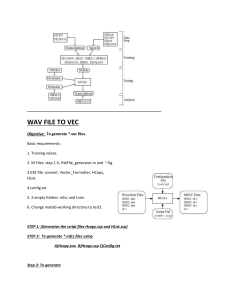
tutorial for digit recognition, see erratra at the end
advertisement

The first part of the assignment is to build a simple digit recognition
system with whole-word models using the HTK software toolkit. In brief, the
process consists of the following steps:
1)
2)
3)
4)
5)
6)
7)
Building the task grammar (a "language model")
Constructing a dictionary for the models
Creating transcription files for training data
Encoding the data (feature processing)
(Re-)training the acoustic models
Evaluating the recognizer against the test data
Reporting recognition results
Each of these is explained in a little more detail below. For a comprehensive
overview, please refer to the HTKBook.
1) Building the task grammar
The task grammar defines constraints on what the recognizer can expect as
input. In this problem, we use an FSG to represent the constraints (in the
future, we will use statistical language models). Create a file called
'grammar' with the following contents:
$digit = ONE | TWO | THREE | FOUR | FIVE |SIX | SEVEN | EIGHT | NINE | OH |
ZERO;
( SENT-START ( $digit ) SENT-END )
( SENT-START ( <$digit> ) SENT-END )
Convert this grammar to an HTK wordnet lattice using the HParse tool:
HParse grammar wordnet
2) Constructing a dictionary
The dictionary provides an association between "words" used in the task
grammar and the acoustic models, which may be composed of sub-word (phonetic,
syllabic, etc.) units. Since we are using whole-word models in this
assignment, the dictionary has a simple structure. Create a file called
'lexicon' that has the following structure:
one
one
two
two
...
nine
nine
zero
zero
sent-start sil
sent-end sil
Also, create a file named 'wlist' which contains the following lines:
one
two
...
nine
zero
sent-start
sent-end
Next, create an HTK edit script file, 'global.ded', that has the following
commands:
AS sp
RS cmu
MP sil sp sil
Finally, create the dictionary using the HDMan tool:
sort wlist /o wlistSort
sort lexicon /o lexiconSort
HDMan -m -w wlistSort -n models1 -l dlog dict lexiconSort
The dictionary used by HTK is 'dict'.
3) Creating transcription files for training data
For training, we need to tell the recognizer which files correspond to
what digit. These transcriptions are provided in the form of a Master Label
File (MLF) for compactness. You will need to construct the source MLF
(source.mlf) as follows:
#!MLF!#
"*/00F1SET0.lab"
zero
.
"*/01F1SET0.lab"
one
.
"*/02F1SET0.lab"
two
.
(etc.)
It is assumed that 00F1SET0.WAV contains the utterance 'zero', and so on.
Next, the model transcriptions must be obtained. For this, create an HTK edit
script called 'mkphones0.led' containing the following:
EX
IS sil sil
DE sp
Then use the HLed tool for expanding the word transcriptions into model
transcriptions (models0.mlf):
HLEd -l '*' -d dict -i models0.mlf mkphones0.led source.mlf
4) Encoding the data
This is the feature extraction step. In order to specify to HTK the nature of
the audio data (format, sample rate, etc.) and feature extraction parameters
(type of feature, window length, pre-emphasis, etc.), create a configuration
file (config) as follows:
# Coding parameters
ADDED NEXT LINE MYSELF <ALI july 27 09>
SOURCEFORMAT = WAV
TARGETKIND = MFCC_0_D_A
TARGETRATE = 100000.0
SAVECOMPRESSED = T
SAVEWITHCRC = T
WINDOWSIZE = 250000.0
USEHAMMING = T
PREEMCOEF = 0.97
NUMCHANS = 26
CEPLIFTER = 22
NUMCEPS = 12
ENORMALISE = F
You may want to change some parameters to suit your needs. Next, create an
HTK script file (hcopy.scp) that contains the following lines:
/home/ee619/assignment/digit/train/00F1SET0.WAV
preferred-folder/00F1SET0.mfc
/home/ee619/assignment/digit/train/01F1SET0.WAV
preferred-folder/01F1SET0.mfc
/home/ee619/assignment/digit/train/02F1SET0.WAV
preferred-folder/02F1SET0.mfc
...
/home/your-login/your/home/your-login/your/home/your-login/your-
One line for each file in the training set. This file tells HTK to extract
features from each audio file in the first column and save them to the
corresponding feature file in the second column. The command is:
HCopy -T 1 -C config -S hcopy.scp
HCopy -T 1 -C configExt -S hcopy.scp
5) (Re-)training the acoustic models
You will use a "flat-start" initialization of the model HMMs. First, create a
file called 'train.scp' that lists all the training feature files, as
follows:
/home/your-login/your-preferred-folder/00F1SET0.mfc
/home/your-login/your-preferred-folder/01F1SET0.mfc
/home/your-login/your-preferred-folder/02F1SET0.mfc
...
