Library: Folta Fragaria FA_SEa - the Genome Database for Rosaceae
advertisement

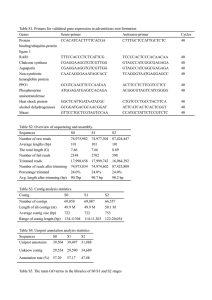
Library: Folta Fragaria FA_SEa The Fragaria EST data processed at CUGI utilized publicly available software incorporated in a fully automated in-house developed script (ProcEST.pl). The processing occurred in three stages: Stage I: Trace File Processing Sequence trace files were converted into fasta files and a quality score files using the phred (Ewing et al, 1998) base-calling program. Vector and host contamination were identified and masked using the sequence comparison program cross_match (Gordon, et al, 1998). Vector trimming excised the longest non-masked sequence and further trimming removed low quality bases (less than phred score 20) at both ends of a read. Sequences were discarded if they had greater than 5% ambiguous bases or less than 100 high quality bases (minimum phred score of 20). At this stage of processing the script generated an overall summary report file, clone report tables, a Genbank submission file and fasta formatted library files of the high quality trimmed sequences and associated quality values. The fasta library was not filtered to remove reads having significant similarity with the species specific mitochondial, rRNA, tRNA or snoRNA sequences as no Fragaria RNA sequences are currently available in GenBank. Stage II: Assembly of High Quality Sequences In stage II processing, the filtered library file was assembled using the contig assembly program CAP3 (Huang and Madan, 1999). More stringent parameters (- p 90. -d 60) were used to prevent over assembly and help identify potential paralogs. The assembly was refined where possible using homology to the swissprot database to indicate contig accuracy. Homology was determined by running the contigs and clones against Swiss Prot using the fastx3.4 algorithm (Pearson and Lipman, 1988) with EXP < 1e -6. Contigs whose clones showed difference in homology were deconstructed and contigs with the same homology to other contigs were joined using default CAP3 parameters. The unigene data set was derived by joining the contig and singleton data sets. Stage III: Annotation Annotation of the unigene data set consisted of pairwise comparison of both the filtered library and the contig consensus library file against the Genbank nr protein database using the fastx3.4 algorithm (Pearson and Lipman, 1988). The sequences were also characterized by comparison with the Genbank Rosaceae EST dataset (160,000 as of 072404) and the Genome Database for Rosaceae (GDR) mapped peach ESTs using the BLAST software package (Altschul, et al, 1997). The most significant matches (EXP < 1e -7) for each contig and individual clones in the library were recorded. Simple Sequence Repeats (SSRs) were indentified in the unigene data set using the CUGISSR.pl script and further filtered for optimal primer development according to GC content. The sequence, assembly, homology and SSR data will be stored in the GDR, facilitating efficient data querying and display. Users can view contig assembly, clones and annotation, download the library and unigene sequence libraries and search their sequences against the Fragaria EST database using our BLAST/FASTA server facility. References Altschul, S.F., Madden, T.L, Schaffer, A.A., Zhang, J., Miller, W., and Lipman, D.J. (1997). Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res. 25(17)3389-402. Review. Ewing, B., Hiller, L., Wendl, M. and Green, P. (1998). Basecalling of automated sequencee traces using phred. I. Accuracy assessment. Genome Research 8, 175185. Gordon, D. Abanjian, C., and Green, P. (1998). Consed: A graphical tool for sequence finishing. Genome Research 8, 195-202. Huan, X. and Madan, A. (1999). CAP3: A DNA sequence assembly program. Genome Research, 9, 868-877. Pearson, J.D. and Lipman, D.J. (1988). Improved tools for biological sequence comparison. Proceedings of the National Academy of Science, USA 85, Copyright © 2004 | Clemson University Genomics Institute. Last updated July 28, 2004.