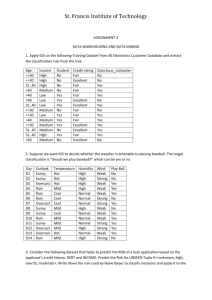
Tentamen TDDC17 Artificial Intelligence Example Exam 2011a
advertisement

Linköpings Universitet
Institutionen för Datavetenskap
Patrick Doherty
Tentamen
TDDC17 Artificial Intelligence
Example Exam 2011a
Points:
The exam consists of exercises worth 33 points.
To pass the exam you need 17 points.
Auxiliary help items:
Hand calculators.
Directions:
You can answer the questions in English or Swedish.
Use notations and methods that have been discussed in the course.
In particular, use the definitions, notations and methods in appendices 1-3.
Make reasonable assumptions when an exercise has been under-specified.
Begin each exercise on a new page.
Write only on one side of the paper.
Write clearly and concisely.
Jourhavande: Mariusz Wzorek, 0703887122. Mariusz will arrive for questions around 15.00.
1
1. Consider the following theory (where x, y and z are variables and history, lottery and john are constants):
∀x([P ass(x, history) ∧ W in(x, lottery)] ⇒ Happy(x))
(1)
∀x∀y([Study(x) ∨ Lucky(x)] ⇒ P ass(x, y))
(2)
¬Study(john) ∧ Lucky(john)
(3)
∀x(Lucky(x) ⇒ W in(x, lottery))
(4)
(a) Convert formulas (1) - (4) into clause form. [1p]
(b) Prove that Happy(john) is a logical consequence of (1) - (4) using the resolution proof procedure.
[2p]
• Your answer should be structured using a resolution refutation tree (as used in the book).
• Since the unifications are trivial, it suffices to simply show the binding lists at each resolution
step.
2. Constraint satisfaction problems consist of a set of variables, a value domain for each variable and a set
of constraints. A solution to a CS problem is a consistent set of bindings to the variables that satisfy
the contraints. A standard backtracking search algorithm can be used to find solutions to CS problems.
In the simplest case, the algorithm would choose variables to bind and values in the variable’s domain
to be bound to a variable in an arbitrary manner as the search tree is generated. This is inefficient and
there are a number of strategies which can improve the search. Describe the following three strategies:
(a) Minimum remaining value heuristic (MRV). [1p]
(b) Degree heuristic. [1p]
(c) Least constraining value heuristic. [1p]
Constraint propagation is the general term for propagating constraints on one variable onto other
variables. Describe the following:
(d) What is the Forward Checking technique? [1p]
(e) What is arc consistency? [1p]
3. The following questions pertain to the course article by Newell and Simon entitled Computer Science
as an Empirical Enquiry: Symbols and Search..
(a) What is a physical symbol system (PSS) and what does it consist of? [2p]
(b) What is the Physical Symbol System Hypothesis? [1p]
2
4. Use the Bayesian network in Figure 1 together with the conditional probability tables below to answer
the following questions. Appendix 2 may be helpful to use.
(a) Write the formula for the full joint probability distribution P (A, B, C, D, E) in terms of (conditional) probabilities derived from the bayesian network below. [1p]
(b) P (a, ¬b, c, ¬d, e)[1p]
(c) P (e | a, c, ¬b)[2p]
Winter
(A)
Sprinkler
(B)
Rain
(C)
Wet Grass
(D)
Slippery Road
(E)
Figure 1: Bayesian Network Example
A
T
F
P(A)
.6
.4
A
T
T
F
F
B
T
F
T
F
P (B | A)
.2
.8
.75
.25
A
T
T
F
F
C
T
F
T
F
P (C | A)
.8
.2
.1
.9
B
T
T
T
T
F
F
F
F
C
T
T
F
F
T
T
F
F
D
T
F
T
F
T
F
T
F
P (D | B, C)
.95
.05
.9
.1
.8
.2
0
1
C
T
T
F
F
E
T
F
T
F
P (E | C)
.7
.3
0
1
5. A∗ search is the most widely-known form of best-first search. The following questions pertain to A∗
search:
(a) Explain what an admissible heuristic function is using the notation and descriptions in (c). [1p]
(b) Suppose a robot is searching for a path from one location to another in a rectangular grid of
locations in which there are arcs between adjacent pairs of locations and the arcs only go in
north-south (south-north) and east-west (west-east) directions. Furthermore, assume that the
robot can only travel on these arcs and that some of these arcs have obstructions which prevent
passage across such arcs.
The Mahattan distance between two locations is the shortest distance between the locations
ignoring obstructions. Is the Manhattan distance in the example above an admissible heuristic?
Justify your answer explicitly. [2p]
(c) Let h(n) be the estimated cost of the cheapest path from a node n to the goal. Let g(n) be the
path cost from the start node n0 to n. Let f (n) = g(n) + h(n) be the estimated cost of the
cheapest solution through n.
Provide a general proof that A∗ using tree-search is optimal if h(n) is admissible. If possible, use
a diagram to structure the proof. [2p]
3
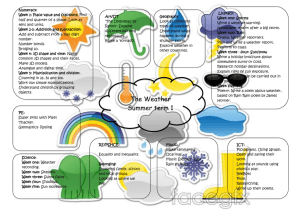
6. The following question pertains to Decision Tree Learning. Use the definitions and data table in
Figure 3, Appendix 3 to answer this question. Figure 2 shows a partial decision tree for the Table in
Figure 3 with target attribute PlayTennis.
