Standard Error: Sampling Distributions & Hypothesis Testing
advertisement

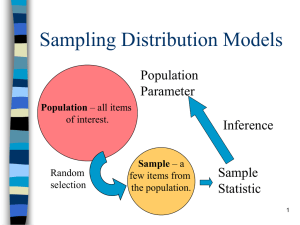
Standard Error Inferential statistics are based on the concept of making decisions using distributions of sample means (AKA sampling distributions). The reason to use samples is that populations are usually too large or impossible to test. If one sets up a distribution of means, you can judge the relative position of your sample mean compared to the population mean. With this information, you can make a judgment called a hypothesis test. In any case - there are different shapes of sampling distributions. Some are bell shaped like the t-distribution. Some have asymmetrical shapes like the Chi-square and F-distributions (both related). You generate sampling distribution by: Defining a population Generating all possible samples of a given size from the population Plotting that distribution. We will use an artificial population of five numbers, which are 1, 2, 3, 4, 5. If you want, assume that it is after World War III and only 5 people survive, they are the population. We test them on some variable. One person gets 1, another gets 2, etc. Note that the mean for this population is 3 and its standard deviation is 1.414. I decide to take a sample size of 2. I pick a person at random. Then, I pick again. It is possible that I pick the same person twice. These would be all my possible samples. I have also calculated the mean of each of the samples. There are 25 possible samples. Subject 1 1.00 1.00 1.00 1.00 Subject 2 1.00 2.00 3.00 4.00 Average of The Sample* 1.00 1.50 2.00 2.50 1.00 2.00 2.00 2.00 2.00 2.00 3.00 3.00 3.00 3.00 3.00 4.00 4.00 4.00 4.00 4.00 5.00 5.00 5.00 5.00 5.00 5.00 1.00 2.00 3.00 4.00 5.00 1.00 2.00 3.00 4.00 5.00 1.00 2.00 3.00 4.00 5.00 1.00 2.00 3.00 4.00 5.00 3.00 1.50 *Average = (2 + 1)/2 = 1.50 2.00 2.50 3.00 3.50 2.00 2.50 3.00 3.50 4.00 2.50 3.00 3.50 4.00 4.50 3.00 3.50 4.00 4.50 5.00 To have my distribution of means, I prepare a frequency distribution of the sample means (my last column of figures). Sample Average 1.00 1.50 2.00 2.50 3.00 3.50 4.00 4.50 5.00 Frequency 1 2 3 4 5 4 3 2 1 Percent 4.0 8.0 -> Look for the two 1.50 values above 12.0 16.0 20. 16.0 12.0 8.0 4.0 Total Number of Samples = 25 Now, I graph this distribution and calculate its mean and standard deviation. - This is a distribution of means. Its mean has to be the same as that of the population mean. Its standard deviation is the standard error of the mean. Look at the Graphic below. Thus, we can see that most samples are close to 3.0 but there are some extreme sample means with values of 1.0, 1.5 and 4.5 and 5.0. Now I will redo the exercise with a sample size of 3. Here is the list of all possible samples of size 3, with averages for each sample: Subject 1 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Etc., etc., etc. 1.00 1.00 1.00 1.00 2.00 2.00 2.00 2.00 2.00 2.00 2.00 2.00 Etc., etc., etc. 2.00 2.00 Subject 2 1.00 1.00 1.00 1.00 1.00 2.00 2.00 2.00 2.00 2.00 3.00 3.00 3.00 3.00 3.00 Subject 3 1.00 2.00 3.00 4.00 5.00 1.00 2.00 3.00 4.00 5.00 1.00 2.00 3.00 4.00 5.00 Average of Sample 1.00 1.33 1.67 2.00 2.33 1.33 1.67 2.00 2.33 2.67 1.67 2.00 2.33 2.67 3.00 5.00 5.00 5.00 5.00 1.00 1.00 1.00 1.00 1.00 2.00 2.00 2.00 2.00 3.00 4.00 5.00 1.00 2.00 3.00 4.00 5.00 1.00 2.00 3.00 2.67 3.00 3.33 3.67 1.33 1.67 2.00 2.33 2.67 1.67 2.00 2.33 4.00 4.00 1.00 2.00 2.33 2.67 2.00 2.00 2.00 2.00 2.00 2.00 2.00 2.00 3.00 3.00 3.00 3.00 3.00 Etc., etc., etc. 5.00 5.00 5.00 5.00 5.00 Sample Average 1.00 1.33 1.67 2.00 2.33 2.67 3.00 3.33 3.67 4.00 4.33 4.67 5.00 4.00 4.00 4.00 5.00 5.00 5.00 5.00 5.00 1.00 1.00 1.00 1.00 1.00 3.00 4.00 5.00 1.00 2.00 3.00 4.00 5.00 1.00 2.00 3.00 4.00 5.00 3.00 3.33 3.67 2.67 3.00 3.33 3.67 4.00 1.67 2.00 2.33 2.67 3.00 5.00 5.00 5.00 5.00 5.00 1.00 2.00 3.00 4.00 5.00 3.67 4.00 4.33 4.67 5.00 Frequency 1 3 6 10 15 18 19 18 15 10 6 3 1 Percent .8 2.4 4.8 8.0 12.0 14.4 15.2 14.4 12.0 8.0 4.8 2.4 .8 Now, I present a graphic which compares the sampling distribution with a sample size of two versus a sampling distribution with a sample size of three. 1. Fewer Extremes: With the larger sample size (3) - note that there are fewer extreme sample means. Look at the number of samples means with a mean of 5. This is an extreme and not very representative mean. The percentage is dramatically less for the N=3 sample. Thus, with larger samples - you don't get wacky means that much. 2. Tighter distributions - note that the standard deviation of all the sample means (the standard error) is smaller than with a sample size of 2. It's mean is again 3 but the standard deviation of this distribution of means is equal to .82. Depending on your situation, you don't have to actually construct a distribution. The value of the standard error can be calculated. equals the standard deviation calculated from your sample. The standard error formula can vary for different sample statistics. One can determine the standard error for a proportion, different between means, a correlation coefficient, slope of a regression line, intercept and other items. Your texts can supply these. The important idea is that you have a sample statistic and want to build a frequency distribution of all the possible samples. Then, you want to describe the variability of these samples. This is the use of the standard error.