confidence interval estimation
advertisement

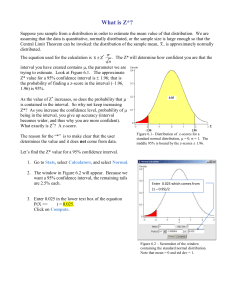
CHAPTER 20 CONFIDENCE INTERVAL ESTIMATION MULTIPLE CHOICE QUESTIONS In the following multiple-choice questions, please circle the correct answer. 1. The confidence interval for a proportion is based on the assumption of a large sample size. A rule of thumb for checking the validity of this assumption is if npL , n(1 pL ), npU , and n(1 pU ) are all greater than what value? a. 0 b. n c. 2 d. 3 e. 5 ANSWER: 2. e When the samples we want to compare are paired in some natural way, such as pretest/posttest for each person or husband/wife pairs, a more appropriate form of analysis is to not compare two separate variables, but their . a. difference b. sum c. ratio d. total e. product ANSWER: a 3. 4. Confidence intervals are a function of which of the following three things? a. The population, the sample, and the standard deviation b. The sample, the variable of interest, and the degrees of freedom c. The data in the sample, the confidence level, and the sample size d. The sampling distribution, the confidence level, and the degrees of freedom e. The mean, the median, and the mode ANSWER: c The chi-square and F distributions are used primarily to make inferences about population ___________. a. means b. variances c. medians d. modes e. proportions ANSWER: b 5. If you increase the confidence level, the confidence interval . a. decreases b. increases c. stays the same d. may increase or decrease, depending on the sample data ANSWER: b 6. A random sample allows us to use: a. the rules of probabilities b. the rules of large numbers c. the laws of parameters d. the laws of distributions e. the laws of gravity ANSWER: a 7. Suppose there are 500 accounts in a population. You sample 50 of them and find a sample total of $5,000. What would be your estimate for the population total? a. $5,000 b. $50,000 c. $250,000 d. $2,500,000 e. None of the above ANSWER: b 8. 9. Suppose there are 400 accounts in a population. You sample 50 of them and find a sample mean of $500. What would be your estimate for the population total? a. $5,000 b. $50,000 c. $250,000 d. $2,500,000 e. None of the above ANSWER: b When we replace with the sample standard deviation (s), we introduce a new source of variability and the sampling distribution becomes the . a. t distribution b. F distribution c. chi-square distribution d. robust distribution ANSWER: a 10. Another commonly used random mechanism, besides a simple random sample, is called: a. interval estimation b. a random hypothesis test c. a randomized experiment d. a nuisance sample ANSWER: c 11. If the odds of a horse winning a race are 2 to 1, then the probability of this horse winning the race is . a. 1/4 b. 1/3 c. 1/2 d. 2/3 e. 2/10 ANSWER: 12. d There are, generally speaking, two types of statistical inference. They are: a. sample estimation and population estimation b. confidence interval estimation and hypothesis testing c. interval estimation for a mean and interval estimation for a proportion d. independent sample estimation and dependent sample estimation e. none of the above ANSWER: b 13. The t distribution has a. n b. 2 c. 10 d. n – 1 e. trillion ANSWER: 14. degrees of freedom. d If you are constructing a confidence interval for a single mean, the confidence interval will with an increase in the sample size. a. decreases b. increases c. stays the same d. may increase or decrease, depending on the sample data ANSWER: a 15. As the sample size increases, the t distribution becomes more similar to the __ distribution. a. b. c. d. e. normal exponential F chi-square binomial ANSWER: 16. a A parameter, such as , is sometimes referred to as a ________ parameter, because many times we need its value even though it is not the parameter of primary interest. a. special b. random c. nuisance d. independent e. dependent ANSWER: c 17. When you calculate the sample size for a proportion, you use an estimate for the population proportion ( pest ). A conservative value for n can be obtained by using pest = . a. 0.0 b. 0.05 c. 0.10 d. 0.50 e. 1.00 ANSWER: d QUESTIONS 18 THROUGH 23 ARE BASED ON THE FOLLOWING INFORMATION: The following values have been calculated using the TDIST and TINV functions in Excel. These values come from a t distribution with 15 degrees of freedom. These values represent the probability to the right of the given positive values. Value 1.00 1.20 1.40 t probability 0.1636 0.1209 0.0872 These values represent the t value for a given probability. Probability 0.20 0.10 0.05 t value 1.3178 1.7109 2.0639 18. What is the probability of a t-value smaller 1.00? a. 0.1209 b. 0.1636 c. 0.8364 d. 0.8791 ANSWER: 19. What is the probability