Logistic regression model (S.13)
advertisement
")
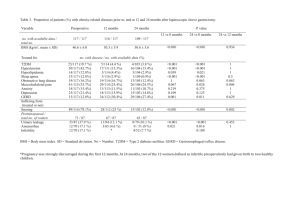
eAppendix 1. Estimation of measures of additive interaction Consider model (1) i.e. p ln (1−p) = b0 + b1 X + b2 Y + b3 XY + b4 Z1 + ⋯ + bn+3 Zn The combined effect of the arbitrary increment dx and dy of the continuous determinants X and Y is: ln (OR X:x0 →x0 +dx ,Y:y0 →y0 +dy /Zi ) = ln ( odds(X = x0 + dx , Y = y0 + dy / Zi = zi ) ) odds(X = x0 , Y = y0 / Zi = zi ) = ln[odds(X = x0 + dx , Y = y0 + dy / Zi = zi )] − ln[odds(X = x0 , Y = y0 / Zi = zi )] = b0 + b1 (x0 + dx ) + b2 (y0 + dy ) + b3 (x0 + dx )(y0 + dy ) + b4 z1 + ⋯ + bn+3 zn −(b0 + b1 (x0 ) + b2 (y0 ) + b3 (x0 )(y0 ) + b4 z1 + ⋯ + bn+3 zn ) = b1 (dx ) + b2 (dy ) + b3 (dx dy + x0 dy + y0 dx ) → OR x0 →x0 +dx ,y0 →y0 +dy /Zi = eb1 (dx )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) The effect of an arbitrary increment dx of X, for a specific value y0 of Y: ln(OR X:x0 →x0 +dxY:,y0 →y0 /Zi ) = ln ( odds(X = x0 + dx , Y = y0 / Zi = zi ) ) odds(X = x0 , Y = y0 / Zi = zi ) = ln[odds(X = x0 + dx , Y = y0 / Zi = zi )] − ln[odds(X = x0 , Y = y0 / Zi = zi )] = b0 + b1 (x0 + dx ) + b2 (y0 ) + b3 (x0 + dx )(y0 ) + b4 z1 + ⋯ + bn+3 zn −(b0 + b1 (x0 ) + b2 (y0 ) + b3 (x0 )(y0 ) + b4 z1 + ⋯ + bn+3 zn ) = b1 (dx ) + b3 (dx )y0 → OR x0 →x0 +dx,y0 →y0 /Zi = eb1 (dx )+b3 (dx )y0 The effect of arbitrary increment dy of Y, for a specific value x0 of X: ln(OR X:x0 →x0 ,Y:y0 →y0+dy/Zi ) = ln ( odds(X = x0 , Y = y0 + dy / Zi = zi ) ) odds(X = x0 , Y = y0 / Zi = zi ) = ln[odds(X = x0 , Y = y0 + dy / Zi = zi )] − ln[odds(X = x0 , Y = y0 / Zi = zi )] = b0 + b1 (x0 ) + b2 (y0 + dy ) + b3 (x0 )(y0 + dy ) + b4 z1 + ⋯ + bn+3 zn −(b0 + b1 (x0 ) + b2 (y0 ) + b3 (x0 )(y0 ) + b4 z1 + ⋯ + bn+3 zn ) = b2 (dy ) + b3 x0 (dy ) → OR x0 →x0 ,y0 →y0 +dy/Zi = eb2 (dy )+b3 x0 (dy ) By assuming that odds ratios (ORs) from (1) approximate relative risks (RR), it is straightforward that RERIx0 →x0 +dx ,y0 →y0 +dy = OR x0 →x0 +dx ,y0 →y0 +dy/Zi − OR x0 →x0 +dx,y0 →y0 /Zi −OR x0 →x0 ,y0 →y0 +dy/Zi + 1 =e b1 (dx )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) APx0 →x0 +dx ,y0 →y0+dy = − eb1 (dx )+b3 (dx )y0 − eb2 (dy )+b3 x0 (dy ) + 1 RERIx0 →x0 +dx,y0→y0+dy ORx0 →x0 +dx ,y0→y0+dy/Zi = 1 − e−b2 (dy )−b3 (x0 +dx )(dy ) − e−b1 (dx )−b3 (dx )(y0+dy ) + e−b1 (dx )−b2 (dy )−b3 (dx dy +x0 dy +y0 dx ) Sx0 →x0 +dx ,y0 →y0 +dy = OR ORx0→x0 +dx ,y0→y0+dy/Zi −1 x0 →x0 +dx ,y0 →y0 /Zi +ORx0 →x0 ,y0 →y0 +dy/Zi −2 = (d )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) eb1 x −1 eb1(dx)+b3 (dx)y0 +eb2(dy)+b3 x0(dy) −2 Knol and colleagues1 estimated Rothman's indexes in case of continuous risk factors; however, their formulae hold only for increases by 1 unit of the 2 risk factors from a background level of exposure of x0 =0 and y0 =0. 