WriteUp
advertisement

Machine Learning – CMPUT 551, Winter 2009
Homework Assignment #2 – Support vector machines for classification and Regression
Reihaneh Rabbany
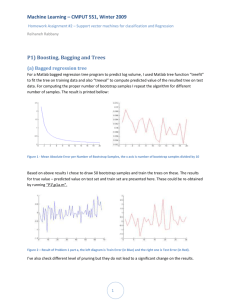
P1) (a)
Equations 12.8 and 12.25 of the textbook are equal because by starting from equation 12.8 we have:
𝑁
𝑚𝑖𝑛𝛽,𝛽0
𝑠𝑢𝑏𝑗𝑒𝑐𝑡 𝑡𝑜:
1
‖𝛽‖2 + 𝛾 ∑ 𝜉𝑖
2
𝑖=1
∀𝑖, 𝜉𝑖 ≥ 0
𝑇
𝑦𝑖 (𝑥𝑖 𝛽 + 𝛽0 ) ≥ 1 − 𝜉𝑖
This equation could be converted to equation (2),
As 𝛾 is a constant and independent of 𝛽, 𝛽0 , we
(1)
can conclude that:
𝑚𝑖𝑛𝛽,𝛽0 𝛾𝐴 = 𝑚𝑖𝑛𝛽,𝛽0 𝐴
𝑁
𝑚𝑖𝑛𝛽,𝛽0
𝑠𝑢𝑏𝑗𝑒𝑐𝑡 𝑡𝑜:
1
‖𝛽‖2 + ∑ 𝜉𝑖
2𝛾
𝑖=1
∀𝑖, 𝜉𝑖 ≥ 0
𝑦𝑖 (𝑥𝑖𝑇 𝛽 + 𝛽0 ) ≥ 1 − 𝜉𝑖
𝑠𝑢𝑏𝑗𝑒𝑐𝑡 𝑡𝑜:
1
‖𝛽‖2 + ∑ 𝜉𝑖
2𝛾
𝑖=1
∀𝑖, 𝜉𝑖 ≥ 0
𝑦𝑖 𝑓(𝑥𝑖 ) ≥ 1 − 𝜉𝑖
𝑦𝑖 𝑓(𝑥𝑖 ) − (1 − 𝜉𝑖 ) ≥ 0 𝑎𝑛𝑑 𝜉𝑖 = 0
⇒ 𝑦𝑖 𝑓(𝑥𝑖 ) − 1 ≥ 0
⇒ 𝑦𝑖 𝑓(𝑥𝑖 ) ≥ 1
In the former from 12.16 we have:
𝛼𝑖 [ 𝑦𝑖 𝑓(𝑥𝑖 ) − (1 − 𝜉𝑖 )] = 0 𝑎𝑛𝑑 𝛼𝑖 ≠ 0
⇒ 𝑦𝑖 𝑓(𝑥𝑖 ) − (1 − 𝜉𝑖 ) = 0
⇒ 1 − 𝑦𝑖 𝑓(𝑥𝑖 ) = 𝜉𝑖
1 − 𝑦𝑖 𝑓(𝑥𝑖 )
𝑖𝑓 𝑦𝑖 𝑓(𝑥𝑖 ) ≤ 1
0
𝑖𝑓 𝑦𝑖 𝑓(𝑥𝑖 ) ≥ 1
1 − 𝑦𝑖 𝑓(𝑥𝑖 )
𝑖𝑓 1 − 𝑦𝑖 𝑓(𝑥𝑖 ) ≥ 0
𝜉𝑖 = {
0
𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
𝜉𝑖 = [1 − 𝑦𝑖 𝑓(𝑥𝑖 )]+
𝜉𝑖 = {
𝑁
𝑚𝑖𝑛𝛽,𝛽0
1
‖𝛽‖2 + ∑[1 − 𝑦𝑖 𝑓(𝑥𝑖 )]+
2𝛾
𝑠𝑢𝑏𝑗𝑒𝑐𝑡 𝑡𝑜:
𝑖=1
∀𝑖, 𝜉𝑖 ≥ 0
𝑦𝑖 𝑓(𝑥𝑖 ) ≥ 1 − 𝜉𝑖
(2)
Let it be here for now, we know that equation 12.8
is equal to equations 12.9-12.16 using quadratic
programming. Consequently we could conclude
(3)
from equation 12.8 (or 12.15 and 12.12) that:
Either 𝜉𝑖 should be zero or 𝛼𝑖 should be equal to 𝛾
which is a nonzero value.
