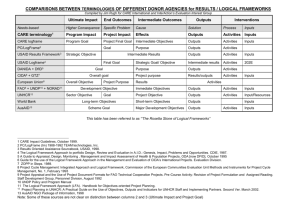
Fundamental Concepts and Issues in Software Requirements and
advertisement

Fundamental Concepts and Issues in Software Requirements and Design M.S.Jaffe Fundamental Concepts and Issues in Software Requirements and Design Contents 1 2 Introduction ........................................................................................................................................... 4 1.1 So what are requirements, really? ................................................................................................. 6 1.2 Design and its requirements related discontents ........................................................................... 8 1.2.1 Requirements are part of a design’s specification................................................................. 8 1.2.2 Algorithmically intensive requirements ................................................................................ 9 1.2.3 Accidental design in a requirements specification .............................................................. 12 The essential information elements of output requirements ............................................................... 14 2.1.1 The essential elements of an output requirement in theory: Value and time ..................... 15 2.1.2 The essential elements of an output requirement in practice .............................................. 16 2.2 Some implication of the focus on observable output behavior ................................................... 23 2.2.1 “Processing” and “computing” are not requirements.......................................................... 24 2.2.2 Are “thou shalt never …” requirements really requirements? ............................................ 25 2.3 3 Constraints and Attributes ........................................................................................................... 25 How do we come up with requirements? ............................................................................................ 28 3.1 Source of requirements ............................................................................................................... 28 3.1.1 Allocation ............................................................................................................................ 28 3.1.2 Elicitation ............................................................................................................................ 29 3.1.3 Interface analysis................................................................................................................. 29 3.1.4 Human-Machine Interface (HMI) design............................................................................ 29 3.1.5 Prototyping (including modeling and simulation) .............................................................. 30 3.1.6 Engineering judgment ......................................................................................................... 31 3.1.7 Engineering analysis, particularly completeness analysis................................................... 31 3.2 Stepwise refinement and functional decomposition ................................................................... 32 p. 2 of 54 Fundamental Concepts and Issues in Software Requirements and Design 4 3.2.1 The stepwise refinement of requirements ........................................................................... 32 3.2.2 Levels of requirements detail and the process versus product distinction .......................... 34 3.2.3 Abstraction, stepwise refinement, and “levels” of software requirements.......................... 36 3.2.4 Stepwise refinement of the Human-Machine Interface....................................................... 42 Are there different types of output requirements? .............................................................................. 42 4.1 4.1.1 The term “functional” is overloaded. .................................................................................. 43 4.1.2 There may be performance requirements that are not timing related. ................................ 43 4.1.3 Theoretic limitations ........................................................................................................... 45 4.2 Other types of output requirements ............................................................................................. 46 4.2.1 Robustness requirements..................................................................................................... 47 4.2.2 Derived requirements .......................................................................................................... 48 4.3 5 Are functional and performance requirements distinct types of requirements? .......................... 43 Types of requirements versus pieces of requirements ................................................................ 49 Issues with requirements documentation ............................................................................................ 50 5.1 Textual requirements standards .................................................................................................. 50 5.2 Model based requirements documentation.................................................................................. 50 5.3 Prototyped requirements ............................................................................................................. 50 6 Explicit versus implicit design methodologies ................................................................................... 50 7 References ........................................................................................................................................... 