Open01
advertisement

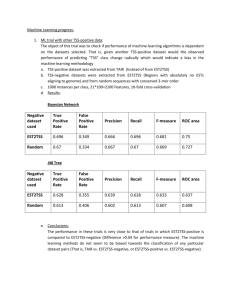
TUL6 Analysis for the Asian Telecommunications Provider Table of Contents Executive Summary ………………………………………………………………………3 Parameters used in SAS EM ………………………………………………………………5 Reviewing and Sampling …………………………………………………………..…..5 Data Partitioning, Variable Selection, Replacement, and Transformation ………………5 Modeling ………………………………………………………………………………6-10 Conclusion ………………………………………………………………………………11 Diagram of Data Flow……………………………………………………………………....12 2 Executive Summary Background An Asian telecommunication provider recently launched the first phase of a third generation (3G) mobile telecommunications network. The company now has both second generation (2G) and 3G subscribers. The company would like to use existing customer usage and demographic data to identify which 2G customers are most likely to upgrade or switch to the 3G technology. The sample dataset provided to the consulting firm has 20,000 2G network users and 4,000 3G network users with more than 200 data fields for each subscriber. Three quarters of the database (18,000 records of 15,000 2G and 3,000 3G) have target variable values available. These records should be used for training/validation/testing of models. The remaining 6,000 records presumably contain 5,000 2G and 1,000 3G customers. The target values are missing for this part of the database. The goal is to accurately predict as many 3G customers in the scoring database as possible. Methodology The process follows this sequence: data review and sampling, data partitioning, variable selection, modeling, and model evaluation and selection. The model selection process used charts to determine specificity, sensitivity, and accuracy (or misclassification). The original database was skewed toward 2G customers at the rate of 83.4% to 16.6% for 3G customers. To properly train the predictive models a sampling of the main database was created with equal numbers of 2G and 3G customers. This allowed the models to learn both 2G and 3G customer characteristics more effectively. This database was partitioned into training, validation and testing sub-sets so that each model “checks” its learning and assumptions. Each customer record contained over 250 variables. Several variable selections methods were used to reduce the number of variables: manual variable selection, decision tree variable selection and SAS variable selection. After thorough evaluation of each variable selection process, we selected the SAS variable selection tool because it provided better results with the models for this dataset. The 250 variables were narrowed down to 31 for use with the models. Three types of models were used to predict the 3G customers: Logistic Regression (LR), Decision Trees (DT) and Artificial Neural Networks (ANN). A fourth ensemble model was also used, which is a composite or combining of the individual models. Decision Trees consistently outperformed both Logistic Regression and Artificial Neural Networks in terms of “true positives” prediction (or sensitivity based on ROC chart) and misclassification rates. Both two node and multiple node decision trees were evaluated and tested with the three node decision trees yielding the better results. The Ensemble model, based on two Decision Trees (Gini and Entropy) provided even better accuracy than any one single decision tree. Each model was evaluated using several criteria: the ROC chart (a measure of sensitivity and specificity), Captured Response Rate and the Lift Chart. The DT model consistently performed better than Logistic Regression and Artificial Neural Networks in terms of misclassification rate and, more importantly, sensitivity. The Ensemble model comprised of two Decision Trees performed better in all of the measurements than these models did separately. Findings Consistent with the scope of the project, the Gini and Entropy Decision trees, combined in an ensemble model, more accurately predicted 3G customers within the original training, validation and testing data. ROC charts were used to evaluate sensitivity, misclassification rates were used as estimates of overall error rates, and cumulative and non-cumulative captured response charts provided general comparison of models’ performance. 3 Conclusion We recommend the use of an Ensemble Model, which combines two Decision Tree models (Gini and Entropy) to correctly predict which 2G customers will be most likely to upgrade or switch to the 3G technology. The management team and the marketing department of the Asian Telecommunication Company can use the developed model to proceed with costbenefit analysis. The final selection of a model depends on marketing budgets and management choice. The next recommended step would be project budgeting analysis based on suggested model data and using fixed, variable costs and profit per customer to find break-even point and profit/loss at different predicted 3G levels. 