2. Estimation of variances and confidence intervals for indexes of additive interaction The partial derivatives of RERI, AP and ln(S) (f, g and ln(h) respectively) with respect to 𝑏𝑗 evaluated at 𝑏̂𝑗 , are shown below: Relative excess risk due to interaction (RERI): RERIx0 →x0 +dx ,y0 →y0 +dy = f(b1 , b2 , b3 / x0 , y0 , dx, dy) = eb1 (dx )+b2 (dy )+b3 (dx dy +x0 dy +y0dx ) −eb1 (dx )+b3 (dx )y0 − eb2 (dy )+b3 x0 (dy ) + 1 ∂f ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ f1 = ∂b | b̃=b̃̂ = dx (eb1 (dx )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) − eb1 (dx )+b3 (dx )y0 ) 1 f2 = ∂f | ̃=b̃̂ ∂b2 b = dy (eb1 (dx )+b2 (dy )+b3 (dx dy+x0 dy +y0 dx ) − eb2 (dy )+b3 x0 (dy ) ) ∂f ̂ ̂ , so (S.1) (S.2) ̂ f3 = ∂b | b̃=b̃̂ = (dx dy + x0 dy + y0 dx )eb1 (dx )+b2 (dy)+b3 (dx dy +x0 dy +y0 dx ) 3 ̂ ̂ ̂ ̂ −((dx )y0 )eb1 (dx )+b3 (dx )y0 − (x0 (dy )) eb2 (dy )+b3 x0 (dy ) (S.3) Proportion attributable to interaction (AP): APx0 →x0 +dx ,y0→y0 +dy = g(b1 , b2 , b3 / x0 , y0 , dx, dy) = 1 − e−b2 (dy )−b3 (dx dy +x0 dy ) ̂ −e−b1 (dx )−b3 (dx dy+y0 dx ) + e−b1 (dx )−b2 (dy )−b3 (dx dy +x0 dy +y0 dx ) ∂g ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ ,so g1 = ∂b | b̃=b̃̂ = dx (e−b1 (dx )−b3 (dx dy +y0 dx ) − e−b1 (dx )−b2 (dy )−b3 (dx dy +x0 dy +y0 dx ) ) (S.4) 1 ∂g g 2 = ∂b | b̃=b̃̂ = dy (e−b2 (dy)−b3 (dx dy +x0 dy ) − e−b1 (dx )−b2 (dy )−b3 (dx dy +x0 dy +y0 dx ) ) (S.5) 2 g3 = ∂g ̂ ̂ = (dx dy + x0 dy )e−b2 (dy )−b3 (dx dy+x0 dy ) | ∂b3 b̃ = b̂̃ ̂ ̂ +(dx dy + y0 dx )e−b1 (dx )−b3 (dx dy +y0 dx ) − (dx dy + x0 dy + y0 dx ) e ̂ (d )−b ̂ (d )−b ̂ (d d +x d +y d ) −b 1 x 2 y 3 x y 0 y 0 x (S.6) Synergy index (S): After converting S to ln(S), we have ln(S)x0 →x0 +dx ,y0→y0 +dy = ln[h(b1 , b2 , b3 / x0 , y0 , dx, dy)] = = ln (eb1 (dx )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) − 1) − ln (eb1 (dx )+b3 (dx )y0 + eb2 (dy )+b3 x0 (dy ) − 2) so, ln(h1 ) = = (dx ) ( ∂ln(h) | = ∂b1 b̃ = b̂̃ b (dx )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) e 1 b (dx )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) e 1 −1 ln(h2 ) = = (dy ) ( eb1 (dx)+b3 (dx)y0 e b1 (dx )+b3 (dx )y0 ) (S.7) ) (S.8) +eb2 (dy)+b3 x0 (dy ) −2 ∂ln(h) | = ∂b2 b̃ = b̂̃ b (dx )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) e 1 b (dx )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) e 1 −1 ln(h3 ) = − ∂ln(h) | ̃=b̃̂ ∂b3 b = − eb2 (dy)+b3 x0 (dy) e b1 (dx )+b3 (dx )y0 +eb2 (dy)+b3 x0 (dy) −2 (d )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) (dx dy +x0 dy +y0 dx )eb1 x (d )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) eb1 x −1 − b (d )+b3 x0 (dy ) (dx )y0 eb1 (dx )+b3 (dx )y0 +x0 (dy )e 2 y eb1 (dx)+b3 (dx)y0 +eb2 (dy)+b3 x0 (dy) −2 (S.9) Estimation of variances and confidence intervals for measures of additive interaction between two continuous risk factors using logistic regression For estimating