53 p. 3 of 54 Fundamental Concepts and Issues in Software Requirements and Design 1 Introduction Although the theory of the first two stages of software engineering sounds simple enough, first you figure out and document the requirements for something and then you come up with a design to meet those requirements, in practice there have always been problems telling where the requirements left off and the design began. It’s not that no one knows the difference; it’s that everyone seems to know (or, more accurately, believe) something different. The parable of the blind men and the elephant seems quite apt here.1 The problem is not new. As early as 1982, Swartout and Balzer wrote an influential paper titled, On the inevitable intertwining of specification and implementation [1], where “specification” and “implementation” were what we would now call requirements engineering and design. Despite the confusion, systems occasionally get built successfully anyway; but our field’s success rate was and remains appallingly low2 and part of the reason for our poor performance is the lack of conceptual clarity about what we are really trying to achieve during the beginning stages of a software engineering project. As a wise old baseball manager once said, if you don't know where you're going, you might not get there.3 For software engineering that translates to, if we don’t know what we are trying to achieve with our requirements and design efforts, we are unlikely to wind up pleased with our results, which is the state of many (possibly most) software development projects to this day. This confusion is by no means an academic issue, developed by cloistered software engineering dons to give us something to write erudite but useless papers about. As a consultant, I’ve worked with a lot of aerospace companies and government agencies and I am often called to teach a mini-course along the lines of Things your college professors didn’t teach you about software engineering [2]. I almost always get started by reminding my audience, all of whom are industrially experienced engineers, of one of the humorous but also serious ramifications of the 1 http://en.wikipedia.org/wiki/Blind_men_and_an_elephant 2 http://www.ibm.com/developerworks/rational/library/feb06/marasco/ 3 http://en.wikiquote.org/wiki/Yogi_Berra p. 4 of 54 Fundamental Concepts and Issues in Software Requirements and Design confusion about the front end of the software engineering process. I start by asking them how their company determines that the software requirements are really done and it’s time to move on and get serious about design. Nobody ever wants to answer that question, of course, since they don’t really know, so there’s always an awkward silence, which I let drag on for a few seconds. Then I tell them that they should forget their old textbooks from their old college classes and admit, without embarrassment, what I know that they and all other real world engineers know to be the only real answer: The requirements are done when the time and money budgeted for coming up with the requirements have run out. I always get embarrassed laughs at that point, but nobody has ever disagreed ever. So what’s my point here, in a first introduction to software requirements and design for undergraduates? The point is that despite decades’ worth of industrial experience and dozens, if not hundreds, of textbooks, there continues to be a fair bit of confusion between what, on the surface, would seem to be two rather easily distinguishable concepts: requirements and design. You may not believe that that could really be a real world problem, but it really is (remember our abysmally low success rate). The purpose of these lecture notes then is to boldly go where no textbook ever seems to actually go and take a good hard look into the conceptual murkiness and try to shed a little light on the causes of the confusion. We’ll start by taking a look at the conceptual basis for the word “requirement” when used in the context of software engineering what does it really entail? Which aspects of requirements pertain to all software projects (and why) and which are “optional”. (Optional requirements? And therefore the others are required requirements? Perhaps you’re starting to glimpse why coming up with usable jargon may be part of the problem here?) Then we’ll do the same for “design” what is it really? Answering that will actually turn out to be quite a bit simpler than understanding requirements. Then, having, with luck, established at least a partially rigorous foundation for some key concepts, we will then examine some of the reasons that it’s so hard to separate the concepts and vocabulary of requirements from those for design and our investigations will lead us to the exploration of a concept crucial to both the theory and the practice of software engineering the concept of stepwise re- p. 5 of 54 Fundamental Concepts and Issues in Software Requirements and Design finement, which we will then use as a lever to move aside many (not all) of the misconceptions have hindered our ability to understand the start of the software engineering process. Finally, having eliminated a bunch of conceptual irrelevancies, we’ll focus on the relevant: the essential elements of the information that constitute the software requirements and the process by which engineers develop such information. 