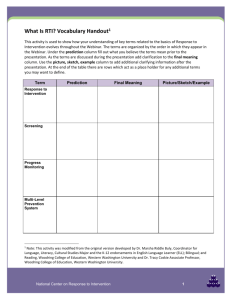
Prediction Error in the Bennett and Stam 1996 model
advertisement

Revisiting Predictions of War Duration Scott Bennett and Allan Stam The Pennsylvania State University and University of Michigan sbennett@psu.edu and stam@umich.edu July 15, 2008 Abstract We reexamine the fit of Bennett and Stam’s 1996 model of war duration, correcting errors in the reported estimates of prediction accuracy. We discuss how to assess fit in the absence of standard or widely accepted measures of fit in duration models. We introduce a proportional reduction in error measure for duration models, and report new estimates of model fit from the Bennett and Stam model. The model does significantly reduce prediction error relative to a naïve model. Introduction In Bennett and Stam (1996), we estimated a model of war duration incorporating measures of military attributes, domestic politics, and military strategy in the first analysis of war duration to employ current event-history/hazard model techniques. In discussing the results, we presented several statistics to assess the model’s fit to the data in terms of the accuracy of predictions. These statics included the mean error of prediction from different models, the median error, and the prediction error as a percentage of war length. Unfortunately, there was an error in the computation and reporting of the last of these measures. In this paper, we revisit the prediction accuracy (“fit”) of the Bennett and Stam model in the original data. We also revisit the broader question of how model “fit” in duration models should be assessed. After discussing the measures we originally reported, we also present an alternative proportional reduction in error (PRE) measure, and argue that it is a better single measure of fit for predictions in duration models. With the corrected error measure, the model represents a clear improvement over both a null model, and over models containing subsets of independent measures. Original Data and Method Bennett and Stam developed a data set of 78 wars and assessed the independent effects associated with17 independent variables on their duration. The original data were largely drawn from the Correlates of War project’s list of interstate wars, with updates from various other sources such as Clodfelter (1992) and Dupuy and Dupuy (1986), as implemented in Stam (1996). A Weibull duration model was estimated on a final dataset of 78 wars, and 169 war-years. The paper was one of the first papers to use current event history methods (also known as hazard analysis, duration analysis, or survival analysis) in political science, and more specifically international relations. It concluded that military strategy, domestic political factors, and realpolitik variables all independently influence the length of wars, and that war was not duration dependent once independent variables had been appropriately included in a statistical model. Results reported by Bennett and Stam (2006) with a data set updated to include the 1990/1991 Persian Gulf War were almost identical. Others have modified the data or reanalyzed it after incorporating other explanatory variables (e.g. Slantchev 2004), or taken the findings as informative for creating new theoretical models of war (e.g., Filson and Werner 2002, 2004; Langlois and Langlois 2008). In this paper, we reexamine the original data set and results, as this is where incorrect estimates of fit were reported. Assessing Fit in the War Duration Model Along with a review of their standard hypothesis testing results, Bennett and Stam (1996) discussed the overall fit of their model and its ability to accurately predict war durations using data that would be available ex ante. They noted that maximum likelihood models “do not have an overall measure of fit analogous to the R2 statistic in an OLS model” (pg. 250). To provide a general sense of how the model fit the data they provided three auxiliary indicators of prediction error. Their approach provided an intuitive feel for gauging the accuracy of their model’s predictions, explaining that their model typically was off by n months, or typically came within x% of the actual length. Such assessments of accuracy are relatively uncommon in analyses of duration data. Bennett and Stam’s analysis of aggregate model fit began with the computation of the absolute value of the difference between the model’s prediction in each war and the actual war length. For example, the predicted duration of some individual war might be 2 months more or