Section 7.2
advertisement

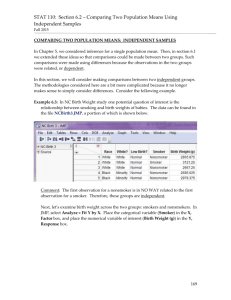
STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 COMPARING TWO POPULATION MEANS: INDEPENDENT SAMPLES In Chapter 6, we considered inference for a single population mean. Then, in section 7.1 we extended these ideas so that comparisons could be made between two groups. Such comparisons were made using differences because the observations in the two groups were related, or dependent. In this section, we will consider making comparisons between two independent groups. The methodologies considered here are a bit more complicated because it no longer makes sense to simply consider differences. Consider the following example. Example 7.3: In NC Birth Weight study one potential question of interest is the relationship between smoking and birth weights of babies. The data can be found in the file NCBirth3.JMP, a portion of which is shown below. Comment: The first observation for a nonsmoker is in NO WAY related to the first observation for a smoker. Therefore, these groups are independent. Next, let’s examine birth weight across the two groups: smokers and nonsmokers. In JMP, select Analyze > Fit Y by X. Place the categorical variable (Smoker) in the X, Factor box, and place the numerical variable of interest (Birth Weight (g)) in the Y, Response box. 162 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Questions: 1. Identify the following quantities from the JMP output on the previous page: Population Parameters Sample Statistics Group 1 Group 2 (Smokers) (Nonsmokers) Group 1 (Smokers) Group 2 (Nonsmokers) Mean μ1 μ2 x1 x2 Standard Deviation σ1 σ2 s1 = s2 = Variance 𝜎12 𝜎22 𝑠12 = 𝑠22 = n1 = n2 = # of Observations 163 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 2. We are interested in the true population difference between these two means, μ 1 μ 2 . Based on the data, what is your best guess for this difference, and what does it indicate about birth weights for smokers compared to nonsmokers? 3. If you were to take another sample, is your “best guess” from the previous question likely to change? Explain. Since the difference will change from sample to sample, it is considered a random variable and therefore has a sampling distribution. In order to make valid inferences about the true population difference, we must use the sampling distribution so that we can understand how the difference in sample means is expected to change from sample to sample. Characteristics of the Sampling Distribution for the Difference in Means As long as the samples are INDEPENDENT, the sampling distribution for the difference in means can be described as follows. 1. The sampling distribution is centered around μ1 – μ2. 2. The standard deviation of our sampling distribution (i.e., standard error) depends on whether the variances of the two groups are equal or unequal. If the variances are unequal, If the variances are equal, we pool we estimate each of them the variances and estimate them individually from our sample with a common value 2 data. (called s pooled ). Standard error s 12 s 22 n1 n 2 s 2pooled n1 s 2pooled n2 164 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 2 Note that the pooled variance, s pooled , is calculated as follows: s 2pooled (n 1 1)s12 (n 2 1)s 22 . (n 1 1) (n 2 1) 3. The shape of the sampling distribution is approximately normal if both sample sizes are “sufficiently large” OR if both original populations are normally distributed. Given these characteristics, the test statistic we will use when testing for differences in two population means for INDEPENDENT samples is as follows: Assuming Unequal Variances Assuming Equal (Pooled) Variances t (x 1 x 2 ) (μ 1 μ 2 ) s 12 s 22 n1 n 2 t (x 1 x 2 ) (μ 1 μ 2 ) s 2pooled n1 s 2pooled n2 These test statistics follow a t-distribution, and the degrees of freedom for each case are given in the outline of the formal hypothesis test procedure on the next page. 165 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 The Procedure for Testing for a Difference in Two Population Means (Assuming Independent Samples) Step 0: Check the assumptions behind the test to be sure that the test is valid (and that the right test is used). 1. Are the two groups independent? 2. Are both sample sizes sufficiently large? If not, is it reasonable to assume that both populations are normally distributed? 