1.1 So what are requirements, really? And why are they so confusing? On my first professional job as a systems engineer back in 1974, my first assignment was writing software requirements for the Command and Decision segment of the U.S. Navy’s Aegis system. When I asked what that meant, I was told, “just write down what the software is supposed to do without telling the programmer how to do it.” Today, over thirty-five years later, you’ll still often hear software requirements described as the “what” but not the “how” for software4 and that isn’t, in fact, a bad introduction to the philosophy of software requirements engineering. We’ll need to do better here eventually, but the “what, not the how” is a good starting point. So what is the essence of what software is supposed to do what is the “what”, in other words? Answer: The purpose of software is to produce outputs. Software has no other reason to exist other than to produce its outputs. We don’t need it to hold a week’s worth of food supplies, or generate lift for our airplane. We need it to produce its outputs; that’s it. Its outputs may control the physical things that hold our food or generate lift; but the software itself does not do these things. So outputs will be our starting point: Software requirements start from descriptions of the outputs we want. As David Parnas5, one of the founders of modern software engineering put it: 4 See, for quick example, slide #4 of http://incose.org/Chicagoland/docs/Writing%20Effective%20Requirements.pdf 5 http://en.wikipedia.org/wiki/David_Parnas p. 6 of 54 Fundamental Concepts and Issues in Software Requirements and Design “The requirements document treats outputs as more important than inputs. If the value of the outputs is correct, nobody will mind if the inputs are not even read. Thus, the key step is identifying all of the outputs.” [3] More precisely, the essential core of software requirements documentation should be to lay out the acceptable characteristics of our software’s outputs as observable at the software’s blackbox boundary. There are three key concepts here: (1) Acceptable – the whole point of the software requirements is to specify what is (and therefore, by implication, what is not) acceptable behavior for our software. Failing to produce a required output at all or producing it under the wrong circumstances or too late or with the wrong value are all clearly unacceptable and it is to is the requirements document that we must look to see what the acceptable circumstances, timing, and values are supposed to be. (2) Observable – what good are output characteristics that are not observable? If we can’t observe them, how can we ever know whether or not they are acceptable? (How could we test an unobservable requirement, in other words?) (3) Blackbox – from the requirements standpoint, the software is in theory an impenetrable blackbox. It’s called a blackbox because we can’t see any of its internal structure − that’s the result of design, which we can’t have done yet, since we don’t know the requirements. For our requirements, all we can describe are the characteristics of the outputs as they appear at the blackbox boundary. And particularly when specifying timing requirements, it is important to have clearly specified the blackbox boundary, i.e., the place where the observation will take place. For example, does a response time limit of ¼ second apply just to our application software or does it have to include the operating system processing as well? Where we decide to establish our blackbox boundary will make a difference to the details we specify in our requirements as well as how we test them. p. 7 of 54 Fundamental Concepts and Issues in Software Requirements and Design 1.2 Design and its requirements related discontents The theory of design at its most fundamental is actually quite simple. Doing a good job at it may not be trivial, but the conceptual essence is. To design a thing is to: 1. Decompose it into a set of smaller, simpler things 2. Show how those smaller things fit together 3. Describe what each thing does The process is recursive in that we then have to break each of our smaller things down into a set of even smaller things, which in turn get broken down into smaller things, and so on, stopping only when we reach the point that our little things (like source language statements in C) can be handled by a computer program like a compiler.6 That’s the theory; in practice, there are complications. We’ll obviously spend a fair bit of time on the subject of design itself later; all I want to introduce here are some of the most significant complications in the relationship between design and requirements. 1.2.1 Requirements are part of a design’s specification The first reason that there’s usually some degree of confusion between requirements and design is that it is completely impossible to meaningfully describe a design without specifying requirements for its parts (components, modules). Consider the following diagram: C2 C4 C1 C3 6 The same generic model of design applies to hardware, of course, but the stopping criteria changes. I suppose for hardware, we stop when our little things can either be purchased off the shelf or manufactured without further documentation. p. 8 of 54 Fundamental Concepts and Issues in Software Requirements and Design Is that diagram a design? Well, it’s intended to show the interconnections among some components (the Ci), which is certainly part of what a design must describe. But by itself, that picture really doesn’t tell us much not nothing, just not much. In order to fully understand and specify how this design actually works, we need to specify what each component is supposed to do. And what do we call a specification of what something is supposed to do? Why, its requirements of course. So a useful specification of a design for something must include the requirements for its parts. How we avoid tremendous redundancy (and possible inconsistency) in describing our progressively more detailed designs (systems decomposed into subsystems decomposed into tasks or processes decomposed into C functions, for example) is well beyond our scope here and in my opinion there’s still no completely satisfactory answer in general anyway. 