confidence intervals for each one of the Rothmans indexes, we calculated the necessary variance estimators, by applying the delta method. Let 𝑏̃̂ = (𝑏̂1 , 𝑏̂2 , 𝑏̂3 ) denote the 3 estimated coefficients from model (1). Rothman’s indexes estimated in (3), (5), (7) in the Research Letter can be seen as functions of 𝑏̂1 , 𝑏̂2 and 𝑏̂3 , with parameters the background level of exposure x0 on X and y0 on Y, and the arbitrary increment dx of X and dy of Y, i.e: RERIx0 →x0 +dx ,y0 →y0+dy = eb1 (dx )+b2 (dy )+b3 (dx dy +x0 dy +y0 dx ) − eb1 (dx )+b3 (dx )y0 −eb2 (dy )+b3 x0 (dy ) + 1 = f(b̂ 1 , b̂ 2 , b̂ 3 / x0 , y0 , dx, dy) APx0 →x0 +dx ,y0→y0 +dy = 1 − e−b2 (dy )−b3 (dx dy +x0 dy ) − e−b1 (dx )−b3 (dx dy +y0 dx ) +e−b1 (dx )−b2 (dy )−b3 (dx dy +x0 dy+y0 dx ) = g(b̂ 1 , b̂ 2 , b̂ 3 / x0 , y0 , dx, dy) Sx0 →x0 +dx ,y0→y0 +dy = (S.10) b (d )+b (d )+b (d d +x d +y d ) e 1 x 2 y 3 x y 0 y 0 x −1 eb1 (dx)+b3 (dx )y0 +eb2 (dy )+b3 x0 (dy ) −2 ̂1 , b̂2 , b̂3 / x0 , y0 , dx, dy) = h (b (S.11) (S.12) The variances of (S.10) – (S.12) can then be estimated as follows: ̂ [RERI ̂ x →x +d ,y →y +d ] = Var ̂ [f (b̂̃ / x0 , y0 , dx , dy )] , so Var 0 0 x 0 0 y ̂ [RERI ̂ x →x +d ,y →y +d ] = f12 σ Var ̂12 + f22 σ ̂22 + f32 σ ̂23 + 2f1 f2 σ̂ 12 + 2f1 f3 σ̂ 13 + 2f2 f3 σ̂ 23 0 0 x 0 0 y Where: 𝑓𝑗 is the partial derivative of f with respect to 𝑏𝑗 evaluated at 𝑏̂̃ , j=1,2,3, that is: fj = ∂f | ∂bj b̃ = b̃̂ ̂ (b̂j , b̂k ) , k=2,3 and k>j. ̂ (b̂j ) and σ σ2j = Var ̂ ̂jk = Cov Similarly for AP : ̂ x →x +d ,y →y +d ] = Var ̂ [AP ̂ [g (b̂̃ / x0 , y0 , dx , dy )] , Var 0 0 x 0 0 y ̂ x →x +d ,y →y +d ] = g12 σ ̂ [AP Var ̂12 + g 22 σ ̂22 + g 23 σ ̂23 + 2g1 g 2 σ̂ 12 + 2g1 g 3 σ̂ 13 + 2g 2 g 3 σ̂ 23 , 0 0 x 0 0 y where gj = ∂g | ∂bj b̃ = b̃̂ For S, since it is a ratio, the coverage properties are better if a confidence interval for ln(S) rather than for S is calculated2. Therefore, at first a confidence region for ln(S) was formed and then the limits of this confidence region were exponentiated in order to calculate a confidence interval for S. So, ln(S) and its variance can be written as: ln [Ŝx0 →x0 +dx ,y0 →y0 +dy ] = ln (eb1 (dx )+b2 (dy)+b3 (dx dy +x0 dy +y0 dx ) − 1) −ln (eb1 (dx )+b3 (dx )y0 + eb2 (dy )+b3 x0 (dy) − 2) so ̂ [ln [Ŝx →x +d ,y →y +d ]] = Var ̂ [ln [h (b̂̃ / x0 , y0 , dx , dy )]] , that is Var 0 0 x 0 0 y ̂ [ln [Ŝx →x +d ,y →y +d ]] = [ln(h1 )]2 σ Var ̂12 + [ln(h2 )]2 σ ̂22 + [ln(h3 )]2 σ ̂23 0 0 x 0 0 y +2ln(h1 )ln(h2 )σ̂ 12 + 2ln(h1 )ln(h3 )σ̂ 13 + 2ln(h2 )ln(h3 )σ̂ 23 where ln(hj ) = ∂ln(h) | ∂bj b̃ = b̂̃ So the 95% confidence intervals for RERI, AP and S can be calculated as follows: ̂ − 1.96√Var ̂ [RERI ̂ ], RERI ̂ + 1.96√Var ̂ [RERI ̂] ) For RERI: (RERI , ̂ − 1.96√Var ̂ ], AP ̂ + 1.96√Var ̂] ) ̂ [AP ̂ [AP for AP: (AP , and for S: (e ̂ [ln(Ŝ)] ln(Ŝ)−1.96√Var ,e ̂ [ln(Ŝ)] ln(Ŝ)+1.96√Var ) 3. Illustrative dataset We used data from the Greek EPIC cohort. EPIC is a European longitudinal study designed to investigate the relationships between diet, lifestyle and environmental factors and the incidence of cancer and other chronic diseases3. In our paradigm, our sample consists of adult women, aged less than 45 years old of the Greek segment of the EPIC study4. The binary outcome we considered was whether a subject was hypertensive or not at enrollment (cross sectional analysis). The information of the dichotomous outcome was collected using as criteria if the participant’s diastolic or systolic blood pressure was measured more than 90 mmHg or 140 mmHg respectively at baseline. We further considered BMI (in kg/m2) and level of adherence in Mediterranean Diet (MD)2 at recruitment as continuous and ordinal risk factors respectively. The variable related to (non-) adherence to MD (NMD), has 3 levels; in the 1st level, we considered those participants that their MD score is 6-9 (i.e. high adherence to MD), in the 2nd level, those with MD score between 2-5 (i.e. moderate adherence to MD) and in the 3rd level, those with MD score 0-1 (i.e. low adherence to MD). Moreover, we include in the analysis, age (in years), height (in cm) and education (3 levels; categorically modeled) as possible confounders. With respect to the variable related to education, we considered in the 1st level those with elementary education, in the 2nd level those with secondary education and in the 3rd level those who have, at least, a university degree. Participants with missing values in any of the above variables were excluded this analysis. Descriptive statistics of all variables included in the analysis are shown in table S1. We hypothesized that increasing BMI and increasing levels of NMD would result in increasing prevalence of hypertension. In order to test our hypothesis, we ran a logistic regression model with hypertension as the dependent variable, while BMI (variable X) and increasing levels of NMD (variable Y) are considered the risk factors of interest. Age (variable Z1), education (Z2 is the dummy variable corresponding to the comparison of the 2nd level of education vs the 1st and Z3 is the dummy variable for the comparison of the 3rd level of education vs the 1st) and height (variable Z4) are considered as potential confounders. Let us consider the following model (S.13) p ln (1−p) = a0 + a1 X + a2 Y + a3 Z1 + a4 Z2 + a5 Z3 + a6 Z4 (S.13) where p is the probability of the occurrence of hypertension and a0 − a6 the estimated coefficients of the model. This is the model without the interaction between X and Y in order to illustrate that BMI and NMD are risk factors for the occurrence of hypertension. The results of the logistic regression model (S.13) are presented in table