11:6 Performing ANCOVA in JMP.
advertisement

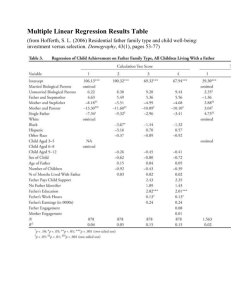
Lecture outline AGR 206 Revised: 2/12/2016 Chapter 11: Analysis of Covariance 11:1 What is ANCOVA: Analysis of covariance is a method to determine if treatment differences are significant after correcting for the effects of a covariate. It is like a multiple linear regression except that one of the variables is discrete (the treatment) and that we arbitrarily or based on a priori reasons, assign all variance in the response variable (Y) that is explained both by treatment and covariate, to the covariate. More formally, ANCOVA can be applied when the response variable is continuous and we have one or more discrete explanatory variables and one or more continuous explanatory variables. Typically the main purpose of the analysis is to determine if there are treatment or group differences. 11:1.1 One continuous Y variable. One or more continuous X variables (covariates). One or more class variables (treatments). Model: There are two versions of the ANCOVA model, the first expresses the response variable as an overall mean plus deviations due to treatment and covariate effects, and the second expresses it as treatment means plus deviations due to the covariate. Both models include a term for treatment effects or treatment means and an effect of the covariate. The treatment means or effects can have any structure (factorial, etc.). Additional terms can be added to the model to account for different experimental design structures (blocks, split-plot, etc.) The model presented here assumes that the experiment was a completely randomized one. When expressed as a regression model, it is easy to see that the model is the same as that seen for homework 2 with the assumption that the slopes are the same across treatments, where the ln of weight of plants was studied as a function of a temperature treatment and age. This should be no surprise by now, as we found out that all or most of the ANOVA’s, ANCOVA’s, and other linear models are actually special cases of multiple linear regression. All elements of ANCOVA were explored in HW02 with the clover growth example. Therefore, the student can use all the concepts learned in that homework for ANCOVA. The main difference between the clover example and the present approach to ANCOVA is that the main question in the clover problem was “Is there a temperature effect on the relative growth rate (RGR) of clover?” Because relative growth rate is the slope of the line relating the ln of weight to plant age, the question was answered by testing for differences in slope. In the present ANCOVA approach, the main question is “Are there temperature effects on the size of plants after correcting for age differences?” For this analysis, is necessary to make sure that slopes are not different among treatments, which amounts to test whether the RGR’s are different. 1 Lecture outline AGR 206 Revised: 2/12/2016 Y .. j X X or Y j X X Note that the model can be expressed as a general regression model: Y .. j X X .. j X X .. X j X 0 0 j X where .. is the overall mean of the response Y; j is the effect of treatment j on Y; is the effect of the X on Y, or the overall slope; X is the overall mean of the covariate; 0 is the overall intercept, equal to the overall mean of Y minus the increase in Y due to the effect of X going from 0 to X; and 0 j is the effect of treatment j on the intercept. 11:2 Uses of ANCOVA There are three main types of situations or goals where ANCOVA is useful: 1. Increase sensitivity of the analysis to detect treatment differences by removing, from the error term, variability associated with the covariate. 2. Adjust treatment means to what they would be if all were at the same average value of X, thus “equalizing” comparisons. 3. Determine if treatments have any “direct” effect on a primary response variable after correcting for the “indirect” effects through a secondary response variable. This type of analysis is used in MANOVA to determine the relative importance of each response variable in generating multivariate differences among groups. Example of uses 1 & 2: This is the typical use of ANCOVA. In any research concerned with the assessment of treatment effects on growth or size it is a good idea to incorporate the initial size of the individuals or units as a covariate. One should expect that both the final size and the total growth in a given period will be affected by the size of the units, regardless of treatment. Thus, by using initial size as covariate the effect of size is removed from the error term and increases the precision of the comparison. In addition, the comparison of treatments is corrected for potential differences in average initial size among treatments. For example, one may be interested in determining is weigh gain by black-footed ferrets grown in captivity is affected by the type of “prey” offered, mature and immature prairie dogs. Several individual ferrets are assigned randomly to each treatment. Their weights before the experiment is recorded. Then