1.2.2 Algorithmically intensive requirements Some requirements can be worded very simply and all necessary information can be in one sentence: When the operator pushes the lever down, the software shall output the left-turn signal within 100ms But for some requirements, the value characteristics are complex mathematical functions of many different prior inputs. Consider a radar tracking system which will display aircraft symbols on an operator’s display. The composition of the ultimate output will be fairly simple, let’s say just a symbol and an (x, y) coordinate pair where the symbol is to be displayed, where the x and the y are in units of pixels from the upper left corner of the display. Let’s look at how the software will ultimately have to calculate that display-based x and y coordinates in pixels: Radar reports received in range and bearing [ coordinates from the radar have to be converted into Cartesian coordinates [x, y] relative to the radar If the radar is on a moving platform (a ship or airplane) the position of that platform must be obtained or estimated and converted to a geographically fixed Cartesian position p. 9 of 54 Fundamental Concepts and Issues in Software Requirements and Design Then the plot report’s local [x, y] must be added to the platform’s geographic [x, y] to obtain plot coordinates in geographic [x, y] Then the set of existing tracks (previously known aircraft) must be searched to determine which ones are in the vicinity of the new radar plot. Then the old position of each the aircraft must be extrapolated (based on last known state vector [𝑥, 𝑦, 𝑥̇ , 𝑦̇ , 𝑥̈ , 𝑦̈ ]) to the time of the radar plot Then the best matching track for the plot must be selected based on, let’s say for example, a least squares fit. Then the track’s state vector must be updated using some sort of filter (- or Kalman) Then the track’s geographic coordinates must be converted to display coordinates (pixels) based on the operator’s current window settings Then the updated display coordinates must be output to the display controller You really want to try to write a single equation for all that, directly tying the value of the new display [x, y] coordinates in pixels to the original [ coordinate inputs and the history of display positions for all the tracks recently output? Is it possible to do so? Certainly, in theory. In practice? Not a chance. So in practice, we have little alternative but to describe the reference value7 by describing a series of steps in a possible computation. If we’re well educated in the theory of requirements engineering, we know that we don’t really mean to be dictating the design, we really mean just to be defining a reference value (i.e., the output should look like this: …), but when the description stretches over 40 or 50 pages we sometimes will need to refer forward or backward. We could (and really should, in my opinion), of course, merely say something like, this state vector defini- 7 Remember, the algorithm is not the requirement. The requirement is that our software make an output that is within some specified accuracy of an algorithmically specified reference value. p. 10 of 54 Fundamental Concepts and Issues in Software Requirements and Design tion is used in defining the correlation likelihood as described on page 78, but in too many specifications, it seems to have wound up an almost universal practice to just say, the update function shall pass the state vector to the correlation function. A good software requirements specification, making such an adjustment to the pure, “black box behavior only” theory of requirements, should somewhere at least include a disclaimer reminding the reader that such functions (e.g., correlation function) are to be thought of as descriptive conveniences only and are not intended to dictate design. IEEE Std 830-1998 [6] actually includes a pretty good example in its section 5.2.2b, Product functions: Textual or graphical methods can be used to show the different functions and their relationships. Such a diagram is not intended to show a design of a product, but simply shows the logical relationships among variables. But even there I think there’s some conceptual fuzziness that should be clarified (I’m being polite here). First of all, I don’t like the use of the word “variables” there: Variables are design entities, not output characteristics.8 More importantly, I think the IEEE Std 830-1998 statement is missing an important point: Since form follows function, if we need to modularize our descriptions of some very complex requirements, our choice of textual modularizations may not be intended to dictate a design but it is surely suggestive of some aspects of one. This early, perhaps even somewhat unintentional, modularization may change later in the design process for any one of several reasons, but it is still, in fact, an early, somewhat abstract, design description it’s abstract since we don’t know the nature of the entities involved; i.e., the “functions” in a requirements document are generic (abstract) design entities (something like “subsystems”). These “functions” are certainly not intended to be considered functions in the C language sense of the term. They’re generic, meaning something like, “there may eventually be some sort of actual 8 Unless the authors meant to restrict variables to mean variables visible in the blackbox inputs or outputs; in which, frankly, I think the word “data” or “field” would have avoided any ambiguity, as in, “simply shows the logical relationships among blackbox input and output data.” At this point, I don’t know what the authors actually intended; and that’s unfortunate for a