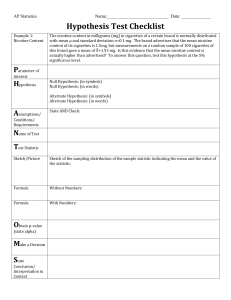
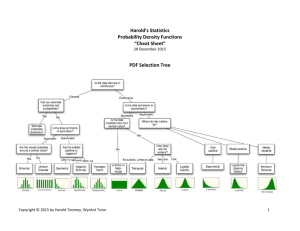
Docx - Toomey.org
advertisement

Harold’s Statistics “Cheat Sheet” 26 December 2015 Descriptive Description Population Sample Used For Parameters 𝑋, 𝑌 Statistics 𝑥, 𝑦 𝑁 𝑛 Describing and predicting. The random value from the evaluated population. Number of observations in the population/sample. Indicates which value is typical for the data set. Measure of center; includes entire population. Average. Used when same probabilities for each X. Answers “Where is the center of the data located?” Data Random Variable Size Measures of Center (Measure of central tendency) 𝒏 𝑁 𝟏 ̅ = ∑ 𝒙𝒊 𝒙 𝒏 1 𝜇 = ∑ 𝑥𝑖 𝑁 Mean 𝒊=𝟏 𝑖=1 Mean with 𝒇 Table Median Mode Mid-Range 1 ∑ 𝑥𝑖 𝑓 𝑁 𝑛+1 𝑀𝑑 = 𝑖𝑓 𝑛 𝑖𝑠 𝑜𝑑𝑑 2 𝑀𝑜 𝑚𝑎𝑥. + 𝑚𝑖𝑛. 𝑀𝑖𝑑𝑅𝑎𝑛𝑔𝑒 = 2 Measures of Variation 1 ∑(𝑥 − 𝜇)2 𝑁 𝑁 1 (∑ 𝑥𝑖2 − 𝑁 𝜇2 ) 𝑁 𝑖=1 1 𝜎(𝑋, 𝑌) = ∑(𝑥 − 𝜇𝑥 )(𝑦 − 𝜇𝑦 ) 𝑁 𝑁 1 𝜎(𝑋, 𝑌) = ∑ 𝑥𝑖 𝑦𝑖 − 𝜇𝑥 𝜇𝑦 𝑁 𝜎2 = Covariance 1 ∑ 𝑥𝑖 𝑓 𝑛 𝑖=1 Copyright © 2015 by Harold Toomey, WyzAnt Tutor Measure of center for a frequency distribution. More useful when data are skewed. The middle element in order of rank. Appropriate for categorical data. The most frequency value in a data set. Not often used, easy to compute. Highly sensitive to unusual values. (Measure of dispersion) 𝜎2 = Variance ̅= 𝒙 𝜇= Reflect the variability of the data (e.g. how different the values are from each other. 1 ∑(𝑥 − 𝑥̅ )2 𝑛−1 𝑛 1 2 𝑠 = (∑ 𝑥𝑖2 − 𝑛 𝑥̅ 2 ) 𝑛−1 Not often used. See standard deviation. Special case of covariance when the two variables are identical. 1 𝑔= ∑(𝑥 − 𝑥̅ )(𝑦 − 𝑦̅) 𝑛−1 𝑛 1 𝜎(𝑋, 𝑌) = (∑ 𝑥𝑖 𝑦𝑖 − 𝑛 𝑥̅ 𝑦̅) 𝑛−1 A measure of how much two random variables change together. Measure of “linear depenedence”. If X and Y are independent, then their covarience is zero (0). 𝑠2 = 𝑖=1 𝑖=1 1 Description Standard Deviation Pooled Standard Deviation Interquartile Range (IQR) Population Sample ∑(𝑥 − 𝜇)2 𝜎 = √𝜎 2 = √ 𝑁 ∑(𝒙 − 𝒙 ̅)𝟐 𝒔𝒙 = √ 𝒏−𝟏 ∑ 𝑥2 𝜎=√ − 𝜇2 𝑁 ∑ 𝑥 2 − 𝑛 𝑥̅ 2 𝑠=√ 𝑛−1 𝑁1 𝜎12 + 𝑁2 𝜎22 √ 𝜎𝑝 = 𝑁1 + 𝑁2 (𝒏𝟏 − 𝟏)𝒔𝟐𝟏 + (𝒏𝟐 − 𝟏)𝒔𝟐𝟐 √ 𝒔𝒑 = (𝒏𝟏 − 𝟏) + (𝒏𝟐 − 𝟏) Measures of Relative Standing Percentile Quartile Not often used, easy to compute. (Measures of relative position) Data divided onto 100 equal parts by rank. Data divided onto 4 equal parts by rank. 