of a t-value larger than 1.20? a. 0.0872 b. 0.1209 c. 0.1636 d. 0.2000 ANSWER: 20. b What would be the t-value where 0.05 of the values are in the upper tail? a. +1.000 b. +1.318 c. +1.711 d. +2.064 ANSWER: 22. b What is the probability of a t-value between –1.40 and +1.40? a. 0.7582 b. 0.8256 c. 0.9128 d. 0.9500 ANSWER: 21. c c What would be the t-values where 0.10 of the values are in both tails (sum of both tails)? a. –1.000, +1.000 b. –1.318, +1.318 c. –1.711, +1.711 d. –2.064, +2.064 ANSWER: c 23. What would be the t-values where 0.95 of the values would fall within this interval? a. b. c. d. –1.000, +1.000 –1.318, +1.315 –1.711, +1.711 –2.064, +2.064 ANSWER: d QUESTIONS 24 THROUGH 29 ARE BASED ON THE FOLLOWING INFORMATION: The following values have been calculated using the TDIST and TINV functions in Excel. These values come from a t distribution with 15 degrees of freedom. These values represent the probability to the right of the given positive values. Value 0.95 1.15 1.20 t probability 0.1786 0.1341 0.1244 These values represent the t value for a given probability. Probability 0.20 0.15 0.10 24. What is the probability of a t-value smaller than 1.20? a. 0.8756 b. 0.8659 c. 0.1341 d. 0.1244 ANSWER: 25. b What is the probability of a t-value between –0.95 and +0.95? a. 0.1786 b. 0.3572 c. 0.6428 d. 0.8214 ANSWER: 27. a What is the probability of a t-value larger than 1.15? a. 0.1786 b. 0.1341 c. 0.1244 d. 0.1500 ANSWER: 26. t value 1.341 1.517 1.753 c What would be the t-value where 0.075 of the values are in the upper tail? a. +1.000 b. +1.341 c. +1.517 d. +1.753 ANSWER: 28. c What would be the t-values where 0.80 of the values would fall within this interval? a. –1.000, +1.000 b. –1.341, +1.341 c. –1.517, +1.517 d. –1.753, +1.753 ANSWER: b 29. What would be the t-values where 0.10 of the values are in both tails (sum of both tails)? a. –1.000, +1.000 b. –1.341, +1.341 c. –1.517, +1.517 d. –1.753, +1.753 ANSWER: d TEST QUESTIONS 30. You are told that a random sample of 150 people from Iowa has been given cholesterol tests, and 60 of these people had levels over the “safe” count of 200. Construct a 95% confidence interval for the population proportion of people in Iowa with cholesterol levels over 200. ANSWER: n 150, pˆ 60 /150 .40 pˆ Z pˆ (1 pˆ ) / n 0.40 1.96 (.40)(.60) /150 0.40 0.0784 Lower limit = 0.3216, and upper limit = 0.4784 31. You are trying to estimate the average amount a family spends on food during a year. In the past, the standard deviation of the amount a family has spent on food during a year has been approximately $1200. If you want to be 99% sure that you have estimated average family food expenditures within $60, how many families do you need to survey? ANSWER: est . =1200, z-multiple = 2.575, B = 60 . The sample size for a mean is given by z multiple est 2.575 1200 n B 60 2 32. 2 2653 You have been assigned to determine whether more people prefer Coke to Pepsi. Assume that roughly half the population prefers Coke and half prefers Pepsi. How large a sample would you need to take to ensure that you could estimate, with 95% confidence, the proportion of people preferring Coke within 3% of the actual value? ANSWER: pest . = 0.50, z-multiple = 1.96, B = 0.03. The sample size for a proportion is given by z multiple 1.96 n pest . (1 pest . ) (0.50)(0.50) 1068 B 0.03 2 2 QUESTIONS 33 THROUGH 35 ARE BASED ON THE FOLLOWING INFORMATION: A marketing research consultant hired by Coca-Cola is interested in determining the proportion of customers who favor Coke over other soft drinks. A random sample of 400 consumers was selected from the market under investigation and showed that 53% favored Coca-Cola over other brands. 33. Compute a 95% confidence interval for the true proportion of people who favor Coke. Do the results of this poll convince you that a majority of people favors Coke? ANSWER: 0.53 0.0489 = (0.4811, 0.5789). Since confidence interval ranges from 48% to 57.9%, it is difficult to conclude that a majority of people favors Coke. It could be below 50%. 34. Suppose 2,000 (not 400) people were polled and 53% favored Coke. Would you now be convinced that a majority of people favor Coke? Why might your answer be different than in Question 33? ANSWER: 0.53 0.0219 = (0.5081, 0.5519). In this case the 95% confidence interval is entirely above 50%, the data is now more convincing than it was previously. 