they are exposed to the treatments for 2 weeks and their weight is recorded again. The response variable is the weight difference, and the initial weight is used as covariate. The ANCOVA corrects the treatment means to the values they would have is the initial weight had been the same in all ferrets. Example of use 3: In this case, the requirement that the covariate not be affected by the treatments is relaxed, because a secondary response variable is used as covariate. A scientist is studying the effect of P fertilization on the vitamin C concentration in cabbage. She applied a series of P treatments to a series of experimental plots and then measured the weight and vitamin C concentration of the cabbage heads. The production of vitamin C can change due to increased fertilization, but the observed effects on concentration may be reduced because head weight can also respond to fertilization, and other things being equal, larger heads will tend to have a lower concentration of vitamin C. The main question in the study is, “Does fertilization affect vitamin C concentration after we correct for the indirect effects through head weight?” A hypothetical case 2 Lecture outline AGR 206 Revised: 2/12/2016 (fictitious data) is depicted in the following figure, where concentration of vitamin C is plotted against head weight and the labels refer to the level of P fertilization. If the data are analyzed as a function of treatment, ignoring the secondary response variable hdwt, there is an apparent negative effect of fertilization on concentration of vitamin C. However, when the secondary variable is used as a covariate, it is clear that there is a direct effect of fertilization that tends to increase vitamin C concentration, if the effects of fertilization on head weight are controlled for statistically. The conclusion is that if it were possible to prevent head weight to increase due to fertilization, then it would be possible to boost the concentration of vitamin C by applying fertilizer. 3 Lecture outline AGR 206 Revised: 2/12/2016 Note that this third use of ANCOVA is not the typical one, and it should be applied with caution and a critical understanding of the situation. Mora than testing for difference among treatments, this application is to reveal the patterns of effects in a complex response. This is the reason why in this type of use the assumption that treatments not affect the covariate is relaxed, and the covariate is called “secondary response variable.” 11:3 Assumptions. Because ANCOVA is combination of regression and ANOVA, it has all of the assumptions of both methods. These assumptions are the typical ones, and are listed below. In addition to the common assumptions, there is an assumption of homogeneity of slopes. 11:3.1 1. Normal, independent and equal-variance errors. 2. X is not affected by treatments (only for uses 1 and 2). 3. Relationship between Y and X’s does not need to be linear. 4. Homogeneity of slopes. The model that relates Y to X’s must be the same for all groups (except for intercept). Normality and independence of errors. Residuals have to be tested for normality as usual. In JMP this involves saving the residuals and applying a Fit Distribution, Normal, Goodness of fit test in the Distributions platform. If normality is rejected, transformations of the Y variable should be tried. As usual in linear statistics, the method and results are robust against small departures from normality. Independence of errors can be tested if the spatial location or sequential order of the measurements is known. Plot the residuals against spatial or temporal order. Any trends that seem to depart from a random scatter of points about zero indicates autocorrelation. Alternatively, plot each residual against the previous one or the one next to it in space. Again, lack of independence is indicated by a scatter that shows a trend. 11:3.2 Homogeneity of variance. The variance of the residuals should be the same across treatment groups and over all the range of the covariates. To test for this, perform a test of UnEqual Variances using the Fit Y by X platform and using the residuals as the response (Y) variable and group or treatment as the explanatory variable. A significant result indicates that homogeneity of variance is rejected and that remedial measures are necessary. Try transformations of the Y variable, and if that does not work, use weighted regression procedures or resampling. 