4 Parameters used in the SAS EM Seed ID: 12345 Number of observations used: complete dataset: 18,000 records Number of dataset variables: 250 Partitioning: 60% - training, 30% - validation, 10% - test SAS Enterprise Miner version 4.3 Modeling methods: Chi-Square 3-Node Decision Tree, Entropy Reduction 3-Node Decision Tree, Gini Reduction 3-Node Decision Tree, Logistic Regression, Multi-Layer Perceptron (MLP), Artificial Neural Network (ANN), Ensemble Model Reviewing and Sampling the Dataset The first order of business the group considered was the distribution of the target variable: Customer_Type (2G or 3G). The distribution of 2G customer types compared to 3G customer types was 15,000 records to 3,000 records in the training/testing dataset. The group further reduced the number of records used by creating a balanced dataset consisting of 3000 2G customers and 3000 3G customers. If this procedure was not completed, the dataset would have been biased towards predicting everybody as 2G customers. Data Partitioning, Variable Selection, Replacement, and Transformation The group’s next step was to split the sample into 3 datasets: Training, Validation, and Testing. The training dataset consisted of 60% of the data, validation dataset consisted of 30% of the data, and the testing dataset consisted of the final 10% of the data. The group felt this split would reduce the amount of overtraining in the dataset, and would provide a general idea of how well the models we were creating were performing. The group tried two methods of reducing the 251 variables which were included in the datasets being used to create the models. Numerous methods were employed in reducing the amount of information provided to the group: Manual Variable Selection, Decision Tree Variable Selection, and the SAS Variable Selection tool. The SAS variable selection tool was used to determine the variables used in the model because it provided the best results in the initial models created to study the dataset, and provided the user with a workable number of variables. Many of the variables were eliminated because they had a low correlation with the Target Variable, Customer_Type. The final set of variables used in the modeling is shown in Table One. Table One: Variable Selection Variable AGE MARITAL_STATUS CUSTOMER_CLASS LINE_TENURE HS_AGE HS_MODEL LUCKY_NO_FLAG LST_RETENTION_CAMP LOYALTY_POINTS_USAGE BLACK_LIST_FLAG VAS_CND_FLAG VAS_CNND_FLAG VAS_AR_FLAG AVG_DIS_1900 Variable AVG_CALL_MOB AVG_CALL_INTRAN AVG_CALL_T1 AVG_VAS_GAMES AVG_VAS_SR AVG_PK_CALL_RATIO AVG_OP_CALL_RATIO AVG_M2M_MINS_RATIO STD_BILL_SMS STD_T1_CALL_CON G_PAY_METD G_PAY_METD_PREV G_TOP1_INT_CD G_TOP2_INT_CD 5 AVG_USAGE_DAYS AVG_BILL_VOICED G_TOP3_INT_CD Replacement was not performed on the dataset, most of the variables were missing less than 5% of their values, and the only significant variable which was missing over 50% of its values, was excluded in the variable selection process. Transformation was performed on the remaining variables in the early stages of modeling. It was determined through testing many of the binning and normalization techniques did not yield improved results when modeled. Therefore, it was decided by the group to forgo the transformation process on final set of variables. Modeling Three basic models were run: Logistic Regression, Artificial Neural Network, and Decision Trees. The Logistic Regression and ANN models consistently performed worse than the three decision tree models even as measures were taken to try to improve their misclassification rates (predictive ability). Various parameters were changed in order to improve the accuracy of these models, for example, the number of hidden nodes in the ANN models. Random seed numbers were also changed to see the effect of this variable in our results and to make sure no local minimums/maximums were observed in the ANN model. One of the analyses we did amongst the early testing of decision trees was to determine if the maximum number of branches to a node affected our results substantially. From our testing we were able to ascertain the maximum of three branches per node yielded the best results. Once our group decided to pursue the maximum three branch route, we discovered the various Decision Trees yielded similar results, and we were able to improve their predictive rates when various parameters were manipulated. Through testing, the parameters used in the final model (an