Next, create a prototype HMM ('proto'), left-to-right configuration with 3
states and 39 dimensional feature vectors as follows:
~o <VecSize> 39 <MFCC_0_D_A>
~h "proto"
<BeginHMM>
<NumStates> 5
<State> 2
<Mean> 39
0.0 0.0 0.0 ...
<Variance> 39
1.0 1.0 1.0 ...
<State> 3
<Mean> 39
0.0 0.0 0.0 ...
<Variance> 39
1.0 1.0 1.0 ...
<State> 4
<Mean> 39
0.0 0.0 0.0 ...
<Variance> 39
1.0 1.0 1.0 ...
<State> 5
<Mean> 39
0.0 0.0 0.0 ...
<Variance> 39
1.0 1.0 1.0 ...
<State> 6
<Mean> 39
0.0 0.0 0.0 ...
<Variance> 39
1.0 1.0 1.0 ...
<TransP> 5
0.0 1.0 0.0 0.0
0.0 0.6 0.4 0.0
0.0 0.0 0.6 0.4
0.0 0.0 0.0 0.7
0.0 0.0 0.0 0.0
<EndHMM>
0.0
0.0
0.0
0.3
0.0
Then, use HCompV to initialize the prototype model with means and variances
from the training data.
#USE A VERSION OF config that does not have SOURCEFORMAT=WAV or use HTK
#instead of WAV
HCompV -C config -f 0.01 -m -S train.scp -M hmm0 proto
HCompV -C configTrain -f 0.01 -m -S train.scp -M hmm0 proto
Note that you must first create a folder called 'hmm0' in the current folder,
or the command will fail. This command places a new version of 'proto' in the
'hmm0' folder. Next, create a master macro file ('hmmdefs') in the 'hmm0'
folder. This file should contain copies of the "proto" HMM renamed to each of
the required models ('one' through 'zero', and 'sil').
Then invoke the HERest tool for embedded re-estimation as follows:
HERest -C config -I models0.mlf -t 250.0 150.0 1000.0 -S train.scp -H
hmm0/macros -H hmm0/hmmdefs -M hmm1 models0
HERest -C configTrain -I models0.mlf -t 250.0 150.0 1000.0 -S train.scp -H
hmm0/macros -H hmm0/hmmdefs -M hmm1 models0
when I run the above line it gives me error 6510 later. to fix this open
models0.mlf and get rid of the the ' before and after the star so it
% it should look like this
#!MLF!#
"*/000.lab"
sil
zero
sil
where 'models0' is just 'models1' less the 'sp' model. Make sure the folder
'hmm1' is created before you run this command. Repeat the command a couple of
more times:
HERest -C config -I models0.mlf -t 250.0 150.0 1000.0 -S train.scp -H
hmm1/macros -H hmm1/hmmdefs -M hmm2 models0
HERest -C config -I models0.mlf -t 250.0 150.0 1000.0 -S train.scp -H
hmm2/macros -H hmm2/hmmdefs -M hmm3 models0
Now, increment the number of pdf mixtures from 1 to 2 as follows:
HHEd -H hmm3/macros -H hmm3/hmmdefs -M hmm4 incmix.2.hed models0
The contents of incmix.2.hed are:
MU 2 {*.state[2-4].mix}
Redo the HERest command a couple of more times. Assume that the most recent
models are in hmm6. Now, increment the number of pdf mixtures from 2 to 4 as
follows:
HHEd -H hmm6/macros -H hmm6/hmmdefs -M hmm7 incmix.4.hed models0
The contents of incmix.4.hed are:
MU 4 {*.state[2-4].mix}
Repeat HERest two more times to get the updated models in the folder 'hmm9'.
Then, fix the 'sp' short pause model by "borrowing" a state from the 'sil'
model:
- Use a text editor on the file 'hmm9/hmmdefs' to copy the centre state of
the 'sil' model to make a new 'sp' model and store the resulting MMF
'hmmdefs', which includes the new 'sp' model, in the new directory 'hmm10'.
%SEE ERRATA
- Run the HMM editor HHEd to add the extra transitions required and tie the
'sp' state to the centre 'sil' state. In this case, the command is:
HHEd -H hmm10/macros -H hmm10/hmmdefs -M hmm11 sil.hed models1
where sil.hed contains the following commands
AT
AT
AT
TI
2 4 0.2 {sil.transP}
4 2 0.2 {sil.transP}
1 3 0.3 {sp.transP}
silst {sil.state[3],sp.state[2]}
Finally, run HERest two more times to obtain the final models in 'hmm13'. The
acoustic models are now ready.
%SEE ERRATA
To run the recognizer and evaluate the results, use the following tools.