S2. Both BMI and NMD are positively associated with higher occurrence of hypertension although only BMI is deemed statistically significant. Subsequently we estimated the measures for additive interaction between BMI and NMD on the prevalence of hypertension whilst adjusting for the effects of the above potential confounders. In order to estimate Rothman's measures for additive interaction, we ran the following logistic regression model (S.14) which is (1) of the Research Letter when n=4, i.e. p ln (1−p) = b0 + b1 X + b2 Y + b3 XY + b4 Z1 , +b5 Z2 + b6 Z3 + b7 Z4 (S.14) The results of model (S.14) [or (1)] are presented in the Research Letter in Table 1. Script. Stata code for estimating additive interaction between any variables X and Y on binary outcome d. *Programming code for additive interaction between variables X, Y on binary outcome d ************************************************************************************ * At the beginning, the user has to define the variables d, x, y and x_y (i.e. the *product term x*y), and any potential confounder that should be included in the *logistic regression model. * Here we use 3 such variables, Z1, Z2, Z3 global global global global global global global d x y x_y z1 z2 z3 " " " " " " " hyper " bmi " nmd " bmi_nmd " age " i.education " height " * In the Research Letter, for our illustrative example, the variables we used are: * 1) d=hypertension (yes/no) --> hyper * 2) X=Body Mass Index (BMI), calculated in kg/m2 --> bmi * 3) Y=Non adherence to Mediterrenean diet NMD (ordered in three levels) --> nmd * 4) X_Y=Product term of BMI and NMD --> bmi_nmd=bmi*nmd * 5) Z1=age (continuous in years) --> age * 6) Z2=education (categorically in 3 levels) -> i.education * 7) Z3=height (continuous in cm)--> height * The user has to state also the parameters x0, y0, dx and dy. * In our example, in the first line of table 1, we have used x0=25, y0=1, dx=2, dy=1 global global global global x0 y0 dx dy "25" "1" "2" "1" logit $d $x $y $x_y $z1 $z2 $z3 *To estimate RERI: nlcom(RERI:exp($dx*_b[$x]+$dy*_b[$y]+($dx*$dy+$dy*$x0+$dx*$y0)*_b[$x_y])exp($dx*_b[$x]+$dx*$y0*_b[$x_y])-exp($dy*_b[$y]+$dy*$x0*_b[$x_y])+1 ) *the output give the point estimate of RERI for x0, y0, dx, dy, its associated *standard error using the delta method and the 95% CI *To estimate AP: nlcom ( AP:1-exp(-_b[$y]*$dy-_b[$x_y]*($dx*$dy+$x0*$dy))-exp(-_b[$x]*$dx_b[$x_y]*($dx*$dy+$y0*$dx))+exp(-_b[$x]*($dx)-_b[$y]*($dy)_b[$x_y]*($dx*$dy+$y0*$dx+$x0*$dy)) ) *the output give the point estimate of AP for x0, y0, dx, dy, its associated standard *error using the delta method and the 95% CI * To estimate S: *Since S is a ratio, one has to estimate ln(S) (named as "ln_syn_index" in the nlcom *command below) and the SE for ln(S) for x0, y0, dx, dy: nlcom (ln_syn_index:ln(exp($dx*_b[$x]+$dy*_b[$y]+($dx*$dy+$dy*$x0+$dx*$y0)*_b[$x_y])1)-ln(exp($dx*_b[$x]+$dx*$y0*_b[$x_y])+exp($dy*_b[$y]+$dy*$x0*_b[$x_y])-2) ), post *After obtaining _b[ln_syn_index] and _se[ln_syn_index] from the above command we *estimate S and the associated 95% CI as follows: ***Estimate S for x0, y0, dx, dy scalar Syn_index=exp(_b[ln_syn_index]) ***Estimate 95% CI for S, for x0, y0, dx, dy scalar Syn_index_low95 =exp(_b[ln_syn_index]-invnormal(0.975)*_se[ln_syn_index]) scalar Syn_index_high95=exp(_b[ln_syn_index]+invnormal(0.975)*_se[ln_syn_index]) ****And present in the output these estimates for S in one line mat define Synergy_index=(Syn_index, Syn_index_low95, Syn_index_high95) mat rown Synergy_index= Syn_index mat coln Synergy_index= S_index S_low95 S_high95 mat list Synergy_index ****End of programming code********** ************************************************************************************ References 1. Knol MJ, van der Tweel I, Grobbee DE, Numans ME, Geerlings MI. Estimating interaction on an additive scale between continuous determinants in a logistic regression model. Int J Epidemiol 2007;36:1111-8. 2. Hosmer DW, Lemeshow S. Confidence interval estimation of interaction. Epidemiology 1992;3:452-6. 3. Riboli E and Kaaks R. The EPIC Project: rationale and study design. European Prospective Investigation into Cancer and Nutrition. Int J Epidemiol 1997;26 Suppl 1:S6-14. 4. Trichopoulou A, Costacou T, Bamia C, Trichopoulos D. Adherence to a Mediterranean diet and survival in a Greek population. N Engl J Med 2003;348:2599-608 Table S1: Descriptive statistics of age, body mass index (BMI), height, hypertension, non adherence in Mediterranean Diet (NMD) and education in 4805 women aged less than 45 from the Greek-EPIC cohort Continuous variables Age (in years) BMI (in kg/m2) Height (in cm) Mean 37.99 26.62 160.02 SD 4.61 5.00 6.03 Categorical variables N Hypertension No Yes Non adherence to Mediterranean Diet (NMD) 1-->Med. Diet score 6-9 2-->Med. Diet score 2-5 3-->Med. Diet score 0-1 Education level 1-->Elementary 2-->Secondary 3-->University degree or higher (%) 4336 (90.24%) 469 (9.76%) 1133 (23.58%) 3448 (71.76%) 224 (4.66%) 1407 1917 1481 (29.28%) (39.90%) (30.82%) Table S2: Estimated coefficients from the logistic regression model (S.13) of the prevalence of hypertension in women aged less than 45 yrs old Logistic regression model (S.13) 2 Body Mass Index (in kg/m ) Non adherence to Mediterranean Diet (3 levels - ordered) Age (in years) Education: (reference category - elementary school) secondary university Height (in cm) b 0.130 0.166 0.068 se 0.009 0.105 0.013 Odds Ratio (eb) 1.14 1.18 1.07 95% Confidence Interval for Odds Ratio (1.12 - 1.16) (0.96 - 1.45) (1.04 - 1.10) -0.541 -0.897 0.021 0.118 0.147 0.009 0.58 0.41 1.02 (0.46 - 0.73) (0.31 - 0.54) (1.0 - 1.04)