Handout 21, Confidence intervals for μ
advertisement

Constructing a Confidence Interval for µ
The estimate x of µ is called a point estimate because the estimator produces a
single number to estimate the parameter. Next we will examine an interval estimator
which yields an interval estimate of where the parameter resides. Such an interval is
usually called a confidence interval.
The construction of a confidence interval for a parameter is frequently very
simple. Recall our notation
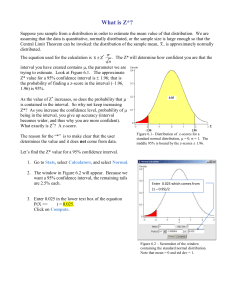
zα =
the point on the standard normal distribution which cuts off α% in the
upper tail.
For example, z.05 = 1.65 cuts off 5% in the upper tail, while z.01 = 2.33 cuts off 1% in the
upper tail.
To construct a 100(1-α)% confidence interval for µ when
(1) the normality of X is justifiable, and
(2) σ is known,
compute
x z / 2 X
( x z / 2
n
, x z / 2
n
)
Example: Incomes are known to be normally distributed in a community with σ = $5000.
In order to obtain a 90% confidence interval for µ (the average income), a sample is taken
of 25 incomes and the sample mean x $30,000 is computed.
Since you want a 90% confidence interval, α = .10. What is α/2?
Then z.05 = 1.65, and our interval is
109
x z / 2 X
30,000 (1.65) 5000
25
30,000 1,650
(28350, 31650)
Understanding the Confidence Interval
First note that by standardizing, the following probability is easy to compute:
P{ z / 2 X X z / 2 X }
P{
( z / 2 X )
X
X
X
( z / 2 X )
X
}
P{ z / 2 Z z / 2 }
1
So for our income example,
P{ z.05 X X z.05 X } 0.9
Rearranging µ and X (that is, subtracting µ and X everywhere and multiplying by (-1)):
P{ X z.05 X X z.05 X } 0.9
Notice that the expression in the middle is a fixed number (µ), and the endpoints of the
interval
( X z.05 X ,
X z.05 X )
are random!
Every time you take a sample of size n, you will get (potentially) a different value
of the sample mean. You then add and subtract a fixed number ( z.05 X ) to the mean.
Will the resulting interval contain µ?
110
If you get an
x
at location 1, will your interval contain µ?
At location 2?
At location 3?
In fact, anytime our sample mean falls in ( z.05 X , z.05 X ) , our confidence
interval will contain µ. By construction, this will happen 90% of the time. As a result,
we can make the following statement about our 90% confidence interval:
With 90% probability, our sample mean will fall within $1650 of the true average
income (µ).
Of course, we don’t know if our specific interval was one of these lucky 90%.
111
For a 95% confidence interval:
x z.025 X
30,000 (1.96) 5000
25
30,000 1,960
(28040, 31960)
How does this compare to our 90% confidence interval?
If we increase our sample to n = 100, our 95% confidence interval becomes
x z.025 X
30,000 (1.96) 5000
100
30,000 980
(29020, 30980)
How does this interval compare to the last one?
The term z / 2 X (which is half of the length of the confidence interval) is
sometimes referred to as the precision of the estimate. Assuming for a moment that your
interval contains µ, how far away can µ be from x ?
| x | z X
2
the “precision”
From this perspective, how is a confidence interval superior to a point estimate?
What are the two ways you can make the confidence interval smaller?
112