less than its actual duration. They then reported the mean absolute error, median absolute error, and mean absolute error as a percentage of war length for each of the models they estimated. There are two good reasons for including multiple measures of overall model fit. First, there is no single best measure of model fit in duration models (or MLE models in general). Second, the data on war duration is highly skewed, with most wars being very short with only a few long wars. Because of skew, the mean and median errors differ significantly. As a result, a naïve model predicting just the mean or median war length might perform very well in terms of mean or median error, but would obviously be unable to identify any circumstances associated with either particularly long wars, or wars that are unusually brief. Because of the skew in the data, if the model did make longer predictions, but the duration of those wars was especially long (e.g. the model predicts 24 months but the duration was 60 months), the absolute error in these sorts of cases could still appear very large. The idea of computing error as a percentage of war length is a plausible way to see how well a model performs relative to the specific cases, given the large variance and skewed distribution of the duration data. Revisiting the original model provides an opportunity to consider how to best assess predictions of war length using an econometric model. There are several potential measures for assessing prediction errors. The obvious starting point is always a prediction of the length of each war in the data set using the parameter estimates generated using the MLE estimation compared to the war’s actual duration. The difference between the two (predicted duration – actual duration) may be positive or negative for any war, with a negative value indicating that the war’s length was under-predicted, and a positive value indicating that the length was overpredicted. The simplest assessment would be the mean error across all wars. Because some errors are positive and some negative, this mean could end up being positive or negative, with a negative mean suggesting that the model is somewhat under predicting actual war lengths, and a positive mean suggesting net over prediction. However, unless there is systematic bias in the predictions, they will sum to near-zero, as there will be under- and over- predictions balancing each other out. Moreover, this would tell us nothing about the size of the typical error or the variance of the prediction errors. For example, if one model yielded prediction error in two cases of +2 months and -2 months, the mean error would be 0; if a different model produced errors of +10 months and -10 months, the mean would still be 0. The variance in the distribution of errors is much higher in the second case, and this would be reflected in a higher standard error of the estimate. But here it would be critical to examine the combination of mean and variance. A better measure, particularly as a single measure, might be the mean absolute value of the error for each war. Using absolute values means that errors do not average out to 0, and lead to intuitive statements such as “the typical estimate is off by x months.” Bennett and Stam (1996) reported this value, and its standard deviation. Bennett and Stam further computed the absolute error in war length as a percentage of the length of the war. As noted above, the intuition behind computing and reporting this measure is that the magnitude of an error matters relative to the expected duration of the war. In other words, a three-month error should be seen as less important in a five-year war than in a onemonth war. Unfortunately, this measure has its own pathology resulting from the cases where the error is greater than the length of the war. When dividing error by length, resulting values less than 1 indicate that the error was less than the war’s actual length, while values greater than 1 mean the error was more than the actual length. A 0.75 (e.g.) indicates that the error is 25% of the war’s length (say predicting 3 months when the war took 4 months), while a 2.0 indicates that the error is twice the war’s length (say predicting 8 months when the war took 4 months). For wars where the absolute value of the prediction is less than the war’s duration, the values are bounded between 0 and 1. But when the absolute value of the prediction is greater than actual duration, the ratio is (theoretically) unbounded. Prediction errors as a proportion of length are biased