Lecture1
advertisement

What is Data Mining about?
Basic Introduction
Main Tasks in DM
Applications of DM
Relations to other disciplines
Machine Learning: Supervised and
unsupervised learning
Concepts, Concept Space…
Reading material:
Chapter 1 of the textbook by Witten,
Chapters 1, 2 of Textbook by T.
Mitchell,
Chapter 1 of the book by Han.
Data vs. information
—Huge amount of data from sports,
business, science, medicine,
conomics. Kb,Mb,Gb,Tb, Lb…
Data: recorded facts
Information: patterns underlying the data.
—Raw data is not helpful
—How to extract patterns from raw data?
Example:
—Marketing companies use historical
response data to build models to predict
who will respond to a direct mail or
telephone solicitation.
—The government agency sifts through the
records of financial transactions to detect
money laundering or drug smuggling.
—Diagnosis, building expert systems to
help physicians based on the previous
experience
Data Mining = KDD:
— Knowledge Discovery in Database
System: extensive works in database
system,
— Statistical learning has been being
active for decades.
— Machine Learning: a mature
subfield in Artificial Intelligence.
Data Mining is
Extraction of implicit, previously unknown, and
potentially useful information from data;
— Needed: programs that detect patterns
and regularities in the data;
— Strong patterns can be used to make
predictions.
Problems:
— Most patterns are not interesting;
— Patterns may be inexact (or even
completely spurious) if data is garbled or
missing.
Machine learning techniques
— Algorithms for acquiring structural
descriptions from examples
— Structural descriptions represent
patterns explicitly
Machine Learning Methods can be used to
— predict outcome in new situation;
— understand and explain how prediction
is derived (maybe even more important).
Can machines really learn?
— Definitions of “learning” from dictionary:
To get knowledge of by study, experience, or
being taught; To commit to memory; To receive
instruction…
How to measure this `learning’? The last two
tasks are easy for computers.
— Operational definition:
Things learn when they change their behavior in
a way that makes them perform better in the
future.
Does a slipper learn?
Does learning imply intention?
Definition: A computer program is
said to learn from experience E with
respect some class of tasks T and
perfomance P, if its performance at
tasks in T, as measured by P,
improves with experience E.
Designing a learning system:
Example: A checkers learning problem:
Task T: Playing Checkers;
Performance measure P: percent of games
won against opponents;
Training experience E: playing practice
games against itself.
A Learning system includes:
— Choosing the training Experience
1. Whether the training experience provides direct or
indirect feedback regarding the choices made by
performance system.
2. To which degree the learner can control the
sequence of training examples.
3. How well the training experience represents the
distribution of examples of the final system
performance P must be measured.
— Choosing the target function
Determine which kind of knowledge will be learned
and how this will be used by the performance
program.
A Data Mining Process consists of:
— Choosing a representation for the target
function
— Choosing a learning algorithm
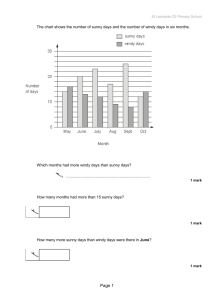
The weather problem
— Conditions for playing an unspecified
game
Play
Yes
Yes
No
No
Yes
……
Windy
False
False
True
False
True
……
Humidity
Normal
High
High
High
Normal
……
Temperature
Mild
Hot
Hot
Hot
Cool
……
Outlook
Rainy
Overcast
Sunny
Sunny
Overcast
……
Structural Description:
If---Then Structure:
If outlook = sunny and humidity = high then play
= no
Classification vs. association rules
— Classification rule: predicts value of prespecified attribute (the classification of an
example)
If outlook = rainy and windy = true then play = no
If outlook = overcast then play = yes
— Association rule: predicts value of
arbitrary attribute or combination of
attributes
If outlook = sunny and humidity = high then
play = no
If temperature = cool then humidity = normal
If humidity = normal and windy = false then
play = yes
Enumerating the version space:
Domain space: All possible combinations of
the examples, equals to the product of the
number of possible values for each
attribute. For the weather problem,
3*3*2*2=36. (`Play’ is the target attribute).
How many possible classification rules?
— If some attributes do not appear in the
if…then structure, we use `?’ to denote the
value of the corresponding attribute.
For example, (?,mild, normal,?, play) means
If the temperature = mild and humidity = normal,
then play=yes.
Therefore, the concept space is: 4*4*3*3*2=288
Space of rules set: approximately 2.7*10^27
Version space is the space of consistent
concept with respect to the present training
set.
