Measures of spread and Cumulative Frequency
advertisement

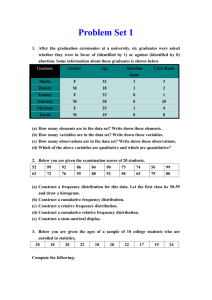
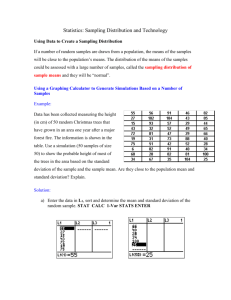
Measuring Spread of Data – work with a partner (1) Read the following scenario and answer the question as best you can: Suppose you have two types of biscuit packing machines in your factory, A and B. Each type of machine is supposed to insert 200g of biscuits into a packet. If packets are overweight or underweight you could be losing profits or running the risk of prosecution from the government trading standards office. In order to guide your future purchasing decisions, you decide to test which type of machine, A or B, is more reliable. As part of your testing procedure, you take a random sample of ten packets of biscuits from each machine and record the mass of each packet, to the nearest gram. Here are the results: Machine A (mass in grams): 196, 198, 198, 199, 200, 200, 201, 201, 202, 205 Machine B (mass in grams): 195, 195, 195, 198, 200, 201, 203, 204, 204, 205 Which type of machine, A or B, is the best one to buy in the future? Explain your reasoning, showing any diagrams, graphs or calculations you used to help you make your decision. (2) Please discuss in your group these questions. Give examples of situations where it is important to measure the spread of a data set What methods do you already know for measuring the spread of a data set? Which are the most sophisticated? Which are the most problematic and why? What was your conclusion to the question in the above scenario and why? Come see Ms. Makunja and be ready for a chat about your understanding. Cumulative Frequency – group task Take 10 minutes to read and digest the following scenario and questions and discuss it with a partner. Cumulative frequency graphs answer questions such as “What proportion of the data has values less than …?” Cumulative frequency on the y-axis is plotted against the observed value on the x-axis. Describe the shape the graph would take. With grouped data the first step is to produce a table of cumulative frequencies (the sum of the frequencies up to each particular class). These are then plotted against the corresponding upper class boundaries (ucb). The successive points are then connected by a curve. Scenario In studying bird migration a standard technique is to put coloured rings around the legs of the young birds at their breeding colony. This means that the source of any bird (with a coloured ring) later seen somewhere else can be identified. The following data, which refer to the recoveries of razorbills, consist of the distances (measured in hundreds of miles) between the recovery point and the breeding colony. We can illustrate the data using a cumulative frequency curve and estimate the distance exceeded by 50% of the birds. Distance (miles) x x < 100 100 x < 200 200 x < 300 300 x < 400 400 x < 500 500 x < 600 600 x < 700 700 x < 800 800 x < 900 900 x < 1000 1000 x < 1500 1500 x < 2000 2000 x < 2500 Frequency 2 2 4 3 5 7 5 2 2 0 2 0 2 Cumulative Frequency 2 4 8 11 16 23 28 30 32 32 34 34 36 The final value in the cumulative frequency column represents what? Cumulative Frequency Cumulative Frequency Graph The graph (when drawn accurately) tells us that 50% of the birds had travelled for more than 520 miles. To get this answer we look at 18 on the vertical scale and read a value off the horizontal scale. Why? 38 36 34 32 30 28 26 24 22 20 18 16 14 12 10 8 6 4 2 0 0 500 1000 1500 2000 2500 3000 Distance (miles) Read and make notes on the information given on page 451 of your text. What are percentiles? What are quartiles? What is the Interquartile Range? What does it show you about a set of data? The graph below shows how the interquartile range is found and how quartiles are related to a Box Plot. Use the graph to calculate an approximation for the interquartile range for your data. Show your work here Cumulative Frequency Cumulative Frequency Graph 38 36 34 32 30 28 26 24 22 20 18 16 14 12 10 8 6 4 2 0 0 500 1000 1500 2000 Distance (miles) 2500 3000 Example Below are two sets of data. For each set find the upper and lower quartiles (Q1 and Q3) and the median (Q2) and the interquartile range. For textbook help with this section, refer to page 446, and read examples 13 and 14. 1) 2, 2, 3, 3, 4, 4, 4, 5 2) 2, 2, 3, 3, 3, 4, 4, 5, 6, 6, 7, 7 Practice: Cumulative Frequency – Exercise 18C page 443 Q. 3, 4, 9 Measuring the Spread of Data – Exercise 18D.1 Q. 1d (by hand and with calculator), 2 Percentiles and Quartiles - Exercise 18D.2 Q. 2, 5, 7 (use technology), 8 4) Standard Deviation – teacher led discussion The standard deviation is a way of measuring all the variation within a sample. How do you think standard deviation is calculated from a frequency table? x Frequency x Frequency (f) 1 2 fx 4 1 5 1 (x- x ) 6 1 9 2 (x- x )2 f(x- x )2 1 4 5 6 9 Standard Deviation for Grouped Data – partner activity – participation recorded Work with a partner on this example and be ready to take part in a whole class discussion. Try to explain the steps being followed. Why do these steps lead to an estimate for the standard deviation? The question is: Estimate the standard deviation of the weights of 40 year 11 students whose weights were measured to the nearest kg: Weight (kg) 50-54 55-59 60-64 65-69 70-74 75-79 Midpoint (x) 52 57 62 67 72 77 Frequency (f) 2 1 7 18 11 1 Total = 40 104 57 434 1206 792 77 2670 435.1250 95.0625 157.9375 1.1250 303.1875 105.0625 1097.5000 Explain what these process are showing us: (x- x ) (x- x )2 f(x- x )2 fx 2670 66.75 x f 40 s f (x x) f 2 1097.5 5.24 40 Standard deviation with the graphic calculator - work through these steps Raw data set: 5, 17, 15, 3, 9, 11 To find the standard deviation of this data set, follow these steps: STAT EDIT 1:Edit ENTER Highlight heading L1 CLEAR ENTER then type the data into list L1 STAT CALC 1:1-Var Stats ENTER 2nd 1 ENTER To see x 5 (the standard deviation is 5, the variance is 52 = 25) Frequency Table: Here are the scores achieved by 20 students in a test: 3, 8, 9, 1, 4, 2, 7, 6, 5, 9, 10, 3, 4, 6, 2, 8, 7, 6, 3, 7 Here is the data organised into a frequency table: Score out of ten (x) 1 2 3 4 5 6 7 8 Frequency (f) 1 2 3 2 1 3 3 2 Follow these steps to find the standard deviation of the scores of the group of students: STAT EDIT 1:Edit ENTER Highlight heading L1 CLEAR ENTER then type the integers from 1 to 10 into list L1 Highlight heading L2 CLEAR ENTER Then type the frequencies shown in the table (1, 2, 3, 2, and so on) into list L2 STAT CALC 1:1-Var Stats ENTER 2nd 1 , (comma key is above the 7) 2nd 2 ENTER To see x 2.578759392 (so 2.58 to 3 s.f.) 9 2 10 1 To find the variance accurately now do: VARS 5 4 x2 ENTER to get variance = 6.65 graded on homework completion Please show all steps of working – you may use a calculator to check your answers. Page 150 Ex. 5I.1 questions 1, 2, 3, 4a,b,c, 6.