11:3.3 No effect of treatments on covariate. This assumption is applied only when the covariance analysis is used to test for treatment differences after “equalizing” or correcting the responses by the covariate. The idea is to look for differences in the “height” of the 4 Lecture outline AGR 206 Revised: 2/12/2016 lines that relate Y to the covariate within each treatment. If the treatment has an effect on the covariate, then it is possible that the effects of treatment and covariate will be highly correlated and it would make no sense to try to separate them. For example, if we apply P fertilization doses as treatments, and we measure P level in the soil at the end of the experiment, any potential effects of the applied fertilizer will be explained by and assigned to the level of P in the soil, and not treatment differences will be detected. Analogously, even if we measure the soil level of P prior to application of the treatments and then apply high level of fertilization to those plots that have high original level of P, we will never know if the difference in yield was due to the fertilizer or to the soil. In ANCOVA , any variance of the response that is explained both by treatments and covariate is assigned to the covariate. 11:3.4 Linearity of covariate effect. Although a linear relationship between the covariate and the response is assumed or imposed, it is not necessary to restrict ANCOVA to linear effects. Any model that is linear in the parameters can be used, such a quadratic effect of the covariate. In addition, it is possible to use truly nonlinear relationships between response and covariate. These applications are more advanced and beyond the present discussion, but they are quite accessible through JMP, by using the nonlinear fitting platform. If the data set contains replicates, i.e., more than one observation with the same value of all explanatory factors, a lack of fit test is possible. JMP will print the lack of fit test automatically. If this test is significant, the model that relates response to covariate is rejected and a better model has to be used. 11:3.5 Homogeneity of slopes. ANCOVA assumes that the slopes that relate Y to X are the same for all treatment groups. This is an unusual assumption in the sense that no probabilistic or statistical principles would be violated if slopes differ among groups. It’s just that the interpretation of the whole situation would become tenuous. Keep in mind that the main reason for using ANCOVA is to determine if treatments are different. If it is found that slopes are different one cannot proceed with the ANCOVA. On the other hand, one can immediately say that the treatments are different … in the way they respond to the covariate. Form another point of view, the heterogeneity of slopes represents an interaction between the covariate and treatments. The situation is exactly the same as the one when you have a factorial combination of treatments and there is a significant interaction between the two factors. When the interaction is significant, no general statements can be made about the simple effects, because the effects of one factor depend on the level of the other factor at which the means are compared. Following the basic concept of statistical interaction, in ANCOVA this means that whether treatments differ in the response depends on the value or range of values of the covariate at which they are compared. It is still possible to correct observations from different treatments with different slopes and get “corrected” treatment means, but this may not have much meaning outside the sample being considered. In a different experiment or sample, the range of the covariate may be such that the treatment differences detected with the first sample are reversed. 5 Lecture outline AGR 206 Revised: 2/12/2016 Example of a significant interaction. The question “Is yield higher with high water availability?” cannot be answered in a general way. Main effects have weaker meaning. One has to state: “The effect of water depends on the amount of N applied.” Or, “The effect of nitrogen fertilization depends on water availability.” When the lines are parallel (i.e., there is no interaction) then the distance between them is the same regardless of the level of nitrogen or of the value of the covariate, in a ANCOVA case. Thus, when lines are parallel, we can make general statements about the treatment effects after correcting for the covariate. 11:4 How ANCOVA works. Consider the cracker sales example from Neter et al., (1996). For this example, use the xmplcrackers.jmp file. The example is about testing for effects of displays on the sales of crackers. Sales prior to the application of the treatments is used as the covariate. When the treatment effects are tested without considering the covariate, we find that treatment 3 differs from 1 and 2, but 1 is not different from 2. 6 Lecture outline AGR 206 Revised: 2/12/2016 A scatter plot of sales post against sales pre shows that a lot of the variation within treatments can be explained by the covariate. In the prior analysis, that variability within treatments went into the error term. In addition, it can be seen that the average value of the covariate is not exactly the same for all treatments. By using the covariance model above, each value of sales post is partitioned into a treatment average (trt lsm), effect of sales pre (pre sales FX), and residual (R. sales post). A “corrected” value of sales post (C. Sales post) can be obtained by subtracting the sales pre effects column from the sales post. This correction amounts to moving each observation up or down on a regression line with the same slope for all observations, until they are all projected on the vertical line that passes through the average sales pre. 7 Lecture outline AGR 206 Revised: 2/12/2016 The correction reduces the variability within treatments and adjusts all observations to what they would have been if the value of the covariate had been equal to 25 for all stores. When performing the analysis, the correction is performed simultaneously with the whole model fitting and testing for difference in least square means. 