in that they will be largest for the shortest wars. For example, in a 1-month war, a 6month error leads to a 600% error, while in a 12-month war, that same 6-month error is a 50% error. When averaging the computed errors as a proportion of war length, the average will tend to yield high values. In the example just given, the average error is 325% of war length, even though both wars were off by 6 months, and the total error was 6 months out of 13 months of war. This measure actually creates a problem related to that which it was intended to avoid! A Proportional Reduction in Error (PRE) measure of prediction fit These considerations lead us to develop a new measure here for estimating how well econometric models fit duration data, following a proportional-reduction-in-error approach. Proportional Reduction in Error (PRE) estimates of model fit focus on how much a model’s total prediction error drops following fitting a subsequent model to the data. The “removed” or “reduced” errors are reported as a percentage of the total error produced by a naïve model fit to the data. In the case of the war duration data, we can conceive of an error in predicting each war, which is the absolute prediction error (abs[predicted duration – actual duration]). We can obtain the total possible prediction error by estimating a constant-only model on the data, and summing the resulting absolute prediction error across all wars. This error is the total error that we would have given a naïve or null understanding of the determinants of war duration. We then estimate an improved model with covariates, and sum the absolute prediction errors across all wars. This summed error constitutes the new error estimate. Comparing the aggregate errors for the null model to the errors from the model with covariates, we can then compute the proportional reduction in error as Proportional Reduction in Error = 𝑛𝑎ï𝑣𝑒 𝑚𝑜𝑑𝑒𝑙 𝑒𝑟𝑟𝑜𝑟 – 𝑖𝑚𝑝𝑟𝑜𝑣𝑒𝑑 𝑚𝑜𝑑𝑒𝑙 𝑒𝑟𝑟𝑜𝑟 𝑛𝑎ï𝑣𝑒 𝑚𝑜𝑑𝑒𝑙 𝑒𝑟𝑟𝑜𝑟 The statistic provides an estimate of the reduced error relative to the initial total error possible. This simple formulation is an appropriate way to assess error reduction, and eliminates the problem of discrepant scaling when assessing error as a proportion of the initial war length. Moreover, it is conceptually the same as and comparable to PRE measures reported in other contexts when many other types of estimators are used. In this case, given that error takes the form of months off from the estimated model vs. true duration, we have PRE = 𝑠𝑢𝑚 𝑜𝑓 𝑎𝑏𝑠𝑜𝑙𝑢𝑡𝑒 𝑚𝑜𝑛𝑡ℎ𝑠 𝑜𝑓 𝑒𝑟𝑟𝑜𝑟 𝑓𝑟𝑜𝑚 𝑛𝑎ï𝑣𝑒 𝑚𝑜𝑑𝑒𝑙 – 𝑠𝑢𝑚 𝑜𝑓 𝑎𝑏𝑠𝑜𝑙𝑢𝑡𝑒 𝑚𝑜𝑛𝑡ℎ𝑠 𝑜𝑓 𝑒𝑟𝑟𝑜𝑟 𝑓𝑟𝑜𝑚 𝑖𝑚𝑝𝑟𝑜𝑣𝑒𝑑 𝑚𝑜𝑑𝑒𝑙 𝑠𝑢𝑚 𝑜𝑓 𝑎𝑏𝑠𝑜𝑙𝑢𝑡𝑒 𝑚𝑜𝑛𝑡ℎ𝑠 𝑜𝑓 𝑒𝑟𝑟𝑜𝑟 𝑓𝑟𝑜𝑚 𝑛𝑎ï𝑣𝑒 𝑚𝑜𝑑𝑒𝑙 We can also compute PRE using [sum of absolute error/actual duration] to compute the reduction in the percentage error of the model. While the components of this estimation (error/duration) suffer from the same possible problem detailed above (of skew towards large values when error exceeds actual duration), a PRE measure based on these has the same interpretation as the PRE in absolute error, namely the reduction in total error when error is measured as the individual war error/duration. In our tables, we report the PRE in absolute prediction error, and PRE in absolute error/actual duration. Assessing the accuracy of duration predictions via a PRE method is actually possible using any measure of error generated by any statistical duration model that produces point estimates. Point predictions rather than a distribution of durations are necessary because the predicted durations generated using the statistical models are compared to the observed durations. However, in the context of parametric or semi-parametric duration models, only certain models make such predictions. In particular, point predictions of duration can be made only for the family of parametric models, e.g. those that assume an exponential, Weibull, gamma, or other specific function for the baseline hazard. Point predictions cannot be made using the Cox proportional-hazard duration model. To be able to generate a predicted duration of the process in question requires specification of the baseline hazard function. The Cox model specifically rejects making any assumptions about this attribute of the data generating process. Making out-of-sample predictions requires specification of the full functional form of the baseline hazard rate. Doing so defeats the purpose of estimating a Cox model. With a Cox model we can conduct standard hypothesis test about the presence or absence of a variable’s associated effect