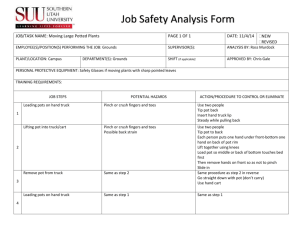
R Notes 2011 LAB 2 Topics covered: One
advertisement

R Notes 2011 LAB 2
Topics covered:
One-way ANOVA
Levene’s test
ANOVA with nested design
> setwd("G:/Courses/A205/R/Lab2")
> lab2a<-read.table('Lab2a.txt', header=T)
#
#
#
#
#
#
#
#
#
#
>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
read.table reads white spaces as separators as default. You can specify in
the parameters of read.table the type of separator: e.g.: sep=”\t“ for tab
only as separator. When you use a new command it is useful to ask the
manual what are the default values and its usage (> ?read.table).
alternatively: read.csv can be used for comma separated values or
read.delim for tab separated values. Remember to look at the manual for the
usable parameters: you will discover the very handy parameter sep, that
allows to set how the values are separated: sep=“ “ is the default value
for read.table, sep=”\t” or sep=”,” can be used for tab and comma separated
values respectively.
lab2a
Culture N_level
3DOk1
24.1
3DOk1
32.6
3DOk1
27.0
3DOk1
28.9
3DOk1
31.4
3DOk5
19.1
3DOk5
24.8
3DOk5
26.3
3DOk5
25.2
3DOk5
24.3
3DOk4
17.9
3DOk4
16.5
3DOk4
10.9
3DOk4
11.9
3DOk4
15.8
3DOk7
20.7
3DOk7
23.4
3DOk7
20.5
3DOk7
18.1
3DOk7
16.7
3DOk13
14.3
3DOk13
14.4
3DOk13
11.8
3DOk13
11.6
3DOk13
14.2
Comp
17.3
Comp
19.4
Comp
19.1
Comp
16.9
Comp
20.8
PLS205 2011
2.1
R Lab 2
#
#
#
#
#
When input data in R you should always check how R has interpreted them.
Eventually you may need to make some adjustments. You can look at the data
by typing again the name of the data.frame you created (Lab2_N), if the
data are composed of thousand or rows you can visualize only the first of
the last lines with the head and tail commands, respectively.
#
#
#
#
The function str is useful to get a summary of the data and how R is
interpreting them. If numerical factors, R by default will consider them
continuous numbers; factors need to be recognized as such and composed of
discrete levels; a very useful command is str.
> str(lab2a)
'data.frame': 30 obs. of 2 variables:
$ Culture: Factor w/ 6 levels "3DOk1","3DOk13",..: 1 1 1 1 1 4 4 4 4 4 ...
$ N_level: num 24.1 32.6 27 28.9 31.4 19.1 24.8 26.3 25.2 24.3 ...
# Or we can ask the question using the is.factor function (if you need to
# convert numerical values to factors you may use the function as.factor)
> lab2a<-read.table('Lab2a.txt', header=T)
> is.factor(lab2a$Culture)
[1] TRUE
> is.factor(lab2a$N_level)
[1] FALSE
# To select specific part of the table
> lab2a[lab2a$Culture=="Comp",]
Culture N_level
26
Comp
17.3
27
Comp
19.4
28
Comp
19.1
29
Comp
16.9
30
Comp
20.8
> lab2a[lab2a$N_level>="25",]
Culture N_level
2
3DOk1
32.6
3
3DOk1
27.0
4
3DOk1
28.9
5
3DOk1
31.4
8
3DOk5
26.3
9
3DOk5
25.2
PLS205 2011
2.2
R Lab 2
One way ANOVA
#
#
#
#
To define the one-way ANOVA model (result_variable~classification_variable)
we can use the function lm. It is important to note the order of the
arguments: the first argument is always the dependent variable (N_level).
It is followed by the tilde symbol (~) and the independent variable(s).