Weather data with mixed
attributes
— Two attributes with numeric values
Play
Yes
Yes
No
No
Yes
……
Windy
False
False
True
False
True
……
Humidity
85
90
86
80
95
……
Temperature
85
80
83
75
65
……
Outlook
Rainy
Overcast
Sunny
Sunny
Overcast
Classification Rules:
If outlook = rainy and windy = true then play = no
If outlook = overcast then play = yes
If humidity < 85 then play = yes
If none of the above then play = yes
Question: How to count the version space
and concept space? How to add test in the
classification rule?
The contact lenses data
Age
Spectacle prescription Astigmatism Tear production rate Recommended lenses
Prepresbyopic
Hypermetrope
Yes
Reduced
None
Prepresbyopic
Hypermetrope
Yes
Normal
None
Presbyopic
Myope
No
Reduced
None
Presbyopic
Myope
No
Normal
None
Presbyopic
Myope
Yes
Reduced
None
Presbyopic
Myope
Yes
Normal
Hard
Presbyopic
Hypermetrope
No
Reduced
None
Presbyopic
Hypermetrope
No
Normal
Soft
Presbyopic
Hypermetrope
Yes
Reduced
None
Presbyopic
Hypermetrope
Yes
Normal
None
Prepresbyopic
Hypermetrope
No
Normal
Soft
Prepresbyopic
Hypermetrope
No
Reduced
None
Prepresbyopic
Myope
Yes
Normal
Hard
Prepresbyopic
Myope
Yes
Reduced
None
Prepresbyopic
Myope
No
Normal
Soft
Prepresbyopic
Myope
No
Reduced
None
Young
Hypermetrope
Yes
Normal
Hard
Young
Hypermetrope
Yes
Reduced
None
Young
Hypermetrope
No
Normal
Soft
Young
Hypermetrope
No
Reduced
None
Young
Myope
Yes
Normal
Hard
Young
Myope
Yes
Reduced
None
Young
Myope
No
Normal
Soft
Young
Myope
No
Reduced
None
Issues: Instances with little difference might
have the same value for the target attribute.
A complete and correct rule set
If tear production rate = reduced then
recommendation = none
If age = young and astigmatic = no and tear production rate
= normal then recommendation = soft
If age = pre- presbyopic and astigmatic = no and tear
production rate = normal then recommendation = soft
If age = presbyopic and spectacle prescription = myope and
astigmatic = no then recommendation = none
If spectacle prescription = hypermetrope and astigmatic = no
and tear production rate = normal
then recommendation = soft
If spectacle prescription = myope and astigmatic = yes and
tear production rate = normal then
recommendation = hard
If age young and astigmatic = yes and tear production rate =
normal then recommendation = hard
If age = pre- presbyopic and spectacle prescription =
hypermetrope and astigmatic = yes then
recommendation = none
If age = presbyopic and spectacle prescription =
hypermetrope and astigmatic = yes
then recommendation = none
In total, we have 9 rules. Can we
summarize the patterns more efficiently?
Classifying iris flowers
Sepal length Sepal width
5.1
3.5
4.9
3.0
7.0
3.2
6.4
3.2
6.3
3.3
5.8
2.7
……
Petal length
1.4
1.4
4.7
4.5
6.0
5.1
Petal width
0.2
0.2
1.4
1.5
2.5
1.9
Type
Setosa
Setosa
Versicolor
Versicolor
Virginica
Virginica
If petal length < 2.45 then Iris
setosa
If sepal width < 2.10 then Iris
versicolor...
Predicting CPU performance
Cycle time(ns) Main memory(kb) Cache Channels Performance
MYCT
Mmin Mmax
Cach Chmin Chmax PRP
125
256 6000
256
16
128
198
29
8000 32000
32
8
32
269
480
512
8000
32
0
0
67
480
1000 4000
0
0
0
45
……
PRP = -55.9 + 0.0489 MYCT + 0.0153
MMIN + 0.0056 MMAX + 0.6410 CACH 0. 2700 CHMIN + 1.480 CHMAX
Examples: 209 different computer configurations.
Using Linear regression function
Data from labor negotiations
— A case with missing values
Attribute
Type
1
2
Duration
{number of years} 1
2
Wage raise first year
Percentage%
2
4
Wage raise second year Percentage%
?
5
Wage raise third year
Percentage%
?
?
Living cost adjustment
{none,tcf,tc}
none tcf
Working time per week {Hours}
25
35
Pension
{none,ret-allw,empl-cntr} none ?