on the duration data. We can also assess the independent variables’ effects on the relative hazard of the process in question ending without assuming any particular distribution for the baseline hazard. The tradeoff that comes with not assuming an underlying functional form is that assessment of prediction accuracy – whether via PRE or any other method – cannot be done with the Cox model. Finally, we note that the PRE method we use can be used to assess either models that are structured to estimate the associated effects of time-varying covariates (TVCs), or those that have only time-invariant covariates. By time-varying covariates we mean data with independent variables whose values vary over time within an individual case composed of multiple observations. In the time-varying covariates case there are several observations or “lines of data” for each case or spell (e.g. each war) in the data set. In the time-invariant case, there is only one observation per spell. In the instance of using a data set with time-varying covariates, the estimation of the model’s coefficients assumes that when there are multiple observations, all observations within a particular case except the last observation are censored, with the final outcome unobserved. With a set of parameter estimates in hand, all it takes to produce a point prediction for a hypothetical duration is a specified set of values for the full set of independent variables. In the case of a duration model, this string of “X” values is simply multiplied by the produced B coefficients to produce the familiar XB, which is then directly used in eXB to predict a duration time. In the instance of data with TVCs, we could actually make a point prediction on the basis of any of the observations associated with a given case/war, obtaining several duration estimates that would change as the covariates changed over the life of a case. There is no good way to use information about the full “path” of the TVCs to make a prediction, so in order to avoid overcounting the multiple observations of spells with TVCs, we should base the prediction on just one of the observations when computing the PRE statistic or other measures of average values. Doing so ensures produce an average across wars and not observations. In the results for the TVC model we present here, we use the TVC values from the final observation of each war. Reanalysis We performed our replication and reanalysis of the Bennett and Stam data using the original dataset from Bennett and Stam (1996). Here, we reanalyze the data using Stata (the original analysis was performed in Limdep) so that we can report robust standard errors. We present significantly more data about model fit in Table 1 than in the original paper. We include the mean error, mean and median absolute error, and the standard deviation of those errors. Importantly, we report corrected estimates of error as a percentage of war length. We report full information for a naïve prediction model, which is the basis for all likelihood-ratio tests of the various component models, and the basis for all PRE assessments. Importantly, the new table adds information on our newly computed “proportional reduction in error” values based on absolute errors and error/actual duration. A new Stata command file for prediction is available on the authors’ websites.1 So how does the final complete model actually perform? Substantially better than any of the baseline (naïve, constant-only), regime-only, or realpolitik only models. Nevertheless, there is still room for substantial improvement in the models’ forecasts of war duration. The mean prediction error indicates that the model systematically underestimates the length of wars. Focusing on the complete model (model 4), on average, we under-predict the length of wars by about 3 months (-3.2). This appears much better than the average error from a naïve model (model 1, which predicts essentially the mean duration) of -9.6 months. This figure alone is somewhat misleading, however, as over- and under-estimates of duration cancel out in this mean. Focusing on the mean of the absolute error in each war, we find that the most complete model yields a mean absolute error of 11 months, with the median absolute error being 4.5 months. The naïve model makes predictions that are off on average nearly 14 months. The standard deviation of the absolute errors is quite high, however, at almost 17 months in model 4, indicating significant skew in the error distribution. This mirrors the significant skew in the underlying