35. How many people would have to be surveyed to be 95% confident that you can estimate the fraction of people who favor Coca-Cola within 1%? ANSWER: 9,569.43 or 9,570. QUESTIONS 36 AND 37 ARE BASED ON THE FOLLOWING INFORMATION: The employee benefits manager of a medium size business would like to estimate the proportion of full-time employees who prefer adopting plan A of three available health care plans in the coming annual enrollment period. A reliable frame of the company’s employees and their tentative health care preferences are available. Using Excel, the manager chose a random sample of size 50 from the frame. There were 17 employees in the sample who preferred plan A. 36. Construct a 99% confidence interval for the proportion of company employees who prefer plan A. Assume that the population consists of the preferences of all employees in the frame. ANSWER: n 50, pˆ 17 / 50 0.34 pˆ Z pˆ (1 pˆ ) / n 0.34 2.575 (0.34)(0.66) / 50 0.34 0.1725 lower limit = 0.1675, upper limit = 0.5125 37. Interpret the 99% confidence interval constructed in Question 36. ANSWER: We are 99% confident that the proportion of all employees who prefer plan A is between 0.1675 and 0.5125. QUESTIONS 38 THROUGH 40 ARE BASED ON THE FOLLOWING INFORMATION: Q-Mart is interested in comparing its male and female customers. Q-Mart would like to know if its female charge customers spend more money, on average, than its male charge customers. They have collected random samples of 25 female customers and 22 male customers. On average, women charge customers spend $102.23 and men charge customers spend $86.46. Some information are shown below. Summary statistics for two samples Sample sizes Sample means Sample standard deviations Female 25 102.23 93.393 Male 22 86.46 59.695 Confidence interval for difference between means Sample mean difference Pooled standard deviation Std error of difference 38. 15.77 79.466 23.23 Using a t-value of 2.014, calculate a 95% confidence interval for the difference between the average female purchase and the average male purchase. Would you conclude that there is a significant difference between females and males in this case? Explain. ANSWER: 15.77 46.785 = (-31.015, 62.555). Since the range includes 0, there does not appear to be a significant difference between the means of the two groups. 39. What are the degrees of freedom for the t-statistic in this calculation? Explain how you would calculate the degrees of freedom in this case. ANSWER: n1 + n2 – 2 = 45 40. What is the assumption in this case that allows you to use the pooled standard deviation for this confidence interval? ANSWER: In order to use the pooled standard deviation for this confidence interval, we must assume that the two populations standard deviations are equal ( 1 2 ). QUESTIONS 41 AND 42 ARE BASED ON THE FOLLOWING INFORMATION: A company employs two shifts of workers. Each shift produces a type of gasket where the thickness is the critical dimension. The average thickness and the standard deviation of thickness for shift 1, based on a random sample of 40 gaskets, are 10.85 mm and 0.16 mm, respectively. The similar figures for shift 2, based on a random sample of 30 gaskets, are 10.90 mm and 0.19 mm. Let 1 2 be the difference in thickness between shifts 1 and 2, and assume that the population variances are equal. 41. Construct a 95% confidence interval for 1 2 . ANSWER: n1 40, X1 10.85, s1 0.16 n2 30, X 2 10.90, s2 0.19 The pooled standard deviation is s p ( X1 X 2 ) t s p 1 n1 (n1 1) s12 (n2 1) s22 = 0.1734 n1 n2 2 n12 0.05 1.9955(0.1734)(0.2415) 0.05 0.0836 Lower limit = -0.1336, and upper limit = 0.0336. 42. Based on your answer to Question 41, are you convinced that the gaskets from shift 2 are, on average, wider than those from shift 1? Why or why not? ANSWER: The confidence interval extends from a negative number (indicating shift 2 thickness is larger) to a positive number (indicating shift 2 thickness is smaller). So we are not absolutely sure which mean is greater. QUESTIONS 43 AND 44 ARE BASED ON THE FOLLOWING INFORMATION: A sample of 9 production managers with over 15 years of experience has an average salary of $71,000 and a sample standard deviation of $18,000. 43. You can be 95% confident that the mean salary for all production managers with at least 15 years of experience is between what two numbers (the t-statistic with 8 degrees of freedom is 2.306)? What assumption are you making about the distribution of salaries? ANSWER: $71,000 $13,836 = ($57,164, $84,836). The assumption is that the population is normal or near normal. This is particularly important since the sample size is so small (9). However, the t distribution is rather robust to violations of normality. 