> model<-lm(N_level~Culture, data=lab2a)
> anova(model)
Analysis of Variance Table
Response: N_level
Df Sum Sq Mean Sq F value
Pr(>F)
Culture
5 845.72 169.144 25.363 7.537e-09 ***
Residuals 24 160.05
6.669
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# We use the anova function to visualize the ANOVA table of a linear model
# defined using lm (for aov model use summary). Summary can be used also with
# lm models and returns the R2:
> summary(model)
Call:
lm(formula = N_level ~ Culture, data = lab2a)
Residuals:
Min
1Q Median
-4.840 -1.750 0.660
3Q
1.245
Max
3.800
Coefficients:
Estimate Std. Error t value
(Intercept) 19.8633
0.4715 42.130
Culture1
-7.7700
0.8166 -9.515
Culture2
-2.1433
0.4715 -4.546
Culture3
1.2633
0.3334
3.789
Culture4
-0.0540
0.2582 -0.209
Culture5
-0.2327
0.2109 -1.103
--Signif. codes: 0 '***' 0.001 '**' 0.01
Pr(>|t|)
< 2e-16
1.29e-09
0.000132
0.000896
0.836129
0.280771
***
***
***
***
'*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.582 on 24 degrees of freedom [= Root MSE in SAS]
Multiple R-squared: 0.8409,
Adjusted R-squared: 0.8077
F-statistic: 25.36 on 5 and 24 DF, p-value: 7.537e-09
# Reminder from previous lab: it is easy to calculate exact p-value from know
# F-values in R using pf.
PLS205 2011
2.3
R Lab 2
> pf(25.36, 5, 24, lower.tail=F)
[1] 7.546316e-09
?pf
lower.tail= logical; if TRUE (default), probabilities are P[X <= x],
otherwise, P[X > x].
# We can easily calculate the coefficient of variation:
> Nlevel_Mean<-mean(lab2a$N_level)
> Root_MSE<-sqrt(6.67)
> Root_MSE
[1] 2.582634
> Coeff_Var<-Root_MSE/Nlevel_Mean*100
> Coeff_Var
[1] 13.00202
In SAS
R-Square
0.840866
Coeff Var
13.00088
Root MSE
2.582408
Nlevel Mean
19.86333
> plot(lab2a)
# same result boxplot(N_level ~ Culture, data=lab2a)
# We can easily extract the predicted and the residual values using the
# predict and residual functions.
> predi<-predict(model)
> predi
1
2
14
15
28.80 28.80
14.60 14.60
18
19
19.88 19.88
PLS205 2011
3
16
28.80
19.88
20
19.88
4
5
6
7
8
9
10
11
12
13
17
28.80 28.80 23.94 23.94 23.94 23.94 23.94 14.60 14.60 14.60
19.88
21
22
23
24
25
26
27
28
29
30
13.26 13.26 13.26 13.26 13.26 18.70 18.70 18.70 18.70 18.70
2.4
R Lab 2
> resi<-residuals(model)
> resi
1
2
3
4
5
6
7
15
16
17
-4.70 3.80 -1.80 0.10 2.60 -4.84 0.86
1.20 0.82 3.52
18
19
20
21
22
23
24
0.62 -1.78 -3.18 1.04 1.14 -1.46 -1.66
8
9
10
11
12
2.36
1.26
0.36
3.30
25
26
0.94 -1.40
27
0.70
28
29
0.40 -1.80
13
14
1.90 -3.70 -2.70
30
2.10
# Adding the Predicted and residual vectors to the data.frame lab2a
> lab2a$predi<-predi
> lab2a$resi<-resi
# We can print the first 10 rows using head function to visualize the new
# table lab2a and use the write.table function to save it a tab delimited
# text file.
> head(lab2a, 10)
# 10 specifies the number of rows: 5 is default.
1
2
3
4
5
6
7
8
9
10
Culture N_level predi resi
3DOk1
24.1 28.80 -4.70
3DOk1
32.6 28.80 3.80
3DOk1
27.0 28.80 -1.80
3DOk1
28.9 28.80 0.10
3DOk1
31.4 28.80 2.60
3DOk5
19.1 23.94 -4.84
3DOk5
24.8 23.94 0.86
3DOk5
26.3 23.94 2.36
3DOk5
25.2 23.94 1.26
3DOk5
24.3 23.94 0.36
> write.table(Lab2a, "try3.txt", sep='\t')
Levene’s test
1- Calculating Levene’s test by hand (ANOVA of the square of the residuals)
> lab2a$resi2<-lab2a$resi^2
> modelLevene<-lm(lab2a$resi2~Culture, data=lab2a)
> anova(modelLevene)
Analysis of Variance Table
PLS205 2011
2.5
R Lab 2
Response: lab2a$resi2
Df Sum Sq Mean Sq F value Pr(>F)