data. A majority of the model’s predictions fall closer than 11 months to each case’s true duration, but the model makes some quite large errors. When we look at the mean absolute error as a percentage of war length, we see errors larger than reported in the original article. These range from 326% in the complete TVC model to 997% in the naïve model. To provide some context, an error of 997% would mean that the absolute error is on average nearly ten times the true duration of the war on average. This could occur if the true duration of a war was 1 month and the prediction was 10 months, or if the true duration was 24 months but the model predicted 240. As discussed above, this measure is misleadingly high, because if the prediction was 2 months and the true duration was 3 months, the 1 month error would yield a proportional error of 33%, while a prediction of 3 months given a 2 month reality would yield a proportional error of 150%. But even given the misleadingly high values, we see that the complete models (TVC or non-TVC) yield much lower error rates as a percentage of war length than the naïve or component models. In the complete model, the prediction error is (on average) 3.3 times the actual length of the war. The complete model is clearly an improvement over both the baseline naïve model as well as the other simpler ones. We can now examine just how much using our new PRE 1 Two other minor changes have improved the replication data code. First, the original article reported that the “repression” measure was multiplied by -1 in order to get the valence of the effect correct. However, the previouslyreleased replication data set had not actually multiplied repression by -1, and as a result, the straight coefficient generated from the replication data set had the incorrect sign. The new prediction command file now includes appropriate code to make this switch. Second, the replication data set had scaled total population and total military personnel differently than when the data were used to produce the original Table 1. The new prediction command file includes appropriate rescaling for these variables. measures of duration error. Starting with the final predictions, the complete model estimated on the data with time-varying covariates has a PRE in absolute error terms of.201. This indicates a 20% reduction in total error from the complete model relative to a naïve model prediction. In detail, there are 1079 months of error from the naïve model. There are 861 months of error in the predictions made by the complete model. The reduction of 218 error-months is 20.1% of 1079. If we look at the reduction in error as a proportion of actual war duration, we reduce error by 67% in the complete model. If we also look at the separate component models, each reduces prediction error from the naïve model, but the regime model does so just barely. It yields an error reduction much less than 1% in absolute terms, and half of the improvement of the complete model in terms of error/duration. The realpolitik model (which has all but the regime variables) reduces absolute error by 13.6% (PRE .136), although the PRE in terms of error/duration of .646 is quite close to the 0.673 reduction of the complete model. The complete model yields a clearly superior reduction in absolute error at 20%. Note that this is the largest absolute PRE by far of the models, even though the improvement in the average error as a percentage of war length dropped only from 353% to 326% compared to the realpolitik model (that small reduction explains the closeness of PRE in terms of error/duration). Clearly, there remains much variation in war duration to explain. But at the same time, the complete model with TVCs is clearly the best model of those explored here in terms of making predictions of duration. Not only does it yield a significant increase in likelihood (via likelihood-ratio tests), but it yields a sizable improvement in error reduction. The reductions are quite similar in the model without TVCs. Conclusions In this paper, we have revisited the predictions of war duration from Bennett and Stam (1996), correcting some prior errors and introducing a new proportional reduction in error measure. This measure allows us to better assess how well different econometric models are doing at predicting war duration. Clearly, the full statistical model is an improvement over naïve or any component models, and a 20% reduction in error is significant. But while individual hypothesis tests indicate that the individual parameters