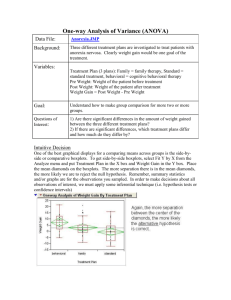
Example: Consider the data in the file Anorexia.jmp found on the
advertisement

Example: Consider the data in the file Anorexia.jmp found on the course website. These data give the pre and post weights of patients being treated for anorexia nervosa. There are actually three different treatment plans used in this study, and the goal is to compare their performance in terms of the mean weight gain of the patients. The patients in this study were randomly assigned to one of the three treatment plans. The variables in the data set are as follows: Treatment – treatment group in which patients were randomly assigned (Behavioral, Family, Standard) Prewt – weight at the beginning of treatment Postwt – weight at the end of treatment Weight Gain – weight gained (or loss) during treatment (postwt – prewt) A visual comparison of the weight gain for each treatment is given below: Questions: 1. Looking at the graph above, does there appear to be a difference in weight gain across treatment? Explain. 2. Looking at the above graph, would you expect the p-value for the ANOVA F-Test to be significant? Explain. 3. Looking at the graph above, which treatment seems to have the largest weight gain? The smallest? 1 Assumptions behind the ANOVA The samples are drawn ___________________ of each other. The population for each group is ________________ distributed. The groups should have the _________ population variances. The following graphic gives one illustration of the group populations for the anorexia example under the assumptions of normality and equal variances. Carrying out the F-Test to compare group means As we saw in the last set of notes, we can carry out the ANOVA by choosing Analyze Fit Model. The response in this scenario is the Weight Gain and the factor of interest is Treatment. Click Run and JMP will display the following results: 2 Questions: 4. What is the p-value for testing for a difference in group/treatment means? 5. Do there appear to be significant differences in weight gain across treatment groups? That is, does treatment group appear to have an effect on weight gain? Explain. Checking the ANOVA assumptions Recall the assumptions of the ANOVA: independence, normality, and constant variance. We must always check that these assumptions hold because if they are not met, this could seriously affect the pvalue just used for testing for a significant treatment effect. Independence We must make sure the samples from each group are independent of one another. This study is an example of a ________________________________________ design (CRD) which is a particular type of designed experiment. In a CRD each of the experimental units (subjects) is randomly assigned to one of the treatment groups. Because of this randomization, it is fair for us to assume that the independence assumption is OK. If the study had been an observational study, we would have to ensure ourselves that the samples were _________________ drawn samples from each of the distinct populations. Normality To verify that the normality assumption has been met, we will examine the residuals. First, click on the red drop-down arrow next to Response Weight Gain. Then choose Save Columns Residuals as shown below. 3 JMP will then add a column called Residual Weight Gain to the original data set. Next, to examine the distribution of the residuals choose Analyze Distribution. Then, put Residual in the Y, Columns box. Next, click on the red drop-down arrow next to Residual Weight Gain and choose Normal Quantile Plot as shown below. JMP will return the following graphs. The assumption of normality has been met if the points fall on or close to the reference line in the normal quantile plot and the histogram is approximately bell-shaped. Constant Variance This assumption requires us to examine the variability within each group and decide whether we have reason to believe that the variability is significantly higher in some groups than others. The easiest way to check this assumption is to examine the residual plot provided by JMP. 4 If this plot displays a “horizontal band” then we can reasonably assume the variability in each group is approximately the same. Now that we’ve shown the assumptions behind the ANOVA have been met, we can trust the p-value for testing a significant treatment effect and conclude that weight gain does seem to differ across treatment groups. However, we aren’t done yet! We need to figure out _______________ the difference(s) exist. In order to determine this we’ll look at all the ____________________ comparisons. The significant ANOVA pvalue has only told us that at least two of the groups differ significantly from each other. That is, at least one of the pairwise comparisons is significant. In this example there are _____ pairwise comparisons of interest. So the next step is to figure out whether it’s only one, two or all three of the pairwise comparisons that is significant. To put it more simply, we want to know: WHICH group means differ significantly from each other? We will use multiple comparison procedures to answer this question. Multiple Comparison Procedures We could consider performing a series of two-sample t tests to compare _____ possible pairs of means; however, if we are comparing a large number of treatment groups, we will almost certainly find two treatment means that are significantly different from one another. Why? Consider a situation where we have t = 7 different treatments we want to compare. 5 To compare all possible pairs of means (1 vs. 2, 1 vs. 3, … , 6 vs. 7) would require performing a total of t×(t-1)/2 = 21 two-sample t-tests. If we used α = P(Type I Error) = 0.05 for each test, we would expect to make 21(0.05) ≈ 1 Type I Errors. That is, we would expect to find one pair of means as being significantly different from each other when in fact they ARE NOT! This problem only becomes worse when the number of treatments (t) increases. Experiment-wise Error Rate Another way to think about this is to consider the probability of making _____ Type I Errors when making our pairwise comparisons. When t = 7 for example, the probability of making NO Type I Error is (0.95)21 = 0.3406. Therefore, the probability we make at least one Type I Error is 0.6594. This probability is called the experiment-wise error rate. Certainly this is unacceptable! Why even conduct a statistical analysis when you know you have about a 66% chance of making an error? Clearly, we must control this experiment-wise error rate. Bonferroni Correction – A Multiple Comparison Procedure There are several different ways to control the experiment-wise error rate. One of the easiest ways is to use the __________________ Correction. If we plan on making _____ comparisons, or conducting _____ significance tests, the Bonferroni Correction is to simply use _________ as our significance level rather than α. In other words, our p-values will have less than ________ rather than α to be considered statistically significant. The simple correction guarantees that our experiment-wise error rate will be no larger than _____. In JMP, the Analyze Fit Model option in JMP has the following multiple comparison options: The usual Student’s t for independent samples. This choice does not provide any experiment-wise error rate protection and is not recommended. Tukey’s Honest Significant Difference (HSD) approach. This is the best choice if you are interested in comparing each possible pair of treatments. Since we are interested in comparing each of the treatments to one another in the anorexia example, we’ll use Tukey’s HSD test. In JMP click on the red drop-down arrow next to Treatment and select LSMeans Tukey HSD as shown below. 6 Next, you may want to click on the red drop-down arrow next to LSMeans Differences Tukey HSD and select Ordered Differences Report. You should then get the following JMP output. The above output gives different letters to represent populations that have significantly different means. Notice that the Behavioral and Standard treatments are not connected by the same letter, so they are significantly different. Also, confidence intervals in the Ordered Differences section give estimates for the differences in the population means and also the p-values for t-tests using Tukey’s adjustment. For example, here we see that mean weight gain for patients in the Behavioral group is estimated to be between 2.09 lbs. and 13.34 lbs. larger than the mean weight gain for patients receiving the Standard treatment. 7