44. What sample size would be needed to ensure that we could estimate the true mean salary of all production managers with more than 15 years of experience and have only 5 chances in 100 of being off by more than $600? ANSWER: 69.18 or 70 QUESTIONS 45 THROUGH 50 REQUIRE THE USE OF EXCEL: 45. Compute P(1.50 t10 1.00), where t10 has a t-distribution with 10 degrees of freedom. ANSWER: 0.74730 46. Compute P(1.50 t100 1.00), where t100 has a t-distribution with 100 degrees of freedom. ANSWER: 0.77176 47. Compute P(1.50 Z 1.00), where Z is a standard normal random variable. ANSWER: 0.77454 48. Compare the result of Question 47 to the results obtained in Questions 45 and 46. How do you explain the difference in these probabilities? ANSWER: The variance of t with a small degree of freedom is larger than a t with a large degree of freedom, which is larger than for a Z. This explains why the “between” probabilities in Questions 45, 46, and 47 increase. 49. Find the 75th percentile of the t-distribution with 25 degrees of freedom. ANSWER: 0.32217 50. Find the 75th percentile of the t-distribution with 5 degrees of freedom. ANSWER: 0.33672 QUESTIONS 51 and 52 ARE BASED ON THE FOLLOWING INFORMATION: A sample of 40 country CD recordings of Willie Nelson has been examined. The average playing time of these recordings is 51.3 minutes, and the standard deviation is 5.8 minutes. 51. Construct a 95% confidence interval for the mean playing time of all Willie Nelson recordings. ANSWER: n = 10, X = 54000, s = 15000 X t (s / n) 51.3 2.0227(5.8/ 40) 51.3 1.855 Lower limit = 49.445, and upper limit = 53.155 52. Interpret the confidence interval you constructed. ANSWER: We are 95% confident that the mean playing time of all Willie Nelson recordings is between. 49.445 and 53.155 minutes. QUESTIONS 53 AND 54 ARE BASED ON THE FOLLOWING INFORMATION: A department store is interested in the average balance that is carried on its store’s credit card. A sample of 40 accounts reveals an average balance of $1,250 and a standard deviation of $350. 53. Find a 95% confidence interval for the mean account balance on this store’s credit card (the t-statistic with 39 degrees of freedom is 2.02). ANSWER: $1,250 $111.79 = ($1,138.21, $1,361.79). 54. What sample size would be needed to ensure that we could estimate the true mean account balance and have only 5 chances in 100 of being off by more than $100? ANSWER: 49.98 or 50. QUESTIONS 55 AND 56 ARE BASED ON THE FOLLOWING INFORMATION: A market research consultant hired by Coke Classic Company is interested in estimating the difference between the proportions of female and male customers who favor Coke Classic over Pepsi Cola in Chicago. A random sample of 200 consumers from the market under investigation showed the following frequency distribution. Coke Pepsi 55. Male 72 58 130 Female 38 32 70 110 90 200 Construct a 95% confidence interval for the difference between the proportions of male and female customers who prefer Coke Classic over Pepsi Cola. ANSWER: n1 number of males = 130, n 2 = number of females = 70 Pˆ1 proportion of males who favor Coke over Pepsi = 72/130 = 0.5538 Pˆ proportion of females who favor Coke over Pepsi = 0.5429 2 SE ( pˆ1 pˆ 2 ) pˆ1 (1 pˆ1 ) pˆ 2 (1 pˆ 2 ) = 0.0738 n1 n2 ( Pˆ1 Pˆ2 ) Z SE ( Pˆ1 Pˆ2 ) 0.0109 1.96(.0738) 0.0109 0.1446 Lower limit = -0.1337, and upper limit = 0.1555 56. Interpret the constructed confidence interval. ANSWER: We are 95% confident that the population difference between these proportions is between –13.37% and 15.55%. QUESTIONS 57 THROUGH 60 ARE BASED ON THE FOLLOWING INFORMATION: The percent defective for parts produced by a manufacturing process is targeted at 4%. The process is monitored daily by taking samples of sizes n = 160 units. Suppose that today’s sample contains 14 defectives. 57. 58. Determine a 95% confidence interval for the proportion defective for the process today. ANSWER: 0.0875 0.0438 = (0.0437, 0.1313). Based on your answer to Question 57, is it still reasonable to think the overall proportion defective produced by today’s process is actually the targeted 4%? Explain your reasoning. ANSWER: No, since 4% falls outside of this range. 59. The confidence interval in Question 57 is based on the assumption of a large sample size. Is this sample size sufficiently large in this example? Explain how you arrived at your answer. ANSWER: Yes. Because npL , n(1 pL ), npU , and n(1 pU ) are all greater than 5.0. 60. How many units would have to be sampled to be 95% confident that you can estimate the fraction of defective parts within 2% (using the information from today’s sample)? ANSWER: 766.40 or 767. QUESTIONS 61 AND 62 ARE BASED ON THE FOLLOWING INFORMATION: Auditors of Independent Bank are interested in comparing the reported value of all 1775 customer saving account balances with their own findings regarding the actual value of such assets. Rather than reviewing the records of each savings account at the bank, the auditors randomly selected a sample of 100 savings account balances from the frame. The sample mean and sample standard deviations were $505.75 and 360.95, respectively. 