Distributed databases
advertisement

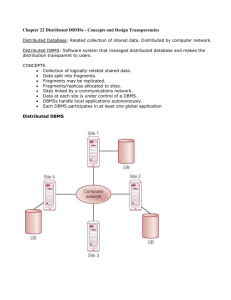
Distributed databases A distributed database [1][2] is a set of databases in a distributed system that can appear to applications as a single data source and consists of two or more data sites located at different sites on a computer network. Database systems that run on each site are independent of each other. Transactions may access data at one or more sites. However, the DBMS (Data Base Management System) must periodically synchronize the scattered databases to make sure that they all have consistent data. Advantages – Resilient: A problem in one part of the organisation will not stop other branches from working. – Scaling: If a new store or branch is opened then it is straight forward to add an extra node to the distributes database – Easier to keep errors local rather than the entire organisation being affected – Integrity: Even if a system fails the integrity of the distributed database is maintained Disadvantages – Complexity: A distributed database is more complicated to setup and maintain compared to a central database – Security: There are many remote entry points to the system compared to a central database – Data integrity: More complex to make sure data and indexes are not corrupted Homogeneous vs heterogeneous Distributed Database System Homogeneous: The sites would share a common global schema and run the same database management software. The sites are aware of the existence of other sites and agree to cooperate in processing user requests. It appears to user as a single system since all sites use the same DBMS product [4]. Example: The above diagram shows a distributed system that connects three databases: hq, mfg, and sales. Here, an application can simultaneously access or modify the data in several databases in a single distributed environment. Easy retrieval A single query from a Manufacturing client on local database mfg can retrieve joined data from the products table on the local database and the dept table on the remote hq database. For a client application, the location and platform of the databases are transparent. Easy accessibility For example, if you are connected to database mfg but want to access data on database hq, creating a synonym on mfg for the remote dept table enables you to issue this query: SELECT * FROM dept In this way, a distributed system gives the appearance of native data access. Users on mfg do not have to know that the data they access resides on remote databases. Heterogeneous: In a heterogeneous distributed database system [3], at least one of the databases uses different schemas and software. But a database system having different schema may cause a major problem for query processing and a database system having different software may cause a major problem for transaction processing. Distributed Data Storage Replication System maintains multiple copies of data, stored in different sites, for faster retrieval and fault tolerance [6][7]. Advantages of Replication Availability: If one of the sites containing relation R fails, then the relation R can be obtained from another site. Thus, queries (involving relation R) can be continued to be processed in spite of the failure of one site. Increased Parallelism: The sites containing relation R can process queries (involving relation R) in parallel This leads to faster query execution. Less Data Movement over Network: The more replicas of, a relation are there, the greater are the chances that the required data is found where the transaction is executing. Hence, data replication reduces movement of data among sites and. increases .speed of processing. Disadvantages of Replication Increased overhead on update: When an updation is required, a database system must ensure that all replicas are updated. Require more disk space: Storing replicas of same data at different sites consumes more disk space. Solution: choose one copy as primary copy and apply concurrency control operations on primary copy. Fragmentation Data can be stored in different computers by fragmenting the whole database into several pieces called fragments. Each piece is stored at a different site. Fragments are logical data units stored at various sites in a distributed database system. Fragmentation can be horizontal or vertical [5]. Advantages Usage - In general, applications work with views rather than entire relations. Therefore, for data distribution, it seems appropriate to work with subsets of relation as the unit of distribution. Efficiency - Data is stored close to where it is most frequently used. In addition, data that is , not needed by local applications is not stored. Parallelism- With fragments as the unit of distribution, a transaction can be divided into several sub queries that operate on fragments. This should increase the degree of concurrency, or parallelism, in the system, thereby allowing transactions that can do so safely to execute in parallel. Security - Data not required by local applications is not stored, and consequently not available to unauthorized users. Disadvantages: Performance - The performance of global application that requires data from several fragments located at different sites may be slower. Integrity - Integrity control may be more difficult if data and functional dependencies are fragmented and located at different sites. Horizontal Fragmentation Each fragment, Ti , of table T contains a subset of the rows Each tuple of T is assigned to one or more fragments. Horizontal fragmentation is lossless Horizontal Fragmentation Example A bank account schema has a relation: Account-schema = (branch-name, account-number, balance). It fragments the relation by location and stores each fragment locally: rows with branch-name = `Hillside` are stored in the Hillside in a fragment Vertical Fragmentation Each fragment, Ti, of T contains a subset of the columns, each column is in at least one fragment, and each fragment includes the key: Ti = attr_listi (T) T = T1 T2 …. Tn All schemas must contain a common candidate key (or superkey) to ensure lossless join property. A special attribute, the tuple-id attribute may be added to each schema to serve as a candidate key. Vertical Fragmentation Example A employee-info schema has a relation: employee-info schema = (designation, name, Employee-id, salary). It fragments the relation to put information in two tables for security concern. Commit Protocols In distributed data base and transaction systems a distributed commit protocol is required to ensure that the effects of a distributed transaction are atomic, that is, either all the effects of the transaction persist or none persist, whether or not failures occur. A transaction which executes at multiple sites must either be committed at all the sites, or aborted at all the sites. The Two-Phase Commit (2 PC) Protocol The two phase commit protocol is a distributed algorithm which lets all sites in a distributed system agree to commit a transaction. The protocol results in either all nodes committing the transaction or aborting, even in the case of site failures and message losses. Two-phase commit technology is used for hotel and airline reservations, stock market transactions, banking applications, and credit card systems. With a two-phase commit protocol, the distributed transaction manager employs a coordinator to manage the individual resource managers. Disadvantages There have been two performance issues with two phase commit: – If one database server is unavailable, none of the servers gets the updates. – This is correctable through network tuning and correctly building the data distribution through database optimization techniques. – References [1] [2] [3] [4] [5] [6] [7] M, Valduriez P,1991, “Principles of Distributed Database Systems”, PrenticeHall.P. Bernstein, V. Hadzilacos and N. Goodman. S. Ceri and G. Pelagatti, “Distributed Databases: Principles and Systems”, 1984 : McGraw-Hill A. Ferrier and C. Stangret "Heterogeneity in the distributed database management systems SIRIUS-DELTA", Proc. 8th Int. Conf. on Very Large Data Bases, pp.45 -53 1982 Ashish Srivastava1, Udai Shankar2 and Sanjay Kumar Tiwari, “Transaction Management in Homogenous Distributed Real-Time Replicated Database Systems”, Volume 2, Issue 6, June 2012 L. Bellatreche "An Algorithm for Vertical Fragmentation in Distributed Object Database Systems", Proceedings of the Second International Baltic Workshop on Databases and Information Systems, 1996 T. Beuter and P. Dadam, & ldquo, “Principles of Replication Control in Distributed Database Systems”, &rdquo, Informatik Forschung und Technik, vol. 11, no. 4, pp. 203-212, 1996, in German. Nicoleta Iacob, "Data Replication In Distributed Environments", Annals of the Constantin Brâncuşi" University of Târgu Jiu, Economy Series, Issue 4/2010.