Standby pay
Percentage%
?
13
Shift supplement
Percentage%
?
5
Education allowance
{yes,no}
yes
?
Statutory holidays
number of days 11
15
Vacation
{below,avg,gen}
avg gen
Long-term disability assist {yes,no}
no
?
Dental plan
{none,half,full} none ?
Bereavement assist
{yes,no}
no
?
Health plan contribution
{none,half,full} none ?
Acceptability of contract {good,bad}
bad good
3 …
3
4.3
4.4
?
?
38
?
?
4
?
12
gen
?
full
?
full
good
Why have these values been missed and
how to estimate these missing values?
40
2
4.5
4
?
none
40
?
?
4
?
12
avg
yes
full
yes
half
good
Soybean classification
Attribute
Number of values Sample value
Environment Time of Occurrence
7
July
Precipitation
3
Above normal
Seed
Condition
2
Normal
Mold growth
2
Absent
Fruit
Condition of fruit pods
4
Normal
Fruit spots
5
?
Leaves
Condition
2
Abnormal
Leaf spot size
3
?
Stem
Condition
2
Abnormal
Stem Lodging
2
Yes
Root
Condition
3
Normal
Diagnosis
19 Diaporthe stem canker
Domain knowledge plays an important role.
If leaf condition is normal and
stem condition is abnormal and
stem cankers is below soil line and
canker lesion color is brown
then diagnosis is rhizoctonia root rot
If leaf malformation is absent and
stem condition is abnormal and
stem cankers is below soil line and
canker lesion color is brown
then diagnosis is rhizoctonia root rot
Data Mining Applications:
Processing loan application
— Given: questionnaire with financial and
personal information
— Problem: should money be lent?
— Simple statistical method covers 90% of
cases
— Borderline cases referred to loan officers
— But: 50% of accepted borderline cases
defaulted!
— Solution(?): reject all borderline cases
No! Borderline cases are most active customers
Enter machine learning
— 1000 training examples of borderline cases
— 20 attributes: age, years with current
employer, years at current address, years with
the bank, other credit cards possessed…
— Learned rules predicted 2/ 3 of borderline
cases correctly: a big deal in business.
— Rules could be used to explain decisions to
customers
More Applications: Screening images,
Load forecasting, Diagnosis of Machine
fault, Marketing and sales, DNA recognition,
etc…
Inductive Learning: finding a concept
that fits the data.
Let us recall the weather problem. It is
possible that the target attribute `play=no’
no matter what are the values of the other
attributes. We use the symbol `’ to denote
this situation or equivalently (,,,,) in
the concept space.
General-to-specific ordering:
Two descriptions:
— d1=(sunny,?,?,hot,?), d2=(sunny,?,?,?,?).
Consider the sets s1, s2 of instances
classified positive by d1 and d2. Because d2
poses fewer constraints on the instances, s1
is a subset of s2. Correspondingly, we use
the symbol d1<d2. This yields an order of the
components in the version space.
Finding max-general description:
It is possible that there is no `<’ or `>’ relation
between two general descriptions. For a specific
description d, if there is no other description d’ in
a set S of examples satisfying d’>d, then we say
d is the maximally general in S.
We can similarly define the maximally specific
(or minimally general) description in S
We can use intuitive greedy algorithm to find
a max-general description in S based on the
general-to-specific (or its converse) ordering
search in the concept space.
The space of consistent concept descriptions is
completely determined by two sets
L: most specific descriptions that cover all
positive examples and no negative ones
G: most general descriptions that do not cover
any negative examples and all positive ones
— Only L and G need to be maintained and
updated
Candidate- elimination algorithm
Initialize L () and G (?)
