HERE
advertisement

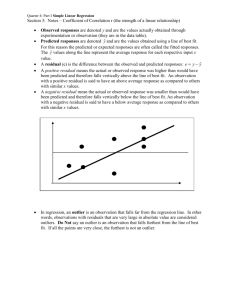
Chapter Study Guide Chapter 6 Correlation and Linear Regression I Variance, Covariance and Correlation Coefficient Sample Variance of One Single Variable (Y): ∑(𝑦−𝑦̅)2 s2 = 𝑛−1 (mean squares = total sum of squares / (n-1)), 𝑦̅ is average, n = number of observations. Standard deviation: s = √ ∑(𝑦−𝑦̅)2 𝑛−1 Covariance of Two Variables (X and Y): ∑(𝑥−𝑥̅ ) (𝑦−𝑦̅) Cov (X, Y) = , where n = number of pairs 𝑛−1 Correlation Coefficient of Two Variables (X and Y): 𝑐𝑜𝑣(𝑥,𝑦) ∑(𝑥−𝑥̅ ) (𝑦−𝑦̅) 𝑠𝑥 𝑠𝑦 (𝑛−1)𝑠𝑥 𝑠𝑦 r= = , where 𝑠𝑥 = standard deviation of X, 𝑠𝑦 = standard deviation of Y. Correlation Coefficient of One Variable with Itself (X and X): 𝑐𝑜𝑣(𝑥,𝑦) 𝑐𝑜𝑣(𝑥,𝑥) r= 𝑠𝑥 𝑠𝑦 = Exercise 6.1 𝑠𝑥 𝑠𝑥 = 𝑣𝑎𝑟(𝑥) 𝑠𝑥 𝑠𝑥 =1 Student study hours and scores in the exam are listed below: Student 1 2 3 4 5 Average 1) Hour 5 6 7 8 4 6 Score 70 80 90 100 80 84 Calculate variances and standard deviations of Hour and Score Variance of Hour: Standard Deviation of Hour: s hour = Variance of Score: Standard Deviation of Score: s score = Chaodong Han OPRE 504 Page 1 of 6 2) Calculate covariance of Hour and Score (paired by Student ID) and interpret results COV(hour, score) 3) Calculate the correlation strength between Hour and Score Properties of Correlations The sign of a correlation coefficient gives the direction of the association Correlation is always between -1 and +1 Correlation treats two variables (x and y) symmetrically; therefore, no causality can be implied Correlation coefficient has no units Correlation measures the strength of the association Correlation does not change with the units of variables Correlation is sensitive to outliers More exercises: Sharpe 2011, pp.136-137, Guided Example – Customer Spending Use DDXL or Excel Data Analysis Toolpak to display correlation using scatter plot and calculate correlation coefficient: Sharpe 2011, pp.167 – 168, Exercises 19, 20, and 21 Chaodong Han OPRE 504 Page 2 of 6 II Simple Linear Regression The Regression (Least Square) Line 𝐲̂ = b0 + b1x b0: Only when 0 is a possible value of x, intercept has a meaning. b1: the slope of the line, called the coefficient of x. Least Square Line (the line of best fit, the regression line): The line for which the sum of the squared residuals (e = y - 𝑦̂) is smallest 𝑠𝑦 b1 = r where r is the correlation coefficient of X and Y, sy is standard deviation of Y and sx 𝑠𝑥 is standard deviation of X. When x is at the average value, 𝑦̅ = 𝑏0 + 𝑏1 𝑥̅ ; b0 = y̅ - b1 x̅ Therefore, we can write a least square line for any simple linear regression as follows: ŷ = (𝑦̅ - 𝑏1 𝑥̅ ) + (r 𝑠𝑦 𝑠𝑥 )x Understand the ANOVA Table of Simple Linear Regression Hypotheses: H0: b1 = 0 (use ŷ y to predict y, there is no linear relationship between x and y) Ha: b1 0 (use yˆ b0 b1 * x to predict y, there is a statistically significant linear relationship between x and y) SST = sum of squared total (dependent variable): ∑(𝑦 − 𝑦̅)2= ∑ 𝑒 2 (df = n-1) SSE = sum of squared of errors (residuals): ∑(𝑦 − 𝑦̂)2 (df= n-1 -1 = n-2 for simple linear reg) SSR = sum of squared regression (predicted value): ∑(𝑦̂ − 𝑦̅̂ )2 (df = 1) Use F (1, n-2) = 𝑺𝑺𝑹/𝟏 𝑺𝑺𝑬/(𝒏−𝟐) to test whether the model is significant R-squared (Coefficient of Determination) 𝑆𝑆𝐸 R2 =1 , measuring the fraction of variance (to be accurately, total sum of squares) 𝑆𝑆𝑇 accounted for by the model. R2 = r2 = square of correlation between the dependent variable and the independent variable. Radj2 =1 - 𝑆𝑆𝐸/(𝑛−𝑝−1) 𝑆𝑆𝑇/(𝑛−1) , where n = number of observations, p= number of independent variables (p=1 in simple linear regressions, so Radj2 =1 - Chaodong Han 𝑆𝑆𝐸/(𝑛−𝑝−1) 𝑆𝑆𝑇/(𝑛−1) OPRE 504 𝑆𝑆𝐸/(𝑛−2) = 1 - 𝑆𝑆𝑇/(𝑛−1) Page 3 of 6 Testing Assumptions for a Linear Model 1. Linearity – close to a straight line Check the scatterplot of original values of x and y, to expect a straight line Independence – residuals are independent of each, in particular no serial correlation in a time series data Check the scatterplot of residual (e) against original value of x, to expect no pattern, no trends, no bends, or no outliers. 2. Homoscedasticity – equal variance of the error term (e = y - 𝑦̂ ) Check scatterplot of residuals against predicted values (𝑦̂) or x, to expect that the spread around the regression line is nearly constant. 3. Normality – error terms are normally distributed Check a normal probability plot using software (e.g., DDXL), to expect a close to straight line (diagonal line) 4. Exercise 6.2 Student study hours and scores in the exam are listed below: Student 1 2 3 4 5 Average Hour 5 6 7 8 4 6 Score 70 80 90 100 80 84 1) Develop a model to predict score using study hour. s score = s hour = COV (hour, score)= r= b1 = The model: Chaodong Han OPRE 504 Page 4 of 6 2) What’s the coefficient of determination of the model? 3) What’s the adjusted R-square of the model? Based on predicted model, we can calculate the predicted “score” (𝑦̂) Hour (x) 5 6 7 8 4 ̅) 6(𝒙 Student 1 (2 3 4 5 Mean Score Predicted Residual e (y-𝑦̂ ) 𝑦̂ Score (y) 70 80 90 100 80 ̅) 84(𝒚 SST = SSR + SSE, R2 = 1 - Radj2 =1 - 4) 𝑆𝑆𝐸/(𝑛−𝑝−1) 𝑆𝑆𝑇/(𝑛−1) 𝑆𝑆𝐸 𝑆𝑆𝑇 SSE e (y-𝑦̂ )2 SST ̅ )2 (y-𝒚 SSR (𝑦̂ − ̅ )2 𝒚 SS of X (Hour) ̅ )2 (x-𝒙 = = Test whether this model is significant at 5% and 10% significance levels 𝑆𝑆𝑅/1 F (1, n-2) = 𝑆𝑆𝐸/(𝑛−2) = F (1,3) = F *(5%, 1, 3) = F *(10%, 1, 3) = Compare F and F*, the model is significant if F > F*; otherwise, not significant. Or using Excel to find out the probability: FDIST(x, 1, 3) = Compare calculated probability with 5% or 10% level. The model is significant if FDIST <5%, or 10%. Otherwise, not significant. Chaodong Han OPRE 504 Page 5 of 6 5) If one student plans to reduce his study time by 1.5 hours, how much score change would you expect to occur? More Exercises: Sharpe 2011, pp.150- 152, Guided Example: Home Size and Price Sharpe 2011, Chapter 6, Exercises 9, 10, 11, 12, 13, 20, 21, 25, 26, 27, 28, 29, 30, 31, 32, 35, 36, 43, 44, 45, 46, and 47. 6) Regression Output Using Statistics Software (Excel Data Analysis Toolpak) Regression Statistics Multiple R (Correlation Coefficient) R Square Adjusted R Square Standard Error Observations 0.832050294 0.692307692 0.58974359 7.302967433 5 ANOVA Regression (1) Residual (n-2) Total (n-1) df 1 3 4 SS 360 160 520 MS 360 53.33 130 F 6.75 Significance F 0.0805 R Square 0.6923 Regression Output Score Intercept Hour Coefficients Standard Error 48 14.2361 6 2.3094 t Stat 3.371709 2.598076 P-value (two-tailed) 0.04336 0.08051 Chaodong Han OPRE 504 Page 6 of 6 Adjusted R Square 0.5897