Ensemble Model of the Entropy Reduction and Gini Reduction models) were completed. The parameters used in the decision trees are shown below in Table Two. Table Two: Decision Tree Criteria Table Three shows a comparison of the six main models and how they predicted which 2G customers who would switch to 3G. The prediction across training, validation, testing data is fairly stable indicating there was little overfitting of the models. The Decision Trees consistently performed five to ten percent better in predicting the 3G customers than the Logistic Regression and ANN models. The four models utilizing Decision Trees were consistently around the twenty percent misclassification rate and they performed better in the ROC chart (specificity and sensitivity). When creating the Ensemble model, the individual models were grouped together in 6 various combinations to determine if any benefit was achieved through their coupling or staging. Based on these observations, our group used the combination of two Decision Tree models: Entropy Reduction and Gini Reduction to improve the results. Consequentially, we found that the combination of these two models provided a better overall result than each of the models created individually in terms of high accuracy, sensitivity, specificity, and misclassification rate across all three datasets. Table Three: Model Comparison In the case of our group, we used multiple criteria to help us formulate which the “best model”. The ROC chart (shown in Table Four below) was the basis for determining which of the models performed best. Table Four: ROC Chart When viewing this chart, it is important to remember the greater the slope of the curve when going from left to right, the more sensitive the model. In our case, the individual Decision Tree models, and the Ensemble models clearly outperform the Regression and Neural Network 7 models. If judging on this criterion solely, we would choose the Ensemble model as the best performer. Another criterion we compared our models against was the Capture Response Rate shown in Table Five. Once again the different Decision Tree models and Ensemble models clearly outperformed the Regression and ANN models. The larger the space between the model and the baseline, the greater the Captured Response Rate indicates the model(s) are performing better than average. For the Asian Telecommunications company, the goal is to correctly predict the 3G consumers in the Scoring dataset. Therefore, this graph must be used with great caution, with the reminder this is for the classification of 2G and 3G, not 3G solely. Table Five: % Captured Response A third criterion to consider for selecting the correct model is to look at the Lift Chart as shown in Table Six. 8 Table 6: Lift Chart Values When viewing this chart, look for the point at which the individual Model Lift Value lines cross the threshold of 1. At this point, the user can not obtain any significant lift in the model. In the case of these models, the Regression and ANN model cross the baseline at a greater percentile than the Decision Tree and Ensemble models. It is at the client’s discretion as to whether this can be considered important. If the client only targets the top 30 percentile of its consumer, then the models need to be judged at this percentile mark. In our case, we took this into consideration, but felt this criterion would not greatly influence our decision of which of the models to use. Using this criterion as the sole determinant for a successful model would end in disappointment. When interpreted in conjunction with the Captured Response chart in Table 9 Five it becomes clears the Decision Trees are more effective at predicting whether the customer will become a 3G user. As you can see in the classification matrix in the above Table, the Ensemble model was quite successful at predicting which category a customer would fall into. It excelled at predicting the 2G customers, and did quite well at classifying the 3G customers. The Ensemble was a relatively low rate of predicting 2G customers who actually became 3G customers. Table 7: Classification Matrix 10 Conclusion Using the various Analysis tools which SAS Enterprise Miner offers, we determined the Ensemble Model, consisting of the Entropy and Gini Regression models, performed the best for this particular business dataset and problem. We came to this conclusion by amalgamating various criteria such as sensitivity, specificity, misclassification, and captured response. Based on the management decision making process, each of these criteria can become the most important determining factor in deciding which model or models to use. 11 Diagram of dataflow: 12