61. Construct a 90% confidence interval for the total value of all savings account balances within this bank. Assume that the population consists of all savings account balances in the frame. ANSWER: N 1775, n 100, X 505.75, s 360.95 NX 1.6604( Ns / n ) 1775(505.75) 1.6604(1775 360.95 / 100) 897706.25 106379.55 = ($719,326.70, $1,004,085.8) 62. Interpret the 90% confidence interval constructed in Question 61. ANSWER: We are 90% confident that the total balance of all 1775 savings account balances within the bank are between $791,327 and $1,004,086. QUESTIONS 63 AND 64 ARE BASED ON THE FOLLOWING INFORMATION: A real estate agent has collected a random sample of 40 houses that were recently sold in Grand Rapids, Michigan. She is interested in comparing the appraised value and recent selling price (in thousands of dollars) of the houses in this particular market. The values of these two variables for each of the 40 randomly selected houses are shown below. House 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Value 140.93 132.42 118.30 122.14 149.82 128.91 134.61 121.99 150.50 142.87 155.55 128.50 143.36 119.65 122.57 145.27 149.73 147.70 117.53 140.13 Price 140.24 129.89 121.14 111.23 145.14 139.01 129.34 113.61 141.05 152.90 157.79 135.57 151.99 120.53 118.64 149.51 146.86 143.88 118.52 146.07 House 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 Value 136.57 130.44 118.13 130.98 131.33 141.10 117.87 160.58 151.10 120.15 133.17 140.16 124.56 127.97 101.93 131.47 121.27 143.55 136.89 106.11 Price 135.35 121.54 132.98 147.53 128.49 141.93 123.55 162.03 157.39 114.55 139.54 149.92 122.08 136.51 109.41 127.29 120.45 151.96 132.54 114.33 63. Using the sample data, generate a 95% confidence interval for the mean difference between the appraised values and selling prices of the houses sold in Grand Rapids. ANSWER: We applied the paired sample analysis using n 40, X D 1.612, sD 6.794 , where: D = Difference = Appraised value – selling price. X D t (sD / n) 1.612 2.0227(6.794 / 40) 1.612 2.173 Lower limit = -3.785, and Upper limit = 0.561 (in thousands of dollars) 64. Interpret the constructed confidence interval for the real estate agent. ANSWER: We are 95% confident that the actual mean difference between the appraised values and selling prices of all the houses sold in Grand Rapids is between -$3785 and $561. QUESTIONS 65 THROUGH 69 REQUIRE THE USE OF EXCEL: 65. Compute P(t15 2.0), where t15 has a t-distribution with 15 degrees of freedom. ANSWER: 0.03197 66. Compute P(t150 2.0), where t150 has a t-distribution with 150 degrees of freedom. ANSWER: 0.02365 67. How do you explain the difference between the results obtained in Questions 65 and 66? ANSWER: The smaller the degrees of freedom, the higher the variance of t, and so the larger the tail probabilities are. 68. Compute P( Z 2.0), where Z is a standard normal random variable. ANSWER: 0.02275 69. Compare the results of Question 68 to the results obtained in Questions 65 and 66. How do you explain the difference in these probabilities? ANSWER: First, the variance of t with a small degree of freedom is larger than a t with a large degree of freedom, which is larger than for a Z. This explains why the probabilities in Questions 65, 66, and 68 increases. Second, when the sample size is large, the degrees of freedom of t are large; and that the t distribution and the standard normal distribution are practically indistinguishable. This explains why the probabilities in Questions 66 and 68 are close. QUESTIONS 70 THROUGH 72 ARE BASED ON THE FOLLOWING INFORMATION: Senior management of a consulting services firm is concerned about a growing decline in the firm’s weekly number of billable hours. The firm expects each professional employee to spend at least 40 hours per week on work. In an effort to understand this problem better, management would like to estimate the standard deviation of the number of hours their employees spend on work-related activities in a typical week. Rather than reviewing the records of all the firm’s full-time employees, the management randomly selected a sample of size 50 from the available frame. The sample mean and sample standard deviations were 48.5 and 7.5 hours, respectively. 70. Construct a 99% confidence interval for the standard deviation of the number of hours this firm’s employees spend on work-related activities in a typical week. ANSWER: n 50, X 48.5, s 7.5 71. Lower limit = n 1s / 2 / 2 49(7.5) / 78.2305 =5.936 Upper limit = n 1s / 12 / 2 49(7.5) / 27.2494 10.057 Interpret the 99% confidence interval constructed in Question 70. ANSWER: We are 99% confident that the population standard deviation is between 5.936 and 10.057. 