are statistically significant, and likelihood ratio tests indicated that the overall model provides a statistically significant improvement in fit to the data versus the null, much of the variation in war duration clearly remains to be explained in ongoing work. A PRE measure that avoids some of the issues with the measures used previously is a new tool we can use as we seek better prediction and explanation when it comes to understanding war duration. Bibliography Bennett D. Scott, and Allan C. Stam. 2006. “Predicting the Length of the 2003 US-Iraq War: A Postwar Assessment.” Foreign Policy Analysis 2 (April):101-115. Bennett, D. Scott, and Allan Stam. 1996. “The Duration of Interstate Wars, 1816-1985.” American Political Science Review 90:239-257. Clodfelter, Michael. 1992. Warfare and Armed Conflicts 2 vols. Jefferson, NC: McFarland and Co. Dupuy, R. Ernest, and Trevor N. Dupuy. 1986. The Encyclopedia of Military History From 3500 BC to the Present. 2nd revised edition. New York: Harper and Row, 1986 Filson, Darren, and Suzanne Werner. 2004. “Bargaining and Fighting: The Impact of Regime Type on War Onset, Duration, and Outcomes.” American Journal of Political Science 48 (2): 296–313. Filson, Darren, and Suzanne Werner. 2002. “A Bargaining Model of War and Peace: Anticipating the Onset, Duration, and Outcome of War.” American Journal of Political Science 46 (4): 819-837. Langlois, Catherine, and Jean-Pierre Langlois. 2008. “Does Attrition Behavior Help Explain the Duration of Interstate Wars?” Manuscript. Slantchev, Branislav L. 2004. “How Initiators End Their Wars: The Duration of Warfare and the Terms of Peace.” American Journal of Political Science 48 (4): 813–829. Stam, Allan C. III. 1996. Win, Lose or Draw: Domestic Politics and the Crucible of War. Ann Arbor: University of Michigan Press. Note: We would like to thank Professor Catherine Langlois, Georgetown University, for bringing to our attention the mistake in computing error as a percentage of war length, and for useful conversations concerning PRE. Table 1. Revised and Expanded War Duration Hazard Model Coefficient and Prediction Estimates Model N1 Naïve model TVC Model 1 VT model, TVC 2.39 (0.193)** 2.48 (0.678) Model 2 Realpolitik, TVC Model 3 Regime, TVC Model 4 Complete, TVC 1.75 (0.634) 2.252 (1.165) Model N2 Naïve model non-TVC Model 5 Complete, non-TVC Variable Constant 2.46 (1.10) 2.358 (0.197) Realpolitik Strategy: OADM Strategy: OADA Strategy: OADP Strategy: OPDA Terrain Terrain x Strategy Balance of Forces Total Mil. Personnel Total Population Population Ratio Quality Ratio Surprise Salience -------------- Regime Repression -- -- -- -0.281 (0.180)** -0.200 (0.111) -- Democracy -- -- -- -0.130 (0.080)** -0.100 (0.053) -- Other Approaches Previous Disputes Number of States Year p (duration param.) Log-Likelihood Mean Error (months) ---0.629 (0.044) -157.55 -9.6 ----------0.024 (0.014) ---- -0.064 (0.077) -0.001 (0.004) 0.629 (0.046) -156.38 -9.5 2.484 (0.531)** 3.254 (0.510)** 7.016 (1.418)** 11.596 (2.454)** 6.618 (2.971)* -2.026 (0.785)** -5.027 (1.276)** 0.061(0.027)** 0.751(0.625) 0.001 (0.011) 0.013 (0.011) -0.123 (0.651) 0.336 (0.231) ---0.907 (0.074) -127.49 -3.1 -------------- ---0.629 (0.045) -155.86 -9.4 2.759 (0.507)** 3.203 (0.496)** 6.285 (1.417)** 10.991 (2.323)** 5.062 (2.865) -1.703 (0.746)* -4.756 (1.225)** 0.124 (0.037)** 0.707 (0.540) 0.007 (0.012) 0.010 (0.009) -0.203 (0.524) 0.420 (0.201)* -0.008 (0.053) -0.190 (0.092)* -0.965 (0.082) -124.83 -3.2 -------------- 1.264 (1.202) 2.874 3.330 6.283 7.990 2.987 -1.242 -3.981 0.273 0.162 0.007 0.001 -0.219 0.427 (0.588)** (0.638)** (1.771)** (2.587)** (3.552) (0.939) (1.233)** (0.125)* (0.791) (0.015) (0.001) (0.652) (0.212)* -0.246 (0.127) -0.118 (0.059)* ---0.621 (0.043) 0.016 (0.059) -0.135 (0.100) -0.942 (.074) -156.2 -9.7 -126.1 -4.2 SD of Mean Error 24.8 24.8 21.4 24.7 19.9 24.9 18.7 Mean Abs. Error 13.8 13.7 11.9 13.8 11.0 13.8 11.1 SD of Abs. Error 22.7 22.7 18.0 22.5 16.8 22.9 15.6 Median Error 1.1 0.9 0.04 .48 -0.3 0.9 0.0006 Median Abs. Error 5.1 4.8 4.6 4.1 4.5 4.9 4.4 Mean Abs. Error as 997% 879% 353% 667% 326% 929% 286% % of War Length 0 0.007 0.136 0.0002 0.201 0 0.195 PRE (abs. error) 0 0.118 0.646 0.331 0.673 0 0.692 PRE (abs. error as % length) Number of Wars 78 78 78 78 78 77 77 No. of Data Points 169 169 169 169 169 77 77 (War-Years) * p < 0.05 ** p < 0.01 Notes: Robust standard errors in parentheses. Significance tests are two-tailed. TVC indicates “time-varying covariate” model, vs. the non-TVC model with one observation per war.