𝑥 =𝜇+𝓏𝜎 Z-Score / Standard Score / Normal Score 𝓏= 𝑥−𝜇 𝜎 PDF Copyright © 2015 by Harold Toomey, WyzAnt Tutor Measure of variation; average distance from the mean. Same units as mean. Answers “How spread out is the data?” Inferences for two population means. Less sensitive to extreme values. 𝐼𝑄𝑅 = 𝑄3 − 𝑄1 𝑅𝑎𝑛𝑔𝑒 = 𝑚𝑎𝑥. − 𝑚𝑖𝑛. Range Used For 𝑥 = 𝑥̅ + 𝓏 𝑠 𝓏= 𝑥 − 𝑥̅ 𝑠 Highly sensitive to unusual values. Indicates how a particular value compares to the others in the same data set. Important in normal distributions. Used to compute IQR. The 𝓏 variable measures how many standard deviations the value is away from the mean. TI-84: [2nd][VARS][2] normalcdf(-1E99, z) CDF 2 Regression and Correlation Description Formula Response Variable Covariate / Predictor Variable Least-Squares Regression Line Regression Coefficient (Slope) 𝑌 Output 𝑋 Input 𝑏1 is the slope 𝑏0 is the y-intercept (𝑥̅ , 𝑦̅) is always a point on the line ̂ = 𝒃𝟎 + 𝒃𝟏 𝒙 𝒚 𝒃𝟏 = ∑(𝒙𝒊 − ̅ ̅) 𝒙)(𝒚𝒊 − 𝒚 ∑(𝒙 − 𝒙 ̅)𝟐 𝑏1 is the slope 𝒔𝒚 𝒃𝟏 = 𝒓 𝒔𝒙 ̅ − 𝒃𝟏 𝒙 ̅ 𝒃𝟎 = 𝒚 Regression Slope Intercept 𝒓= Linear Correlation Coefficient (Sample) Used For 𝑏0 is the y-intercept Strength and direction of linear relationship between x and y. ̅ 𝒚−𝒚 ̅ 𝟏 𝒙−𝒙 ∑( )( ) 𝒏−𝟏 𝒔𝒙 𝒔𝒚 𝑟= 𝑔 𝑠𝑥 𝑠𝑦 𝑟 = ±1 𝑟 = +0.9 𝑟 = −0.9 𝑟 = ~0 𝑟 ≥ 0.8 𝑟 ≤ 0.5 Perfect correlation Positive linear relationship Negative linear relationship No relationship Strong correlation Weak correlation Correlation DOES NOT imply causation. Residual 𝑒̂𝑖 = 𝑦𝑖 − 𝑦̂ 𝑒̂𝑖 = 𝑦𝑖 − (𝑏0 + 𝑏1 𝑥) Residual = Observed – Predicted ∑ 𝑒𝑖 = ∑(𝑦𝑖 − 𝑦̂𝑖 ) = 0 2 𝑠𝑏1 √ ∑ 𝑒𝑖 𝑛−2 = √∑(𝑥𝑖 − 𝑥̅ )2 𝒔𝒃𝟏 ̂𝒊 ) √∑(𝒚𝒊 − 𝒚 𝒏−𝟐 = ̅)𝟐 √∑(𝒙𝒊 − 𝒙 Standard Error of Regression Slope 𝟐 How well the line fits the data. Coefficient of Determination 𝑟2 Copyright © 2015 by Harold Toomey, WyzAnt Tutor Represents the percent of the data that is the closest to the line of best fit. Determines how certain we can be in making predictions. 