For each example e
If e is positive:
Delete all elements from G that do not cover e
For each element r in L that does not cover e:
Replace r by all of its most specific
generalizations that cover e and that are
more specific than some element in G
Remove elements from L that are more general
than some other element in L
If e is negative:
Delete all elements from L that cover e
For each element r in G that covers e:
Replace r by all of its most general
specializations that do not cover e and that
are more general than some element in L
Remove elements from G that are more specific
than some other element in G
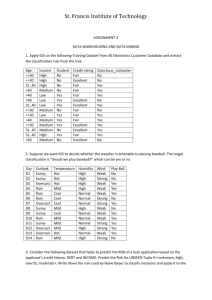
Example of Candidate Elimination:
Play
Yes
Yes
No
Yes
Windy
T
T
F
T
Humidity
Normal
High
High
Normal
Temperature
Hot
Hot
Cold
Cold
Outlook
Sunny
Sunny
Rainy
Sunny
L(0)={ (,,,)} L(1)={(sunny,hot,normal,t)}
L(2)={(sunny,hot,?,T)} L(3)=L(2)
L(4)={(sunny,?,?,T)} L(0)<L(1)<L(2)=L(3)<L(4)=L
G(0)={(?,?,?,?)} G(1)=G(0) G(2)=G(1)
G(3)={(sunny,?,?,?), (?,hot,?,?),(?,?,?,T)}
G(4)={(sunny,?,?,?),(?,?,?,T)}=G
Bias: important decisions in learning systems:
The concept description language
The order in which the space is searched
The way that overfitting to the particular
training data is avoided
— These properties form the “bias” of the
search: Language bias,Search bias
and Overfitting- avoidance bias
Language bias
— Most important question: is language
universal or does it restrict what can be
learned?
— Universal language can express arbitrary
subsets of examples
— If language can represent statements
involving logical or (“ disjunctions”) it is
universal
— Example: rule sets
— Domain knowledge can be used to
exclude some concept descriptions
a priori from the search
Search bias
— Search heuristic “Greedy” search:
performing the best single step
“Beam search”: keeping several
alternatives …
— Direction of search, General-to-specific
’ E. g. specializing a rule by adding
conditions, Specific-to-general
’ E. g. generalizing an individual instance
into a rule
Overfitting- avoidance bias
— Can be seen as a form of search bias
— Modified evaluation criterion
E. g. balancing simplicity and number of
errors
— Modified search strategy
E. g. pruning (simplifying a description)
Pre-pruning: stops at a simple description
before search proceeds to an overly
complex one
Post-pruning: generates a complex
description first and simplifies it afterwards
Concepts, Instances, Attributes:
1. Concepts: kinds of things that can be learned.
’ Aim: intelligible and operational concept
description
2. Instances: the individual, independent
examples of a concept.
3. Attributes: measuring aspects of an instance:
nominal and numeric ones
— Practical issue: a file format for the input
Concept description: output of learning
scheme
Concepts in Data Mining:
— Styles of learning:
1. Classification: predicting a discrete class
2. Association: detecting association rules
among features
3. Clustering: grouping similar instances into
clusters
4. Numeric prediction: predicting a numeric
quantity
Reading material: Chapters 2 and 3 of
textbook by Witten, Chapter 1, Sections
3.1,3.2 and 5.2 Of the book by Han
(Reference 2).
Classification learning:
1. Classification learning is the so-called
supervised learning where the scheme will
present a final actual outcome: the class
of the example
Example problems: weather data, contact
lenses, irises, labor negotiations
— Success can be measured on fresh data
for which class labels are known
— In practice success is often measured
subjectively
Association learning is the learning
where no class is specified and any kind of
structure is considered “interesting”
Difference to classification learning:
predicting any attribute’s value, not just the
class, and more than one attribute’s value at
a time
There are far more association rules than
classification rules
To measure the success of an
association rule, we introduce two
notions
Coverage: instances that can be covered
by the rule
Accuracy: correctly predicted instances.
Minimum coverage and accuracy are posed
in learning to avoid too many useless rules.
Clustering is to find groups of items
that are similar to each other.
Clustering is unsupervised where the
class of an example is not known
Each group can be assigned as a
class. Success of clustering often
measured subjectively: how useful are
these groups to the user?
— Example: iris data without class
Numeric prediction: classification with
numeric “class”: supervised learning.
Success is measured on test data (or
subjectively if concept description is
intelligible)
— Example: weather data with numeric
attributes, the performance of CPU…
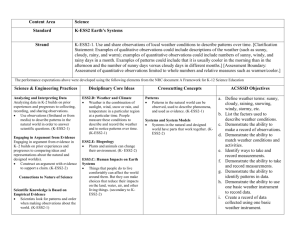
Issues in Data Mining:
In methodologies and interactions:
Mining different kind of knowledge in
databases;
Interactive mining at various level;
Incorporating domain knowledge;
Query languages and ad hoc mining;
Presentation and visualization;
Dealing with noisy and incomplete data.
Performance Issues:
Efficiency and scalability of the
algorithm;
Parallel, distributed and incremental
mining algorithm.
Issues relevant to database:
Handling relational and complex
data;
Mining from heterogeneous
databases and global information
system.