72. Given the target range of 40 to 60 hours of work per week, should senior management be concerned about the number of hours their employees are currently devoting to work? Explain why or why not. ANSWER: The best guess for the population mean is 48.5 hours per week, and about 95% of all employees are within 2 standard deviations of this, where we are almost sure (99% sure) that this standard deviation is between 5.9 and 10.1. But even if the standard deviation is only 5.9, then 48.5 2 standard deviations will produce the range 36.7 to 60.3. Maybe management should be concerned. QUESTIONS 73 THROUGH 75 REQUIRE THE USE OF EXCEL: 73. Compute P(t20 0.95), where t20 has a t-distribution with 20 degrees of freedom. ANSWER: Because of the symmetry of the t distribution, this left-hand tail probability can be calculated exactly like right-hand tail. The answer is 0.17673. 74. Compute P(t2 0.95), where t2 has a t-distribution with 2 degrees of freedom. ANSWER: Because of the symmetry of the t distribution, this left-hand tail probability can be calculated exactly like right-hand tail. The answer is 0.22119. 75. How do you explain the difference between the results obtained in Questions 73 and 74? ANSWER: The larger the degrees of freedom, the lower the variance of t, so the smaller the tail probabilities are. This explains why the probability in Question 73 is smaller than that in Question 74. QUESTIONS 76 AND 77 ARE BASED ON THE FOLLOWING INFORMATION: A sample of 10 quality control managers with over 15 years of experience has an average salary of $54,000 and a standard deviation of $15,000. 76. You can be 95% confident that the mean salary for all quality control managers with at least 15 years of experience is between what two numbers? What assumptions are you making about the distribution of salaries? ANSWER: n = 10, X = 54000, s = 15000 X t (s / n) 54000 2.2622(15000 / 10) 54000 10730.557 Lower limit = 43,269.443, and upper limit = 64,730.557 We must assume that the population distribution of salaries is normal, especially since the sample size is so small. 77. What size sample would be needed to ensure that we could estimate the true mean salary of all quality control managers with more than 15 years of experience and have only 2 chances in 100 of being off by more than $800? ANSWER: est . =15000, z-multiple = 2.326, B = 800 The approximate sample size required to produce a 98% confidence interval for the mean is given by z multiple est 2.326 15000 n B 800 2 2 1903 QUESTIONS 78 THROUGH 80 ARE BASED ON THE FOLLOWING INFORMATION: Q-Mart is interested in comparing customer who used its own charge card with those who use other types of credit cards. Q-Mart would like to know if customers who use the QMart card spend more money per visit, on average, than customers who use some other type of credit card. They have collected information on a random sample of 38 charge customers and the data is presented below. On average, the person using a Q-Mart card spends $192.81 per visit and customers using another type of card spend $104.47 per visit. Use the information below to answer the following questions. Summary statistics for two samples Q-Mart Sample sizes 13 Sample means 192.81 Sample standard deviations 115.243 Other Charges 25 104.47 71.139 Confidence interval for difference between means Sample mean difference Pooled standard deviation Std error of difference 78. 88.34 88.323 30.201 Using a t-value of 2.023, calculate a 95% confidence interval for the difference between the average Q-Mart charge and the average charge on another type of credit card. Would you conclude that there is a significant difference between the two types of customers in this case? Explain. ANSWER: 88.34 61.0966 = +27.2434 – +149.4366. Since the range does not include 0, there appears to be a significant difference between the means of the two groups. In this case, it appears as though the Q-Mart charge card holders spend more money than those who use other types of charge cards. 