3 Proportions Description Population 𝑃=𝑝= Proportion 𝑥 𝑁 𝑝̂ = 𝑞 =1−𝑝 𝑄 = 1−𝑃 𝜎2 = Variance of Population (Sample Proportion) Sample 𝜎2 = Pooled Proportion Used For 𝑥 𝑛 Probability of success. The proportion of elements that has a particular attribute (x). Probability of failure. The proportion of elements in the population that does not have a specified attribute. 𝑞̂ = 1 − 𝑝̂ 𝑝𝑞 𝑁 𝑠𝑝2 = 𝑝(1 − 𝑝) 𝑁 𝑝̂ 𝑞̂ 𝑛−1 Considered an unbiased estimate of the true population or sample variance. 𝑝̂ (1 − 𝑝̂ ) 𝑛−1 𝑥1 + 𝑥2 𝑝̂𝑝 = 𝑛1 + 𝑛2 𝑠𝑝2 = 𝑥 = 𝑝̂ 𝑛 = frequency, or number of members in the sample that have the specified attribute. NA 𝑝̂1 𝑛1 + 𝑝̂2 𝑛2 𝑛1 + 𝑛2 𝑝̂𝑝 = Discrete Random Variables Description Formula Random Variable Used For Derived from a probability experiment with different probabilities for each X. Used in discrete or finite PDFs. 𝑋 𝐸(𝑋) = 𝑥̅ 𝑵 Expected Value of X 𝑬(𝑿) = 𝝁𝒙 = ∑ 𝒑𝒊 𝒙𝒊 = ∑ 𝑃(𝑋) 𝑋 𝑽𝒂𝒓(𝑿) = 𝒊=𝟏 𝟐 𝝈𝒙 = E(X) is the same as the mean. X takes some countable number of specific values. Discrete. ∑ 𝒑𝒊 (𝒙𝒊 − 𝝁𝒙 )𝟐 2 𝜎𝑥2 = ∑ 𝑃(𝑋) (𝑋 − 𝐸(𝑋)) Variance of X 𝜎𝑥2 2 = ∑ 𝑋 𝑃(𝑋) − 𝐸(𝑋) 2 Calculate variances with proportions or expected values. 𝜎𝑥2 = 𝐸(𝑋 2 ) − 𝐸(𝑋)2 𝑆𝐷(𝑋) = √𝑉𝑎𝑟(𝑋) Standard Deviation of X 𝜎𝑥 = √𝜎𝑥2 Calculate standard deviations with proportions. 𝑁 Sum of Probabilities ∑ 𝑝𝑖 = 1 1 If same probability, then 𝑝𝑖 = 𝑁 . 𝑖=1 Copyright © 2015 by Harold Toomey, WyzAnt Tutor 4 Statistical Inference Description Sampling Distribution Central Limit Theorem (CLT) Sample Mean Sample Mean Rule of Thumb Sample Proportion Sample Proportion Rule of Thumb Difference of Sample Means Mean Is the probability distribution of a statistic; a statistic of a statistic. Lots of 𝑥̅ ’s form a Bell Curve, approximating the normal distribution, √𝑛(𝑥̅ − 𝜇) ≈ 𝒩(0, 𝜎 2 ) regardless of the shape of the distribution of the individual 𝑥𝑖 ’s. 