mugnor1 Summer12 Mat221 Lessons Regressionprobsandans Cx
advertisement

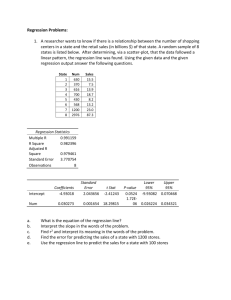
Regression Problems: 1. A researcher wants to know if there is a relationship between the number of shopping centers in a state and the retail sales (in billions $) of that state. A random sample of 8 states is listed below. After determining, via a scatter-plot, that the data followed a linear pattern, the regression line was found. Using the given data and the given regression output answer the following questions. State 1 2 3 4 5 6 7 8 a. b. c. d. e. f. Num 630 370 616 700 430 568 1200 2976 Sales 15.5 7.5 13.9 18.7 8.2 13.2 23.0 87.3 Output a= b= r= -4.930 0.030 0.991 What is the equation of the regression line? Interpret the slope in the words of the problem. Find r2 and interpret its meaning in the words of the problem. Is there a significant linear relationship between Num and Sales. Find the error for predicting the sales of a state with 1200 stores. Use the regression line to predict the sales for a state with 100 stores a. y-hat = -4.930 + 0.030x b. Slope = 0.030 means that for every increase of 1 shopping center retail sales increases 0.030 billion dollars, on average. c. r2 = .982 means that there is a 98.2% reduction in error in predicting retail sales by using number of shopping centers over the sample mean. d. The test statistic was 18.30 with a p-value 1.7 * 10-6 so there is sufficient evidence that the true slope is different from 0, meaning there is a significant linear relationship between num and sales. Or, the 95% confidence interval for the true slope was 0.026 and 0.034, which does not contain 0, so there is sufficient evidence that the true slope is different from 0, meaning there is a significant linear relationship between num and sales. e. x = 1200, y = 23.0 y-hat = 31.07 so error = 23.0 – 31.07 = -8.07 f. This is an example of extrapolation so you should not do it. 2. A pharmaceutical company is investigating the relationship between advertising expenditures and the sales of some over-the-counter (OTC) drugs. The following data represents a sample of 10 common OTC drugs. Find the equation of the regression line, using Advertising dollars as the independent variable and Sales as the response variable. Interpret the slope of the line in the words of the problem. Find r 2 and interpret it in the words of the problem. Use the line to predict the Sales if Advertising dollars = $50 million. Note that AD = Advertising dollars in millions and S = Sales in millions $. AD 22 25 29 35 38 42 46 52 65 88 S 64 74 82 90 100 120 120 142 180 230 Calculator Output a = 6.629, b = 2.569, r = .996 y-hat = 6.629 + 2.569x The slope = 2.569 means that for every increase of $1 million Advertising, sales increases $2.569 million on average. r2 = .993 so there is a 99.3% reduction in error for predicting Sales using advertising dollars. y-hat = 6.629 + 2.596(50) = 135.079 3. A chemical company wants to study the effect of extraction time on the efficiency of an extraction process. They obtained a random sample of extraction times and the corresponding efficiency scores. The output from Excel is given below. What is the regression line? Interpret the slope and R2 in the words of the problem. Use the regression line to estimate the efficiency for an extraction time of 20. You can assume 20 is in the range of the x’s. Regression Statistics Multiple R 0.864 R Square 0.746 Std Error 5.139 Obs 15 Coefficients Intercept 39.022 Time 0.764 Std Error 4.173079 0.123639 t Stat 9.350943 6.178365 P-value 3.9E-07 3.33E-05 Lower 95% 30.00684 0.496782 Upper 95% 48.03761 1.030995 y-hat = 39.022 + .764x The slope = .764 means that for every increase of 1 unit in extraction time efficiency score increases .764 units on average. r2 = .746 means that there is a 74.6% reduction is error for predicting efficiency using extraction time. y-hat = 39.022 + .764 (20) = 54.302 The model is useful because the true slope is significantly different from 0, because the 95% CI for the true slops is 0.497 to 1.031 and the is r2 = .746 reasonably high. 4. The following is output from Excel for regression analysis. The researcher wanted to predict the total cholesterol (mg/100ml) using weight (kg) as the predictor variable. Using the output, please answer the following questions? a. Use ŷ to predict the total cholesterol for a subject who weighs 70kg. b. Find the coefficient of determination and explain what this means in the words of the problem? c. Find and interpret 95% Confidence interval for B. d. Do you think weight is a good predictor total cholesterol, Explain? SUMMARY OUTPUT Regression Multiple R R Square Standard Error Observations Intercept Weight Statistics 0.265293 0.070381 76.65431 25 Coeff Std Err t Stat 199.30 85.82 2.322 1.62 1.229 1.320 ANOVA Source Regress Residual Total df 1 23 24 P-value 0.0294 0.1999 Lower 95% 21.77 -0.921 SS MS F 10231 10231 1.741 135145 5875.8 145377 Upper 95% 376.825 4.1656 y-hat = 199.30 + 1.62x for x = 70 y-hat = 312.7 r2 = .070 means that there is a 7% reduction in error for predicting total cholesterol using weight. 95% CI for B (-.921, 4.1656), means that we 95% sure that the true mean slope is between 0.921 and 4.166. This is not a good model because r2 is low and B could be 0, because 0 is in the 95% CI for B.