3. Check whether you can assume the variances are equal. Here is one widely used rule of thumb: If one group’s variance is more than twice as big as the other group’s variance, then assume the variances are unequal. Step 1: Convert the research question into H0 and Ha. 1. Upper-Tailed Test: H0: Ha: 2. Lower-Tailed Test: H0: Ha: 3. Two-Tailed Test: H0: Ha: Step 2: Determine α, the significance level. 166 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Step 3: Calculate a test statistic from your data. If you assume the variances are equal: t (x 1 x 2 ) (μ 1 μ 2 ) s 2pooled n1 s 2pooled n2 Assuming the two variances are equal, this test statistic comes from a tdistribution with df = (n1 – 1) + (n2 – 1). If there is evidence of unequal variances: t (x 1 x 2 ) (μ 1 μ 2 ) s 12 s 22 n1 n 2 If we assume the variances are unequal, we must use Satterthwaite’s approximation to find the degrees of freedom for this test statistic: df s 12 s 22 n1 n 2 2 2 2 2 2 s1 s2 n n 1 2 n1 1 n2 1 167 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Step 4: Determine the p-value and make a decision regarding H0. Lower-Tailed Test (Ha contains <) Step 5: Upper-Tailed Test (Ha contains >) Two-Tailed Test (Ha contains ≠) Write a conclusion in terms of the original research question. Back to Example 7.3: Carry out the hypothesis test associated with the following research question: Is the average birth weight lower when mothers are classified as smokers? Step 0: Check the assumptions behind the test to be sure that the test is valid. 1. Are the two groups independent? Explain. 2. Are both sample sizes sufficiently large? If not, is it reasonable to assume that both populations are normally distributed? 168 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 3. Check whether you can assume the variances are equal. Remember the rule of thumb: If one group’s sample varaince is more than twice as big as the other group’s variance, then assume the variances are unequal. Step 1: Convert the research question into H0 and Ha. H0: Ha: Step 2: Determine α, the error rate. 169 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Step 3: Calculate a test statistic from your data. We can use the formulae to verify the value of the test statistic from JMP: s 2pooled t (n 1 1)s12 (n 2 1)s 22 = (n 1 1) (n 2 1) (x 1 x 2 ) (μ 1 μ 2 ) s 2pooled n1 s 2pooled = n2 Recall that this test statistic comes from a t-distribution with df = (n1 – 1) + (n2 – 1) = 170 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Step 4: Determine the p-value and make a decision regarding H0. p-value: Decision: Step 5: Write a conclusion in terms of the original research question. “We have evidence that the average birth weight is lower when mothers are classified as smokers (p-value < .0001).” Constructing a Confidence Interval for the Difference in Means Lower Endpoint = Upper Endpoint = Interpret the meaning of this 95% confidence interval: 171 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Example 7.4: Consider the WSU Student Survey.JMP data and the issue of the relationship between skipping at least one class per week and cumulative GPA. Your research question is as follows: Is the average cumulative GPA of students who skip at least one class per week lower than the cumulative GPA of students who don’t? The data are summarized by selecting Analyze > Fit Y by X and placing Skip Class in the X, Factor box and GPA in the Y, Response box. Then, use the Display Options menu to add different graphical enhancements. It is clear that the SAMPLE of students who do not regularly skip classes have a higher mean GPA than that for the SAMPLE of students who do. However, to determine whether if the skippers have a smaller POPULATION mean we will carry out a hypothesis test. Step 0: Check the assumptions behind the test to be sure that the test is valid. 1. Are the two groups independent? 2. Are both sample sizes sufficiently large? If not, is it reasonable to assume that both populations are normally distributed? 3. Check whether you can assume the variances are equal. Your text suggests using the following rule of thumb: If one group’s variance is more than twice as big as the other group’s variance, then assume the variances are unequal. 