𝝈 𝝈𝒙̅ = 𝝁𝒙̅ = 𝝁 √𝒏 (2x accuracy needs 4x n) Use if 𝑛 ≥ 30 or if the population distribution is normal 𝜇=𝑝 Large Counts Condition: Use if 𝑛𝑝 ≥ 10 𝐚𝐧𝐝 𝑛(1 − 𝑝) ≥ 10 𝐸(𝑥̅1 − 𝑥̅2 ) = 𝜇𝑥̅ 1 − 𝜇𝑥̅ 2 𝑝𝑞 𝑝(1 − 𝑝) =√ 𝑛 𝑛 σ𝑝 = √ 10 Percent Condition: Use if 𝑁 ≥ 10𝑛 𝝈𝒙̅𝟏−𝒙̅𝟐 = √ 𝝈𝟐𝟏 𝝈𝟐𝟐 + 𝒏𝟏 𝒏𝟐 𝟏 𝟏 𝝈𝒙̅𝟏−𝒙̅𝟐 = 𝝈√ + 𝒏𝟏 𝒏𝟐 Special case when 𝜎1 = 𝜎2 Difference of Sample Proportions Standard Deviation 𝛥𝑝̂ = 𝑝̂1 − 𝑝̂2 Special case when 𝑝1 = 𝑝2 𝑝1 𝑞1 𝑝2 𝑞2 𝒑𝟏 (𝟏 − 𝒑𝟏 ) 𝒑𝟐 (𝟏 − 𝒑𝟐 ) 𝝈=√ + =√ + 𝑛1 𝑛2 𝒏𝟏 𝒏𝟐 1 1 𝟏 𝟏 𝝈 = √𝑝𝑞√ + = √𝒑(𝟏 − 𝒑)√ + 𝑛1 𝑛2 𝒏𝟏 𝒏𝟐 Bias Caused by non-random samples. Variability Caused by too small of a sample. 𝑛 < 30 Copyright © 2015 by Harold Toomey, WyzAnt Tutor 5 Confidence Intervals for One Population Mean Description Formula 𝔃= Standardized Test Statistic (of the variable 𝑥̅ ) Confidence Interval (C) for µ / zinterval (σ known, normal population or large sample) Margin of Error/Standard Error (SE) (for the estimate of µ) Sample Size (for estimating µ, rounded up) Critical Value Null Hypothesis: 𝑯𝟎 Alternative Hypotheses: 𝑯𝟏 𝒐𝒓 𝑯𝒂 Hypothesis Testing 𝒔𝒕𝒂𝒕𝒊𝒔𝒕𝒊𝒄 − 𝒑𝒂𝒓𝒂𝒎𝒆𝒕𝒆𝒓 𝒔𝒕𝒂𝒏𝒅𝒂𝒓𝒅 𝒅𝒆𝒗𝒊𝒂𝒕𝒊𝒐𝒏 𝒐𝒇 𝒔𝒕𝒂𝒕𝒊𝒔𝒕𝒊𝒄 𝑥̅ − 𝜇 𝓏=𝜎 ⁄ 𝑛 √ z-interval = 𝒔𝒕𝒂𝒕𝒊𝒔𝒕𝒊𝒄 ± (𝒄𝒓𝒊𝒕𝒊𝒄𝒂𝒍 𝒗𝒂𝒍𝒖𝒆) ∗ (𝒔𝒕𝒂𝒏𝒅𝒂𝒓𝒅 𝒅𝒆𝒗𝒊𝒂𝒕𝒊𝒐𝒏 𝒐𝒇 𝒔𝒕𝒂𝒕𝒊𝒔𝒕𝒊𝒄) 𝓏 - interval = 𝑥̅ ± 𝐸 𝜎 = 𝑥̅ ± 𝓏𝛼⁄2 ∙ √𝑛 𝛼 100 − 𝐶 = 2 2 𝓏𝛼⁄2 = 𝑧 − 𝑠𝑐𝑜𝑟𝑒 𝑓𝑜𝑟 𝑝𝑟𝑜𝑏𝑎𝑏𝑖𝑙𝑖𝑡𝑖𝑒𝑠 𝑜𝑓 𝛼⁄2 𝜎 𝑆𝐸(𝑥) = 𝐸 = 𝓏𝛼⁄ ∙ 2 √𝑛 𝑆𝐸(𝑥̅ ) = 𝑠⁄ √𝑛 𝓏𝛼⁄2 ∙ 𝜎 2 𝑛=( ) 𝐸 𝓏𝛼⁄2 Always set ahead of time. Usually at a threshold value of 0.05 (5%) or 0.01 (1%). Is assumed true for the purpose of carrying out the hypothesis test. Always contains “=“ The null value implies a specific sampling distribution for the test statistic Can be rejected, or not rejected, but NEVER supported Is supported only by carrying out the test, if the null hypothesis can be rejected. Always contains “>“ (right-tailed), “<” (left-tailed), or “≠” (twotailed) [tail selection is Important] Without any specific value for the parameter of interest, the sampling distribution is unknown Can be supported (by rejecting the null), or not supported (by failing or rejecting the null), but NEVER rejected 1. Formulate null and alternative hypothesis 2. If traditional approach, observe sample data 3. Compute a test statistic from sample data 4. If p-value approach, compute the p-value from the test statistic 5. Reject