(a) What attribute should be tested in the box with the question mark on the right branch of the decision tree in Figure 2? Justify your answer by computing the information gain for the appropriate
attributes in the Table in Figure 3 in Appendix 3. [3p]
[D1, D2, ...., D14]
[9+, 5-]
Outlook
Sunny
Overcast
Rain
[D1,D2,D8,D9,D11]
[D3,D7,D12,D13]
[D4,D5,D6,D10,D14]
[2+, 3-]
[4+,0-]
[3+,2-]
Humidity
Yes
?
Which attribute should be tested here?
Figure 2: Partial Decision Tree for PlayTennis
7. Domain-independent heuristics play an important part in many planning algorithms. Such heuristics
are often based on relaxing the original planning problem.
(a) Explain the concept of relaxing a problem and how this helps us find useful heuristics.[2p]
(b) Provide a concrete example of this technique using an action schema in a planning domain of your
choice. [2p]
8. Modeling actions and change in incompletely represented, dynamic worlds is a central problem in
knowledge representation. The following questions pertain to reasoning about action and change.
(a) What is the frame problem? Use the Wumpus world to provide a concrete example of the problem.
[2p]
(b) What is the ramification problem? Use the Wumpus world to provide a concrete example of the
problem. [2p]
(c) What is nonmonotonic logic? How can it be used to provide solutions to the frame problem? [2p]
4
Appendix 1
Converting arbitrary wffs to clause form:
1. Eliminate implication signs.
2. Reduce scopes of negation signs.
3. Standardize variables within the scopes of quantifiers (Each quantifier should have its own unique
variable).
4. Eliminate existential quantifiers. This may involve introduction of Skolem constants or functions.
5. Convert to prenex form by moving all remaining quantifiers to the front of the formula.
6. Put the matrix into conjunctive normal form. Two useful rules are:
• ω1 ∨ (ω2 ∧ ω3 ) ≡ (ω1 ∨ ω2 ) ∧ (ω1 ∨ ω3 )
• ω1 ∧ (ω2 ∨ ω3 ) ≡ (ω1 ∧ ω2 ) ∨ (ω1 ∧ ω3 )
7. Eliminate universal quantifiers.
8. Eliminate ∧ symbols.
9. Rename variables so that no variable symbol appears in more than one clause.
5
Appendix 2
A generic entry in a joint probability distribution is the probability of a conjunction of particular assignments
to each variable, such as P (X1 = x1 ∧ . . . ∧ Xn = xn ). The notation P (x1 , . . . , xn ) can be used as an
abbreviation for this.
The chain rule states that any entry in the full joint distribution can be represented as a product of conditional
probabilities:
P (x1 , . . . , xn ) =
n
Y
P (xi | xi−1 , . . . , x1 )
(5)
i=1
Given the independence assumptions implicit in a Bayesian network a more efficient representation of entries
in the full joint distribution may be defined as
P (x1 , . . . , xn ) =
n
Y
P (xi | parents(Xi )),
(6)
i=1
where parents(Xi ) denotes the specific values of the variables in Parents(Xi ).
Recall the following definition of a conditional probability:
P(X | Y ) =
P(X ∧ Y )
P(Y )
(7)
The following is a useful general inference procedure:
Let X be the query variable, let E be the set of evidence variables, let e be the observed values for them,
let Y be the remaining unobserved variables and let α be the normalization constant:
P(X | e) = αP(X, e) = α
X
P(X, e, y)
(8)
y
where the summation is over all possible y’s (i.e. all possible combinations of values of the unobserved
variables Y).
Equivalently, without the normalization constant:
P(X | e) =
P
P(X, e)
y P(X, e, y)
=P P
P(e)
x
y P(x, e, y)
(9)
6
Appendix 3
Definition 1
Given a collection S, containing positive and negative examples of some target concept, the entropy of S
relative to this boolean classification is
Entropy(S) ≡ −p⊕ log2 p⊕ − p log2 p ,
where p⊕ is the proportion of positive examples in S and p is the proportion of negative examples in S.
Definition 2
Given a collection S, containing positive and negative examples of some target concept, and an attribute A,
the information gain, Gain(S, A), of A relative to S is defined as
X
Gain(S, A) ≡ Entropy(S) −
v∈Values(A)
| Sv |
Entropy(Sv ),
|S|
where values(A) is the set of all possible values for attribute A and Sv is the subset of S for which the
attribute A has value v (i.e., Sv = {s ∈ S | A(s) = v}).
Day
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
D12
D13
D14
Outlook
Sunny
Sunny
Overcast
Rain
Rain
Rain
Overcast
Sunny
Sunny
Rain
Sunny
Overcast
Overcast
Rain
Temperature
Hot
Hot
Hot
Mild
Cool
Cool
Cool
Mild
Cool
Mild
Mild
Mild
Hot
Mild
Humidity
High
High
High
High
Normal
Normal
Normal
High
Normal
Normal
Normal
High
Normal
High
Wind
Weak
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Strong
PlayTennis
No
No
Yes
Yes
Yes
No
Yes
No
Yes
Yes
Yes
Yes
Yes
No
Figure 3: Sample Table for Target Attribute PlayTennis
For help in converting from one logarithm base to another (if needed):
loga x =
logb x
logb a
ln x = 2.303 log10 x
Note also that for the example, we define 0log0 to be 0.
7