Final Exam - The Joy of Stats
advertisement

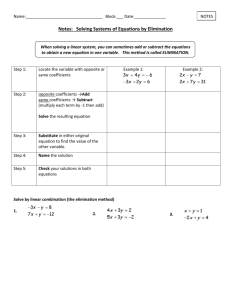
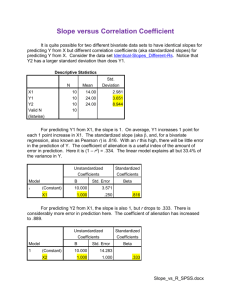
FINAL EXAM For each type of data analysis, 1) formulate a plausible question, 2) obtain the SPSS/PASW output needed to answer it, and 3) write an interpretation. Use the rubrics below as a checklist for your work. It is strongly suggested that, for each problem, you use an example that yielded significant results for the test. Attach the relevant output, and be sure it is clearly matched (labelled) with the corresponding interpretations. Each problem will be graded with the rubric indicated below. Problem 1: Crosstabs and Chi-Square Test (Use GSS or CANSIM data) Plausible well-stated question Variables selected measured at appropriate level(s) of measurement Table layout correct in terms of title and placement of the variables (matches your question) Correct percentaging Chi-square test result read correctly Conclusion stated correctly in terms of o Chi-square test result and null hypothesis (reject, fail to reject) o Percentage distributions discussed o Result stated accurately and clearly in “everyday language” o Result used to answer your initial question Two new questions suggested: o A question that introduces a third variable from the GSS or CANSIM data set that could be used as the “layer” variable to elaborate the data analysis you just completed o A broader question that is raised in a more general way by this result Note: For the last question you are being asked to relate this specific finding to a broader or more theoretical issue in the social and behavioural sciences. Your question should not be a technical or statistical one but one that reflects your intellectual curiosity about how and why we find the statistical patterning. For example, if we find that men are more likely than women to say they like action movies, what forces shape this difference? Are boys socialized differently than girls? Do men feel peer pressure to say they like action movies? Does their preference reflect biological factors? Your question should place the finding in a broader and more conceptual context. 1 Problem 2: One-Way ANOVA (Use either GSS or CANSIM data or the country data set. If you use the country data set, be especially careful to choose variables that are at the right level of measurement for ANOVA) Plausible and well-stated question Variables selected measured at the appropriate level(s) of measurement ANOVA output produced correctly, with descriptives and (if more than two groups) posthoc measures—e.g., Bonferroni ANOVA output interpreted correctly: o Is the result significant, and how do you know? o Which groups have significantly different means from which other groups? Result stated clearly in “everyday” language Broader or more theoretical question formulated, one that is stimulated by this finding Note: For the last question you are being asked to relate this specific finding to a broader or more theoretical issue in the social and behavioural sciences. Your question should not be a technical or statistical one; rather, it should reflect your intellectual curiosity about how and why one finds the statistical patterning you discuss in the “result” section of your answer to Problem Two. Problem 3: Bivariate Linear Regression (Use the country data set) Plausible and well-stated question Variables at the appropriate level(s) of measurement Scatterplot with total fit (OLS) line that is “roughly” linear Regression analysis, with brief comments on o The correlation coefficient (strength and direction) o R-squared o The unstandardized coefficients; write the equation of the line with the unstandardized coefficients o The standardized coefficient (beta) Overall result discussed, answering your initial question and commenting in “everyday language” in a way that shows that you understand the units of analysis (cases) are countries Problem 4: Multiple (Linear) Regression—Two Predictor Variables Plausible, well-stated question (Start with your Problem Three result.) Variables at the appropriate level(s) of measurement Correlation matrix showing correlation coefficients for each pair of variables Regression analysis output, with brief comments on o Adjusted R-squared o The unstandardized coefficients; write the equation of the line with the unstandardized coefficients 2 o The standardized coefficients (betas) The overall result, answering your initial question and commenting in “everyday language” showing that you understand the units of analysis (cases) are countries o What did you learn by adding a second predictor variable to your model? o Were both predictor variables significantly related to the outcome variable? A reflection on the following question: o Does this model provide any insights that could be used to improve well-being (or quality of life) for people? Problem 5: Fix This Data Analysis! Look carefully at the SPSS/PASW output on the next page and the interpretation (below) that was written for it. It is based on the GSS data set. The data analysis technique was chosen correctly, but it is incorrectly identified in the interpretation The variable names and values are correct The observed cell counts are correct, and the marginal counts are correct but not necessarily in the right locations The numbers that appear in the test of significance are correct But there are many problems in both the output and the interpretation! Your task is to repair the problems. You do not need SPSS/PASW or the GSS data set to do this; you can do it “manually.” 1. Fix the title and the layout (location of the variables in rows and columns) 2. Percentage correctly (Hint: To carry out steps 1 and 2 you will need to make a new table) 3. Rewrite each bullet point of interpretation, correcting all errors Interpretation The question for this data analysis is as follows: Does happiness cause sex? I selected ANOVA as my data analysis technique because both variables are measured at the interval-ratio level of measurement From the counts in the table, we can easily see that happy people are more likely to be men From the very high value of “Sig.” in the t-test result (.895), we can see that the results are highly significant We can reject the null hypothesis Conclusion: Happiness has a major effect on the sex of respondents, and happy people are more likely to be men 3 4 5