Culture
5 226.99 45.398 1.1528 0.3606
Residuals 24 945.17 39.382
2- Levene’s test using the ‘car’ package
# To install a new package, we can use the install.packages function.
> install.packages("car")
--- Please select a CRAN mirror for use in this session select close US
location]
Content type 'application/zip' length 728229 bytes (711 Kb)
opened URL
downloaded 711 Kb
package 'car' successfully unpacked and MD5 sums checked
# The package is downloaded but not available. Each R session you need to
# activate the downloaded library (it saves memory to have only the necessary
# libraries open)
> library(car)
> help(car)
#
#
#
#
If you want to change the list of default packages you need to modify the
Rprofile file. Search the Rprofile file in your computer and open it with a
txt editor (e.g. word pad). Once it’s open, you have to search for this
part:
local({dp <- as.vector(Sys.getenv("R_DEFAULT_PACKAGES"))
if(identical(dp, "")) # marginally faster to do methods last
dp <- c("datasets", "utils", "grDevices", "graphics",
"stats", "methods", "car", "agricolae")
else if(identical(dp, "NULL")) dp <- character(0)
else dp <- strsplit(dp, ",")[[1]]
dp <- sub("[[:blank:]]*([[:alnum:]]+)", "\\1", dp) # strip whitespace
options(defaultPackages = dp)
})
#
#
#
#
#
#
#
The part I have highlighted are the names of the two additional packages I
want to be loaded at startup. Add the names of the packages between
quotation mark. Save the new Rprofile file and restart R console to see the
changes you have made. A word of advice: don’t change anything else in the
Rprofile file, if you don’t know what you are doing…
Running the Levene’s test: deviation from medians is the default. SAS
calculates deviation from means.
> levene.test(model, center=mean)
Levene's Test for Homogeneity of Variance (center = mean)
Df F value Pr(>F)
group 5 0.5841 0.7119
24
PLS205 2011
2.6
R Lab 2
# Caution: R/car uses a different version of the Levene’s test than SAS:
# R version is of Levene is based on absolute deviations (instead of the
# square deviations in SAS).
3- Alternative homogeneity of variance tests: Bartlett and Fligner-Killeen
Tests
> bartlett.test(N_level~Culture, lab2a)
Bartlett test of homogeneity of variances
data: N_level by Culture
Bartlett's K-squared = 3.9834, df = 5, p-value = 0.5518
> fligner.test(N_level~Culture, lab2a)
Fligner-Killeen test of homogeneity of variances
data: N_level by Culture
Fligner-Killeen:med chi-squared = 2.7889, df = 5, p-value = 0.7325
ANOVA with nested design
> lab2b<-read.table('lab2b.txt', header=T)
> str(lab2b)
'data.frame': 72 obs. of 4 variables:
$ Trtmt : int 1 1 1 1 1 1 1 1 1 1 ...
$ Pot
: int 1 1 1 1 2 2 2 2 3 3 ...
$ Plant : int 1 2 3 4 1 2 3 4 1 2 ...
$ Growth: num 3.5 4 3 4.5 2.5 4.5 5.5 5 3 3 ...
# Since R is not interpreting the first three variables as factors we need to
# declare that they are factors using the as.factor function.
> lab2b$Plant<-as.factor(lab2b$Plant)
> lab2b$Pot<-as.factor(lab2b$Pot)
> lab2b$Trtmt<-as.factor(lab2b$Trtmt)
> str(lab2b)
'data.frame': 72 obs. of 4 variables:
$ Trtmt : Factor w/ 6 levels "1","2","3","4",..: 1 1 1 1 1 1 1 1 1 1 ...
$ Pot
: Factor w/ 3 levels "1","2","3": 1 1 1 1 2 2 2 2 3 3 ...
$ Plant : Factor w/ 4 levels "1","2","3","4": 1 2 3 4 1 2 3 4 1 2 ...
$ Growth: num 3.5 4 3 4.5 2.5 4.5 5.5 5 3 3 ...