79. What are the degrees of freedom for the t-statistic in this calculation? Explain how you would calculate the degrees of freedom in this case. ANSWER: n1 + n2 – 2 = 36 80. What is the assumption in this case that allows you to use the pooled standard deviation for this confidence interval? ANSWER: In order to use the pooled standard deviation for this confidence interval, we must assume that the two populations standard deviations are equal ( 1 2 ). QUESTIONS 81 THROUGH 84 ARE BASED ON THE FOLLOWING INFORMATION: The average annual household income levels of citizens of selected U.S. cities are shown below. City Index 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 81. Household Income $54,300 $61,800 $61,400 $50,800 $56,200 $48,300 $61,600 $63,200 $55,200 $58,000 $77,600 $47,600 $62,700 $46,200 $64,300 $56,000 $53,400 $56,800 $51,200 $59,000 City Index 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 Household Income $53,500 $45,600 $70,100 $108,700 $46,400 $56,700 $59,100 $46,300 $52,900 $56,300 $67,300 $63,800 $70,600 $49,800 $51,300 $56,600 $49,600 $67,400 $53,700 $48,700 City Index 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 Household Income $61,500 $53,000 $51,000 $55,600 $51,600 $57,200 $54,300 $51,500 $53,500 $61,800 $44,800 $57,400 $48,100 $52,700 $57,400 $65,500 $59,600 $62,000 $49,700 $54,400 Use Excel to obtain a simple random sample of size 10 from this frame. ANSWER: I used StatPro’s Generate Random Samples to generate a sample of size 10, then used the VLOOKUP function to get the corresponding incomes. The following sample is obtained: City Index 50 14 4 56 48 49 8 11 38 52 Income 61,800 46,200 50,800 65.500 51,500 53,500 63,200 77,600 67,400 57,400 82. Using the sample generated in Question 81, construct a 95% confidence interval for the mean average annual household income level of citizens in the selected U.S. cities. Assume that the population consists of all average annual household income levels in the given frame. ANSWER: n 10, X 59, 490, s 9, 439.803 X 2.2622(s / n) 59, 490 2.2622(9, 439.803/ 10) 59, 490 6,752.9561 Lower limit = 52,737.0439, upper limit = 66,242.9561 83. Interpret the 95% confidence interval constructed in Question 82. ANSWER: We are 95% confident that the average of all incomes is between $52,737 and $66,243. 84. Does the 95% confidence interval contain the actual population mean? If not, explain why not. What proportion of many similarly constructed confidence intervals should include the true population mean value? ANSWER: This confidence interval easily captures the true population mean of $57,043. Approximately 95% of the confidence intervals constructed in this way should contain the true population mean. QUESTIONS 85 THROUGH 91 ARE BASED ON THE FOLLOWING INFORMATION: The personnel department of a large corporation wants to estimate the family dental expenses of its employees to determine the feasibility of providing a dental insurance plan. A random sample of 12 employees reveals the following family dental expenses (in dollars) for the year 2001. 115 370 250 85. Construct a 90% confidence interval estimate of the mean family dental expenses for all employees of this corporation. ANSWER: 93 540 225 177 425 318 182 275 228 86. What assumption about the population distribution must be made to answer Question 85? ANSWER: The population of dental expenses must be approximately normally distributed. 87. Interpret the 90% confidence interval constructed in question 85. ANSWER: We are 90% confident that the mean family dental expenses for all employees of this corporation is between $199.26 and $333.74. 88. Suppose you used a 95% confidence interval in Question 85. What would be your answer to Question 85? ANSWER: 89. Suppose the fourth value were 593 instead of 93. What would be your answer to Question 88? What effect does this change have on the confidence interval? ANSWER: The additional $500 in dental expenses, divided across the sample of 12, raises the mean by $41.67 and increases the standard deviation by nearly $18.20. The interval width increases over $23 in the process. 90. Construct a 90% confidence interval estimate for the standard deviation of family dental expenses for all employees of this corporation. ANSWER: 91. Interpret the 90% confidence interval constructed in question 90. ANSWER: We are 90% confident that the standard deviation for family dental expenses for all employees of this corporation is between 110.61 and 229.38. QUESTIONS 92 AND 93 ARE BASED ON THE FOLLOWING INFORMATION: An automobile dealer wants to estimate the proportion of customers who still own the cars they purchased six years ago. A random sample of 200 customers selected from the automobile dealer’s records indicates that 88 still own cars that were purchased six years earlier. 