the null hypothesis (supporting the alternative) a. p-value: at a significance level α, if the p-value ≤ α; b. Traditional: If the test statistic falls in the rejection region otherwise, fail to reject the null hypothesis Copyright © 2015 by Harold Toomey, WyzAnt Tutor 6 Test Statistics Description Test Statistic Formula Hypothesis Test Statistic for 𝑯𝟎 Population/Sample Proportion 𝑝̂ − 𝑝0 𝑝̂ − 𝑝0 = 𝑆𝐸(𝑝̂ ) 𝑝𝑞 √ 𝑛 𝑥̅ − 𝜇0 𝑥̅ − 𝜇0 𝑡= = 𝑠 𝑆𝐸(𝑥̅ ) ⁄ 𝑛 √ 𝑍= Population/Sample Mean 𝑥̅ − 𝜇0 𝓏= 𝜎 ⁄ 𝑛 √ Inputs/Conditions Standard Normal 𝑍 under 𝐻0 . Assumes 𝑛𝑝 ≥ 15 𝒂𝒏𝒅 𝑛𝑞 ≥ 15. Variance unknown. 𝑡 Distribution, 𝑑𝑓 = 𝑛 − 1 under 𝐻0 . Variance known. Assumes data is normally distributed or 𝑛 ≥ 30 since 𝑡 approaches standard normal 𝑍 if n is sufficiently large due to the CLT. Goodness-of-Fit Test – Chi-Square Expected Frequencies for a Chi-Square 𝐸 = 𝑛𝑝 𝜒2 = Chi-Square Test Statistic 𝝌𝟐 = ∑ (𝑛 − 1)𝑠 2 𝜎2 (𝒐𝒃𝒔𝒆𝒓𝒗𝒆𝒅 − 𝒆𝒙𝒑𝒆𝒄𝒕𝒆𝒅)𝟐 𝒆𝒙𝒑𝒆𝒄𝒕𝒆𝒅 𝑑𝑓 = 𝑘 − 1 Degrees of Freedom 𝑝 = 𝑝𝑟𝑜𝑝𝑜𝑟𝑡𝑖𝑜𝑛 𝑛 = 𝑠𝑎𝑚𝑝𝑙𝑒 𝑠𝑖𝑧𝑒 Large 𝜒 2 values are evidence against the null hypothesis, which states that the percentages of observed and expected match (as in, any differences are attributed to chance). 𝑘 = 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑝𝑜𝑠𝑠𝑖𝑏𝑙𝑒 𝑣𝑎𝑙𝑢𝑒𝑠 (𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑖𝑒𝑠) 𝑓𝑜𝑟 𝑡ℎ𝑒 𝑣𝑎𝑟𝑖𝑎𝑏𝑙𝑒 𝑢𝑛𝑑𝑒𝑟 𝑐𝑜𝑛𝑠𝑖𝑑𝑒𝑟𝑎𝑡𝑖𝑜𝑛 Independence Test – Chi-Square Expected Frequencies for a Chi-Square Chi-Square Test Statistic Degrees of Freedom 𝑟𝑐 𝑛 (𝑂 − 𝐸)2 𝜒2 = 𝐸 𝐸= 𝑑𝑓 = (𝑟 − 1)(𝑐 − 1) 𝑟 = # 𝑜𝑓 𝑟𝑜𝑤𝑠 𝑐 = # 𝑜𝑓 𝑐𝑜𝑙𝑢𝑚𝑛𝑠 (see above) 𝑟 𝑎𝑛𝑑 𝑐 = 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑝𝑜𝑠𝑠𝑖𝑏𝑙𝑒 𝑣𝑎𝑙𝑢𝑒𝑠 𝑓𝑜𝑟 𝑡ℎ𝑒 𝑡𝑤𝑜 𝑣𝑎𝑟𝑖𝑎𝑏𝑙𝑒𝑠 𝑢𝑛𝑑𝑒𝑟 𝑐𝑜𝑛𝑠𝑖𝑑𝑒𝑟𝑎𝑡𝑖𝑜𝑛 Formulating Hypothesis If claim consists of … “…is not equal to…” “…is less than…” “…is greater than…” “…is equal to…” or “…is exactly…” “…is at least…” “…is at most…” then the hypothesis test is Two-tailed ≠ Left-tailed < Right-tailed > Two-tailed = Left-tailed < Right-tailed > Copyright © 2015 by Harold Toomey, WyzAnt Tutor and is represented by… 𝑯𝟏 𝑯𝟎 7 Copyright © 2015 by Harold Toomey, WyzAnt Tutor 8