45 40 sales post 35 30 25 20 15 20 25 sales pre 30 35 The application of the correction significantly reduces the SSE and increases the power for detecting treatment differences. After correction for the covariate, all treatments are significantly different from each other. 8 Lecture outline AGR 206 Revised: 2/12/2016 11:5 Least squares means. In this section I introduce the concept of least squares means and explain how they are used in general and in specific for ANCOVA. Least square means are the expected values of class (group) or subclass means when the design is balanced and all covariates are set at their average values. Least squares means are predicted values, based on the model fitted, across vales of a categorical effect where the other model factors are controlled by being set at a neutral value. The neutral value is the average effects of other nominal effects and the sample averages for the covariates. LSMeans are also called adjusted or population marginal means. In ANCOVA, the LSMeans are adjusted for the effects of the covariate. They reflect the value that treatment means are expected to have if all observations in the sample have the same value of the covariate, equal to the mean value in the present sample. In general terms, lsmeans are the means that are compares in statistical tests of effects. They correct for impacts of differences in sample size within each combination of the categorical variables, i.e., they correct for differences in “cell” sizes. A cell is the set of all observations that have the same values for all categorical explanatory variables. For example, in a 2x2 factorial in a block design with 3 replications there are 12 cells. Consider the following example to see the impact of using lsmeans and the difference between lsmeans and regular means. A 2x2 factorial is conducted in a completely randomized design. The true model used for simulating the data includes an effect of 1 for factor A and an effect of 2 for factor B. The interaction is 0. The table represents the number of observations in each cell. The combination A 2B2 was observed many more times than the other cells. 9 Lecture outline AGR 206 Revised: 2/12/2016 Because of the different cell sizes, the two factors are not completely orthogonal. The result is that by looking at the regular marginal means for each factor, the different cell sizes bias the estimated effects. For example, the effect of levels of factor A appears to be 4.5-1.7=2.8 because the observations at level A2 are disproportionately weighted in level B2. the lsmeans avoid this problem and correctly estimate the true effect of A being at about 0.9 11:6 Performing ANCOVA in JMP. Performing an ANCOVA in JMP is very easy. The steps are as follows: 1. Perform an analysis in which the interaction of covariate with treatments is included. 2. Save the residuals and conduct a complete test of assumptions that concern the distribution of errors, as well as lack of fit of the model. If there are replicates that allow a test of lack of fit, JMP will automatically provide the relevant output. 3. In the output, check that the interaction between covariate and treatments is not significant. If the interaction is significant, the homogeneity of slopes is rejected and the analysis is finished. The interpretation is that whether treatments differ or not depends on the value of the covariate at which they are compared. If desired, comparisons can be made at values of the covariate that are meaningful for the situation. 4. Remove the interaction term from the model and run the analysis again. 5. In the output, determine if the treatment effect is significant according to the F test. 6. If the treatment is significant, proceed to perform a priori contrasts among lsmeans, or to separation of means by the method of your choice. JMP offers quick access to the Tukey’s HSD. The analysis of the cracker example is detailed below. 10 Lecture outline AGR 206 Revised: 2/12/2016 Interaction is not significant indicating that homogeneity of slopes is not rejected. 11 Lecture outline AGR 206 Revised: 2/12/2016 This is the common slope used for the correction in all groups. Both treatment and covariate have significant effects based on type III SS. Click here to obtain Tukey’s HSD. Means differ from lsmeans due to correction for covariate effect. Based on Tukey’s HSD, all treatments differ from each other. Each cell of the table contains the value, std err and CI for the difference. If the difference is significant the numbers are red, otherwise they are black. 12