𝑁
𝑚𝑖𝑛𝛽,𝛽0
From 12.1 we know that 𝑓(𝑥𝑖 ) = 𝑥𝑖𝑇 𝛽 + 𝛽0
Therefore this equation is equal to equation (3)
In the later from 12.14 we have:
(4)
(5)
From 4 and 5 we conclude that in 12.8 we have (6)
(6)
is further equal to (7):
This is also equal to (8):
(7)
Putting this into (3) we obtain (9)
(8)
In (9) we already considered these two subject to
conditions and they are satisfied already; also as
we can see 𝑓(𝑥𝑖 ) and 𝑦𝑖 here become dependent
from 𝜉𝑖 , which means that we have no 𝜉𝑖 in our (9)
minimization function. So we could eliminate
these two constraints and reach the equation
12.25.
𝑁
𝑚𝑖𝑛𝛽,𝛽0
1
‖𝛽‖2 + ∑[1 − 𝑦𝑖 𝑓(𝑥𝑖 )]+
2𝛾
𝑖=1
.∎
1
Machine Learning – CMPUT 551, Winter 2009
Homework Assignment #2 – Support vector machines for classification and Regression
Reihaneh Rabbany
P1) (b)
Support vectors are so sensitive toward outliners since outliners play a dominant role in determining the
decision hyperplane as they tend to have the largest margin losses. Consequently, for a loss function to
be robust to outliners, it should prevent form assigning large loss values to outliners. In other word, the
less loss assigned by the loss function to the outliners, the more robust it is.
Therefore using Table 12.1 and Figure 12.4, these three given loss functions are sorted from the most
robust to the least robust to outliers as follows:
1) Binomial log likelihood
2) Support vector loss function
3) Square-loss
Because as we could see in Figure 12.4, for outliners (which are points too far that yf(x)<<0) the Binomial
log likelihood loss function gives the most loss and has the most growth. However, SV loss function and
Square root loss function are nearly the same, and grow linearly, but the Binomial log likelihood’s
asymptote is lower than SV.
2
Machine Learning – CMPUT 551, Winter 2009
Homework Assignment #2 – Support vector machines for classification and Regression
Reihaneh Rabbany
P2)
a)
Running P2\a_linear_SVM\p2a.m would result in:
=0.01
=10000
3
Machine Learning – CMPUT 551, Winter 2009
Homework Assignment #2 – Support vector machines for classification and Regression
Reihaneh Rabbany
b)
Running P2\b_cross_validation\cross_validation.m would draw figures like above
during run and finally it would draw a new figure for average result. We could conclude that =0.0120.015 gives a slightly better results but choosing 𝛾 ∈ [100,1000] is more confident as the error remains
constant between different runs for this range.
4
Machine Learning – CMPUT 551, Winter 2009
Homework Assignment #2 – Support vector machines for classification and Regression
Reihaneh Rabbany
c)
Running P2\c_non_linear_SVM\p2c.m would result in:
=0.01
=10000
5
Machine Learning – CMPUT 551, Winter 2009
Homework Assignment #2 – Support vector machines for classification and Regression
Reihaneh Rabbany
P3)
Running P3\p3.m would result in plotting these two figures. For training set error we would have:
And for the test set error we would have:
For implementing this support vector regression I used linear kernel (no kernel).
6