HVite is the Viterbi decoder that performs recognition. It should be invoked
as below:
HVite -H hmm13/macros -H hmm13/hmmdefs -S test.scp -l '*' -i recout.mlf -w
wordnet -p 0.0 -s 5.0 dict models1
HVite -H hmm13/macros -H hmm13/hmmdefs -S test.scp -l '*' -i recout.mlf -w
wordnet -p -70.0 -s 0 dict models1
where 'test.scp' is the script file that contains a list of feature files
that are to be recognized (you must create these feature files (*.mfc) using
HCopy in the same manner as you created 'train.scp' for training).
Finally, evaluate the performance of the speech recognizer using the HResults
tool.
HResults -I testref.mlf models1 recout.mlf
where again you need to create 'testref.mlf' (test data reference
transcriptions) the same way you created 'source.mlf' (training data
transcriptions). The recognition results will be displayed in terms of Word
Error Rate (WER), including the number of insertions, deletions and
substitutions that would align the reference and recognized transcriptions.
Errata and Addenda to the digit recognition tutorial.
In step 1, define the grammar as follows:
$digit = ONE | TWO | THREE | FOUR | FIVE |SIX | SEVEN | EIGHT | NINE | ZERO;
( SENT-START ( $digit ) SENT-END )
In step 2, define the dictionary as follows:
ONE
one
TWO
two
...
NINE
nine
ZERO
zero
SENT-START [] sil
SENT-END [] sil
and then sort this dictionary in alphabetical order using the Linux 'sort'
command. Sorting is necessary. The word list 'wlist' created in this step
must also be all-caps. The model is in lower case, the dictionary word is in
caps.
In step 4, the config file should look somewhat like this:
TARGETKIND= MFCC_0_D_A
TARGETRATE=100000.0
SAVECOMPRESSED=T
SAVEWITHCRC=T
WINDOWSIZE=300000.0
USEHAMMING=T
PREEMPCOEF=0.97
NUMCHANS=26
CEPLIFTER=22
NUMCEPS=12
ENORMALISE=F
SOURCEFORMAT=NIST <-- this line is important!!
HEADERSIZE=1024
TARGETFORMAT=HTK
In step 5, when creating the proto HMM, you should define only 3 states.
There is an error in the tutorial. Please delete the definitions of <STATE> 5
and <STATE> 6 i.e. your proto HMM should only contain <STATE> 2 through
<STATE> 4, and the transition matrix.
Also, in this step, use the following config file for HCompV
TARGETKIND= MFCC_0_D_A
TARGETRATE=100000.0
SAVECOMPRESSED=T
SAVEWITHCRC=T
WINDOWSIZE=300000.0
USEHAMMING=T
PREEMPCOEF=0.97
NUMCHANS = 26
CEPLIFTER = 22
NUMCEPS = 12
ENORMALISE= F
HEADERSIZE=1024
TARGETFORMAT=HTK
HCompV creates a new 'proto' in the folder 'hmm0'. It also creates a file
called 'vFloors'. Now, in addition to creating 'hmmdefs' as defined in the
tutorial, you must also create a file called 'macros' in which you copy and
paste the contents of the file 'vFloors'.
For running HERest in the remaining steps, use the same config file you used
for HCompV.
When you add the 'sp' model, create a new HMM definition in the 'hmmdefs'
file (you can add it at the end of the file) as follows:
~h "sp"
<BEGINHMM>
<NUMSTATES> 3
<STATE> 2
< here is stuff copied from under <STATE> 3 of the "sil" model >
<TRANSP> 3
0.000000e+00 5.000000e-01 5.000000e-01
0.000000e+00 5.000000e-01 5.000000e-01
0.000000e+00 0.000000e+00 0.000000e+00
<ENDHMM>
You need to provide this default transition matrix when creating the "sp"
HMM. After adding the "sp" model, you will get a warning message from HERest,
saying:
Pruning-On[250.0 150.0 1000.0]
WARNING [-2331] UpdateModels: sp[10] copied: only 0 egs
Ignore this warning.
Please remove all references to the word "OH" from the lexicon, wordlist and
model list. We do not have any data that corresponds to "OH" and will not be
using it. Be aware that everything to do with Linux / HTK is case sensitive.
If you get any unexpected errors, check that all your files, config
parameters and case stuff is in order.
IF hmmdefs in hmm13 does not have a “sp” state then add this at the end of
hmmdefs in hmm13
~h "sp"
<BEGINHMM>
<NUMSTATES> 3
<STATE> 2
~s "silst"
<TRANSP> 3
0.000000e+000 7.000000e-001 3.000000e-001
0.000000e+000 6.000000e-001 4.000000e-001
0.000000e+000 0.000000e+000 0.000000e+000
<ENDHMM>