172 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Step 1: Convert the research question into H0 and Ha. H0: Ha: Step 2: Determine α, the level of significance. Step 3: Calculate a test statistic from your data. We could verify the value of the test statistic from JMP. The order of the calculations is shown below. I will make you do this once on your next assignment. (n 1)s12 (n 2 1)s 22 s 2pooled 1 = (n 1 1) (n 2 1) t (x 1 x 2 ) (μ 1 μ 2 ) s 2pooled n1 s 2pooled = n2 Recall that this test statistic comes from a t-distribution with df = (n1 – 1) + (n2 – 1) = 173 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Step 4: Determine the p-value and make a decision regarding H0. p-value: Decision: Step 5: Write a conclusion in terms of the original research question. “We have evidence that the average GPA of students who skip at least one class per week is lower than the average GPA of student who do not skip class (p-value < .0001).” Finally, construct a 95% confidence interval for the difference in means: Lower Endpoint = Upper Endpoint = 174 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Interpret the meaning of this confidence interval: Example 7.5: Now suppose you wish to compare the mean sleep time of female and male WSU students. The research question is: Is there a significant difference in the average amount of sleep per day of female and male WSU students? There does not appear to be a large difference in the SAMPLE average sleep times based on gender. However, to determine whether the POPULATION mean sleep times differ between the genders, we will carry out a hypothesis test. Step 0: Check the assumptions behind the test to be sure that the test is valid. 1. Are the two groups independent? 2. Are both sample sizes sufficiently large? If not, is it reasonable to assume that both populations are normally distributed? 175 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 3. Check for unequal variances. If one group’s variance is more than twice as big as the other group’s standard deviation, then assume the variances are unequal. Step 1: Convert the research question into H0 and Ha. H0: Ha: Step 2: Determine α, the level of significance. 176 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Step 3: Calculate a test statistic from your data. We could verify the value of the test statistic from JMP, but I will skip it this time. Feel free to fill in the calculations on your own. s 2pooled t (n 1 1)s12 (n 2 1)s 22 = (n 1 1) (n 2 1) (x 1 x 2 ) (μ 1 μ 2 ) s 2pooled n1 s 2pooled = n2 Recall that this test statistic comes from a t-distribution with df = (n1 – 1) + (n2 – 1) = Step 4: Determine the p-value and make a decision regarding H0. p-value: 177 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Step 5: Write a conclusion in terms of the original research question. Finally, we can construct a confidence interval for the difference in means: Lower Endpoint = Upper Endpoint = Interpret the meaning of this 95% confidence interval: 178 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Wilcoxon Rank Sum Test This test is an alternative to the two-sample t-test for comparing the “average” value of two populations where the samples from each population are taken independently. This test is appropriate when the assumption of normality is violated (as it may have been in the previous example due to the discrete nature of the response sleep time). To obtain the output for the Wilcoxon Rank Sum test, simply select Nonparametric > Wilcoxon Test from the drop-down menu in the upper left-hand corner of the boxplots. JMP returns the following output: The decision based on Wilcoxon’s test is the same decision that we arrived at using the standard t-test above. Often, these procedures will agree each other because the above ttest is robust to (i.e. not greatly affected by) departures from normality. 179 STAT 110: Section 7.2 – Comparing Two Population Means Using Independent Samples May 2012 Example 7.6: Cell Radii of Malignant vs. Benign Breast Tumors Research Question: Is there evidence of a difference in the mean cell radius of benign and malignant breast tumors? The variance for malignant tumors is over twice that of benign tumors thus we should not assume the variances are equal. All that means is that we conduct a non-pooled t-Test by selecting the t-Test option instead as shown below. The resulting output is the same. We have extremely strong evidence to suggest that malignant breast tumors have a larger mean cell radius than benign tumors (p < .0001). We estimate the mean cell radius for malignant tumors is between 4.84 and 5.79 units larger than that for benign tumors. 180