To have all the variance components: nested design using linear mixed-effects
models with lmer (lme4 package)
> install.packages("lme4")
> library(lme4)
PLS205 2011
2.7
R Lab 2
# We design a model where the dependent variable growth is function only of a
# random effect that considers the hierarchical design nesting of ‘Pot’
# within ‘Trtmt’ (1|Trtmt/Pot):
> model<-lmer(Growth ~ 1 + (1|Trtmt/Pot), data=lab2b)
> model
Linear mixed model fit by REML
Formula: Growth ~ 1 + (1 | Trtmt/Pot)
AIC
BIC logLik deviance REMLdev
237.2 246.3 -114.6
230.3
229.2
Random effects:
Groups
Name
Variance Std.Dev.
Pot:Trtmt (Intercept) 0.30469 0.55198
Trtmt
(Intercept) 2.81464 1.67769
Residual
0.93403 0.96645
Number of obs: 72, groups: Pot:Trtmt, 18; Trtmt, 6
Fixed effects:
Estimate Std. Error t value
(Intercept)
5.7847
0.7064
8.19
# Now we can calculate the variance components as percentage:
> variances<-c(0.30,2.8,0.93)
> variances/sum(variances)*100
[1] 7.444169 69.478908 23.076923
In SAS
SAS. Nested Random Effects Analysis of Variance for Variable Growth
Variance
Source
DF
Sum of
Squares
Total
Trtmt
Pot
Error
71
5
12
54
255.913194
179.642361
25.833333
50.437500
F Value
Pr > F
Error
Term
16.69
2.30
<.0001
0.0186
Pot
Error
Mean Square
Variance
Component
Percent
of Total
3.604411
35.928472
2.152778
0.934028
4.053356
2.814641
0.304688
0.934028
100.0000
69.4398
7.5169
23.0433
Growth Mean
Standard Error of Growth Mean
5.78472222
0.70640396
To have the p-value:
# Using lm
> anova(lm(Growth~Trtmt/Pot, lab2b))
Analysis of Variance Table
Response: Growth
Df Sum Sq Mean Sq F value Pr(>F)
Trtmt
5 179.642 35.928 38.4662 < 2e-16 ***
Trtmt:Pot 12 25.833
2.153 2.3048 0.01858 *
Residuals 54 50.438
0.934
PLS205 2011
2.8
R Lab 2
#
#
#
#
#
38.5 is the incorrect F value for Trtmt because it is using the wrong error
term. R computes F values using the residual MS as the error term (0.934
in this case). The calculation of the correct F and P needs to be
completed by hand. You need to know that the MSE Trtmt needs to be divided
by the Trtmt/Pot error term (2.153) and not the residual.
> Fvalue_trtmt<-35.928/2.1528
> Fvalue_trtmt
16.69
> pf(16.69, 5, 12, lower.tail=F)
4.880102e-05
> Fvalue_treatment_pot<-2.1528/0.934
> Fvalue_treatment_pot
2.30
> pf(2.30, 12, 54, lower.tail=F)
0.01882839
In SAS
SAS: Tests of Hypotheses Using the Type III MS for Pot(Trtmt) as an Error Term
Source
DF
Type III SS
Mean Square
F Value
Pr > F
Trtmt
5
179.6423611
35.9284722
16.687
<.0001
# We could use lm only and calculate the variance components by hand:
# MSSE= 2error = 0.93
# MSEE= 2 pot= (MSE - 2error)/4= (2.15-0.93)/4= 0.30
# MST= (MST –MSEE)/12= (35.93-2.15)/12=2.81
Nested design with ANOVA with multiple error terms (aov) [not covered in
class]
> model_nest<-aov(Growth~Trtmt+Error(Trtmt/Pot), lab2b)
> summary(model_nest)
Error: Trtmt
Df Sum Sq Mean Sq
Trtmt 5 179.642 35.928
Error: Trtmt:Pot
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 12 25.8333 2.1528
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 54 50.437
0.934
# Again then the calculation of F and P needs to be completed by hand. You
# need to know that the MSE Trtmt needs to be divided by the Trtmt:Pot error
# term and not the residual.
PLS205 2011
2.9
R Lab 2

![3. 1. The F distribution [ST&D p. 99]](http://s3.studylib.net/store/data/005838055_1-b38de3cf744c31ef431011fac9feda60-300x300.png)