μ slow (t) – μ fast (t) ] Thus, subjects with larger ρ parameters tend to choose the option that has led to a larger number of positive prediction errors in the past. Similarly, the model also incorporates a potential bias for subjects to speed / slow RTs differentially for positive and negative reward prediction errors, captured by parameters αG and αN that represent learning rates in the striatal “Go” and “NoGo” pathways, respectively. Importantly for this study, our previous work has demonstrated that these factors are affected by striatal genes and/or more diffuse dopaminergic changes (Frank et al, 2009; Moustafa et al, 2008), leading to the prediction that they should be insensitive to the effects of COMT inhibition. Computational Model: Detailed Explanation In addition to the components described above and in the main text, the full RT model included additional contributions to responding that were not a focus of the present experiment, for consistency with prior reports. The full model estimates reaction time ( R̂T ) on trial t as follows: R̂T (t) = K + l RT (t -1) - Go(t) + NoGo(t) + r[mslow (t) - m fast (t)]+ n [RTbest - RTavg ]+ Explore(t) where K is a free parameter capturing baseline response speed (irrespective of reward), l reflects autocorrelation between the current and previous RT, and n captures the tendency to adapt RTs toward the single largest reward experienced thus far (“going for gold”). For details on these parameters, see Frank et al. (2009). Their inclusion allows the model to better fit overall RTs but we have found that they do not change the pattern of findings associated with exploration or exploitation. Go and NoGo learning reflect a striatal bias to speed responding as a function of positive reward prediction errors (RPEs) and to slow responding as a function of negative RPEs. Evidence for speeding and slowing in the task is separately tracked: Go(t) = Go(t-1) + G +(t-1) NoGo(t) = NoGo(t-1) + where G positive ( and +) L L (t-1) are the previously-described learning rates scaling the effects of and negative ( ) errors in expected value prediction V (i.e., positive and negative RPE). Go learning speeds RT, while NoGo learning slows it. This bias to speed and slow RTs as a function of positive and negative RPEs is adaptive in this task given that subjects tend to initially make relatively fast responses, and prior studies have found that these biases and model parameters are influenced by striatal dopaminergic manipulations and genetics (Frank et al, 2009; Moustafa et al, 2008). However, this approach does not consider when it is best to respond in a strategic manner, and in fact, it is not adaptive in environments where slow responses yield higher rewards (in which case positive and negative RPE's will lead to maladaptive RT adjustments). For the more strategic exploitative component, reward statistics were computed via Bayesian updating of “fast” or “slow” actions, as described in the main text. Fast or slow actions were classified based on whether they were faster or slower than the local average, which was computed as: RTavg(t) = RTavg(t-1) + [RT(t-1) - RTavg(t-1)] However, fast and slow responses can be defined in other ways – for example, based on whether the clock hand is in the first or second half of the clock face – and outcomes from the model are the same. (The use of an adaptive version of the boundary is more general and would allow the algorithm to converge to an appropriate RT even if reward functions are non-monotonic). Free parameters were estimated for each subject via the Simplex method as those minimizing the sum of squared error between predicted and observed RTs. Multiple starting points were used for each optimization process to reduce the likelihood of local minima. All parameters were free to vary for each participant, with the exception of used in the expected value (V) update, which was set to 0.1 for all participants to prevent model degeneracy (Frank et al, 2009). For other details regarding the primary continuous RT model, including alternative models that provide poorer behavioral fits to the data, please see Frank et al (2009). Note that among the alternative models tested in that paper is a Kalman filter model in which the mean expected reward values and their uncertainties are estimated with Normal distributions, rather than the beta distributions used here. However, the variance (uncertainty) in the Kalman filter tends to be overly dominated by the first trial: subjects are given no information about the number of possible points that they might gain, leading to large variance in initial estimates, which then declines more dramatically after a few trials when rewards are experienced than does the variance in the probability distributions for the beta priors. This phenomenon means that the neural estimate of relative uncertainty would largely reflect contributions of a very few number of trials using this model. For the “RT difference model”, the same procedure was used, except that parameters were optimized to predict the change in RT from one trial to the next, rather than the raw RT (and hence parameters related to autocorrelation and “going for gold” were dropped, because these quantities reflect attempts to model trends in overall RTs, not their differences). For the “negative- permitting model”, a similar procedure was used, except that epsilon values were permitted to take negative values. However, because participants tend to repeat the same action (fast or slow) after they have learned, this exploitation tendency