Identifying speech acts in emails
advertisement

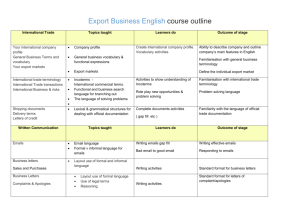
Identifying speech acts in emails: Business English and non-native speakers In this work, we present an approach to the automated identification of speech acts in a corpus of workplace emails. As well as contributing to ongoing research in automated processing of emails for task identification (see e.g. (Cohen, Carvalho et al. 2004; Carvalho and Cohen 2006; Lampert, Dale et al. 2006; Lampert, Dale et al. 2008; Mildinhall and Noyes 2008)), the main goal of this work is to determine whether learners of English are using the appropriate structures for this type of text. In particular, tests of English for the business environment often require learners to write emails responding to specific task requirements, such as asking for information, or agreeing to a proposal, which can be assigned to basic speech act categories. Automated identification of such items can be used in the scoring of these open-content answers, for example noting whether all the speech acts required by the task are present in the students’ texts. To achieve this goal, we are working with a corpus of over 1000 such emails written by L2 English students in response to a test prompt. Each email is manually annotated at the sentence level for a speech act, using a scheme adapted from the Verbal Response Mode framework (Stiles 1992). This includes categories such as Acknowledgement, Question, Advisement (requesting the recipient do something), Disclosure (of personal thoughts or intentions), and Edification (stating objective information). We then identify a set of features designed to discriminate among the categories. Similar methods have been proven to be successful in acquiring usage patterns for lexical items such as prepositions and determiners (De Felice and Pulman 2008; Gamon, Gao et al. 2008; Tetreault and Chodorow 2008); one of the novel aspects of this work is to extend the classifier approach to aspects of the text above the lexical level. The features refer to several aspects of the sentence: punctuation, use of pronouns, use of modal verbs, presence of particular lexical items, and so on. A machine learning classifier is trained to associate particular combinations of features to a given speech act category, to automatically assign a speech act label to novel sentences. The success of this approach is tested by using ten-fold cross-validation on the L2 email set. Experiments are still ongoing, but full results will be ready by the time of the conference. To establish whether this method is specific to L2 texts, or can also be applied to L1 texts in a similar domain, we also intend to assess the performance of this classifier on L1 data, specifically a subset of the freely available Enron email corpus (Klimt and Yang 2004). Our work combines methods from corpus linguistics and natural language processing to offer new perspectives on both speech act identification in emails and the wider domain of automated scoring of open-content answers. Additionally, analysis of the annotated learner data can offer further insights into the lexicon and phraseology used by L2 English writers in this text type. References: Carvalho, V. and W. Cohen (2006). Improving email speech act analysis via n-gram selection. HLT-NAACL ACTS Workshop. New York City. Cohen, W., V. Carvalho, et al. (2004). Learning to classify email into "speech acts". EMNLP. Barcelona, Spain. De Felice, R. and S. Pulman (2008). A classifier-based approach to preposition and determiner error correction in L2 English. COLING. Manchester, UK. Gamon, M., J. Gao, et al. (2008). Using contextual speller techniques and language modeling for ESL error correction. IJCNLP. Klimt, B. and Y. Yang (2004). The Enron corpus: a new dataset for email classification research. European Conference on Machine Learning (ECML): 217-226. Lampert, A., R. Dale, et al. (2006). Classifying speech acts using verbal response modes. Australasian Language Technology Workshop (ALTW). Sydney, Australia: 3441. Lampert, A., R. Dale, et al. (2008). The nature of requests and commitments in email messages. AAAI Workshop on Enhanced Messaging. Chicago, USA: 42-47. Mildinhall, J. and J. Noyes (2008). Toward a stochastic speech act model of email behavior. Conference on Email and Anti-Spam (CEAS). Stiles, W. (1992). Describing Talk: a taxonomy of verbal response modes. Thousand Oaks, CA, Sage. Tetreault, J. and M. Chodorow (2008). The ups and downs of preposition error detection. COLING. Manchester, UK.