92. Construct a 95% confidence interval estimate of the population proportion of all customers who still own the cars they purchased six years ago ANSWER: pˆ (1– pˆ ) 0.44(0.56) = 0.44 0.0688 0.44 1.96 n 200 Lower limit = 0.3712, and upper limit = 0.5088 pˆ Z 93. How can the result in Question 92 be used by the automobile dealer to study satisfaction with cars purchased at the dealership? ANSWER: The dealer can infer that the proportion of all customers who still own the cars they purchased at the dealership 6 years earlier is somewhere between 03712 and 0.5088 with a 95% level of confidence. TRUE / FALSE QUESTIONS 94. The degrees of freedom for the t and chi-square distributions is a numerical parameter of the distribution that defines the precise shape of the distribution. ANSWER: 95. When all possible samples of size n are drawn from any population, then the sampling distribution of the sample mean X is approximately normal provided that n is reasonably large. ANSWER: 96. F The standard error of the sampling distribution of the sample proportion p̂ , when the sample size n = 50 and the population proportion p = 0.25, is 0.00375. ANSWER: 98. T The mean of the sampling distribution of the sample proportion p̂ , when the sample size n = 100 and the population proportion p = 0.58, is 58.0. ANSWER: 97. T F In developing a confidence interval for the population standard deviation , we make use of the fact that the sampling distribution of the sample standard deviation S is not the normal distribution or the t distribution, but rather a rightskewed distribution called the chi-square distribution, which (for this procedure) has n – 1 degrees of freedom. ANSWER: T 99. As a general rule, the normal distribution is used to approximate the sampling distribution of the sample proportion p̂ only if the sample size n is greater than 30. ANSWER: 100. In general, the paired-sample procedure is appropriate when the samples are naturally paired in some way and there is a reasonably large positive correlation between the pairs. In this case, the paired-sample procedure makes more efficient use of the data and generally results in narrower confidence intervals. ANSWER: 101. F A confidence interval is an interval estimate for which there is a specified degree of certainty that the actual value of the population parameter will fall within the interval. ANSWER: 106. T If two random samples of sizes 30 and 35 are selected independently from two populations whose means are 85 and 90, then the mean of the sampling distribution of the sample mean difference, X 1 X 2 , equals 5. ANSWER: 105. F If two random samples of size 40 each are selected independently from two populations whose variances are 35 and 45, then the standard error of the sampling distribution of the sample mean difference, X 1 X 2 , equals 1.4142. ANSWER: 104. F If a random sample of size 250 is taken from a population, where it is known that the population proportion p = 0.4, then the mean of the sampling distribution of the sample proportion p̂ is 0.60. ANSWER: 103. T If the standard error of the sampling distribution of the sample proportion p̂ is 0.0324 for samples of size 200, then the population proportion must be 0.30. ANSWER: 102. F T The 95% confidence interval for the population mean , given that the sample size n = 49 and the population standard deviation = 7, is X 1.96 . ANSWER: T 107. In order to construct a confidence interval estimate of the population mean , the value of must be given. ANSWER: 108. The interval estimate 18.5 2.5 was developed for a population mean when the sample standard deviation S was 7.5. Had S equaled 15, the interval estimate would be 37 5.0. ANSWER: 109. F The t-distribution and the standard normal distribution are practically indistinguishable as the degrees of freedom increase. ANSWER: 115. T The lower limit of the 95% confidence interval for the population proportion p, given that n = 300; and p̂ = 0.10 is 0.1339. ANSWER: 114. F The upper limit of the 90% confidence interval for the population proportion p, given that n = 100; and p̂ = 0.20 is 0.2658. ANSWER: 113. T In general, increasing the confidence level will narrow the confidence interval, and decreasing the confidence level widens the interval. ANSWER: 112. T A 90% confidence interval estimate for a population mean is determined to be 72.8 to 79.6. If the confidence level is reduced to 80%, the confidence interval for becomes narrower. ANSWER: 111. F We can form a confidence interval for the population total T by finding a confidence interval for the population mean in the usual way, and then multiplying each end point of the confidence interval by the population size N. ANSWER: 110. F T In determining the sample size n for estimating the population proportion p, a conservative value of n can be obtained by using 0.50 as an estimate of p. ANSWER: T 116. In developing confidence interval for the difference between two population means using two independent samples, we use the pooled estimate s p in estimating the standard error of the sampling distribution of the sample mean difference X 1 X 2 if the populations are normal with equal variances. ANSWER: T