results in the most selected action becoming the least uncertain (due to more sampling), and hence can cause a negative exploration parameter simply due to repeated action selection. To account for this phenomenon we also allowed a “sticky choice” parameter that captures the tendency for RTs in a given trial to be autocorrelated not only with the last trial but with an exponentially decaying history (see Badre et al 2012 and Cavanagh et al 2012). To maintain the same total number of parameters we removed the “going for gold” component in this model. Model Fits Goodness of fit was assessed by a sum squared error (SSE) term that reflected the difference between subject behavior (main paper, Figure 3A) and model predictions (main paper, Figure 3B). Because the number of data points and the number of parameters were identical across subjects, more complicated measures of goodness of fit (e.g. the Akaike Information Criterion) devolve to this simpler value. Mean SSE values were not significantly different across drug conditions: 6.3 x 107 ± 2.7 x 106 (s.e.m.) for tolcapone versus 6.4 x 107 ± 2.7 x 106 for placebo (F(1,62) = 0.54, p = 0.82 (n.s.)). A trend-level difference in SSE between genotypes (F(2,62) = 2.68, p = 0.076) was driven by a trend difference between SSE values for Met/Met (7.1 x 107 ± 4.5 x 106) and Val/Val (5.8 x 107 ± 3.9 x 106) subjects (Tukey’s test, p = 0.067). All other comparisons between groups, including Met/Val subjects (6.2 x 107 ± 3.5 x 106), were not significant. Finally, there was no drug x genotype interaction (F(2,62) = 0.38, p = 0.69 (n.s.)), arguing that even these trend-level differences cannot explain reliable differences in the Explore parameter across genotypes. We have also investigated whether the balance between reduced model complexity and increased goodness of fit might be better addressed by removing/adding model parameters. Our previous analyses converged upon the core model used in this report; their details are beyond the current scope but can be found in our previous work (Frank et al, 2009). Genetic Analysis Genotype and Locus of Control. Genotype groups did not differ significantly with respect to age, alcohol use, anxiety, impulsivity, or locus of control scores. In particular, as also noted in the body of the paper, no difference in LOC values was seen between the three COMT genotypes (F(2,62) = 0.88, p = 0.42 (n.s.)). Moreover, the median LOC value of 13 was well approximated by the mean values across genotypes: Met/Met = 12.1 ± 1.0 (s.e.m.), Met/Val = 13.6 ± 0.7, and Val/Val = 12.9 ± 0.6. Supplementary Figure Legends Figure S1. Reaction time (RT) data across all 50 trials of each task condition for the different subsets of drug and subject (left column) paired with the corresponding model predictions (right column). From top to bottom, these panels demonstrate placebo and tolcapone RT data, followed by RT data for subjects with the Met/Met, Met/Val, and Val/Val genotypes, respectively, at the COMT Val158Met polymorphism. The number of subjects contributing to each graph is indicated to the right of the subset label. Figure S2. The correlation between the change in reaction time from one trial to the next (“RT swing”) and the difference in the standard deviations of the fast and slow belief distributions (“Relative uncertainty”) for all sessions with a positive explore parameter across subjects, independent of drug condition. Both RT swing and relative uncertainty values have been converted to Z scores to facilitate comparison. As predicted, greater relative uncertainty on a given trial correlates with greater changes in RT from that trial to the next (mean r across participants = 0.33, p < 0.00001 for the t-test evaluating whether these coefficients are different from zero across participants). This positive correlation provides important support for the idea that relative uncertainty drives exploration of the reward space. Figure S3. A. Shown are the individual changes in the explore parameter (epsilon), in units of milliseconds per unit standard deviation of the belief distributions (ms/σ), from placebo (abscissa) to tolcapone (ordinate) for subjects of each genotype (red: Met/Met; blue: Met/Val; black: Val/Val). B. The same data shown in A are re-plotted, this time segregated by locus of control score for subjects with a more external (red: LOC ≤ 13) or more internal (blue: LOC > 13) score. In both plots, the preponderance of the red symbols lies above the dashed equality line. The panels also demonstrate the distribution of the explore parameter across subjects. Supplemental References Badre D, Doll BB, Long NM, Frank MJ (2012). Rostrolateral prefrontal cortex and individual differences in uncertainty-driven exploration. Neuron 73(3): 595-607. Cavanagh JF, Figueroa CM, Cohen MX, Frank MJ (2012). Frontal theta reflects uncertainty and unexpectedness during exploration and exploitation. Cereb Cortex 22(11): 2575-2586. Frank MJ, Doll BB, Oas-Terpstra J, Moreno F (2009). Prefrontal and striatal dopaminergic genes predict individual differences in exploration and exploitation. Nat Neurosci 12(8): 1062-1068. Moustafa AA, Cohen MX, Sherman SJ, Frank MJ (2008). A role for dopamine in temporal decision making and reward maximization in parkinsonism. J Neurosci 28(47): 12294-12304. Strauss GP, Frank MJ, Waltz JA, Kasanova Z, Herbener ES, Gold JM (2011). Deficits in positive reinforcement learning and uncertainty-driven exploration are associated with distinct aspects of negative symptoms in schizophrenia. Biol Psychiatry 69(5): 424-431.