standards document. p. 11 of 54 Fundamental Concepts and Issues in Software Requirements and Design architectural entity here (e.g., a process, a class, a procedure, a subprogram, or even a real function), but we don’t know what it will actually be yet and we reserve the right to change our mind anyway.” But by using such concepts and language, we have nonetheless intertwined real design information, preliminary and abstract as it may be, in with our specification of our requirements. I.e., the stepwise refinement of our design often starts with our choice of organization for our requirements document. That “intertwining” is not necessarily bad per se, but it usually is somewhat accidental: We weren’t really thinking about design at all, just how the hell to organize the requirements document. And an accidental design is not likely to be a terribly good one. 1.2.3 Accidental design in a requirements specification Many requirements specification written according to IEEE Std 830-1998 or its predecessors (both civilian and military) wind up having requirements worded like, “the tracking function shall then pass the computed target position to the display function”. From a purist’s theoretical point of view which is where we’re starting, we shouldn’t make practical compromises without first knowing the underlying theory there are at least two problems with that wording: 1. As we discussed earlier, the word “function” is ambiguous. In many programming languages, a function is a design entity. But in a requirements document to be written long before design takes place, “function” is (or should be) intended to be synonymous with “purpose”, as in, “the function of the software is to control the reactor”. All major requirements specification standards over the last forty years or so have allowed the use of “functions” (meaning purposes) as the main way to organize the requirements document; most of the older standards flat out required it. But as our example requirement, above, was worded, “the tracking function shall then pass the computed position to the display function”, the word “function” sounds like it is being used architecturally: Active design entities can pass things to one another, purposes can’t. The language is thus confusing, p. 12 of 54 Fundamental Concepts and Issues in Software Requirements and Design making the tracking function sound like an architectural entity when it’s not at all clear that it is really intended to be one. 2. That passing of data from one internal entity to another is, by definition, not externally observable and hence not directly testable without extra, often considerably extra, work. When we test your first C program and see “Hello world” show up on the screen, how do we know your main function passed data to the printf function? Couldn’t your code be doing something completely different (like using putc to output one character at a time)? Simply looking at the output (which is the only testing we want to discuss here, since the output is our only “real” requirement), won’t tell us if we’ve satisfied a requirement to pass data to a printf function. Similarly, no simple/direct test will show us that a requirement like “the tracking function shall then pass the computed position to the display function” is being met. I’ve seen test organizations reviewing requirements specifications classify such alleged requirements as “implicit”, meaning “not directly testable by themselves”, meaning that eventually there’d better be some sort of output specified somewhere else that allowing us to observe if the intended data manipulation actually occurred properly; which is really just a polite way of saying that the requirements document was poorly written, without a true understanding of the desired nature of requirements. Later standards, e.g., MIL-STD 498 [10] partly, or probably even largely, in response to the problem with the ambiguous use of the word “function”, replaced it with “capability” 9 as the organizational basis to be used in a software requirements specification. But the problem is in fact much deeper than a simple wording problem and has been recognized, although not really resolved, for quite some time. I think that over the intervening decades we have learned a bit more about the causes of the problem and since it has large consequences for the way we think about 9 See, for example, http://www.letu.edu/people/jaytevis/Software-Engineering/MIL-STD-498/SRS-DID.pdf, paragraph 3.2 p. 13 of 54 Fundamental Concepts and Issues in Software Requirements and Design and then actually do software engineering, I want to explore both the causes and the solutions here. I think there are two root causes to the apparently inevitable intertwining of design information in with the requirements: 1. Algorithmically intensive requirements 2. The absolute necessity of requirements to the description of design (but not vice versa) 2 The essential information elements of output requirements The “what” versus “how” distinction that we mentioned earlier is a good philosophical starting point; but it still isn’t all that helpful to a young engineer trying to figure out what information actually needs to be documented and how to come up with that information. To do better, we need good answers to some fundamental questions, including: (a) What is a requirement? (I.e., can we do better than simply “what, not how”?) (b) Are there different kinds of requirements? (c) What is the overall set of information that must be documented? Once we have a better feel for the techno-philosophy and have developed a well-founded set of concepts and vocabulary, we can look at some of the pragmatics for actually coming up with and documenting requirements. But without first establishing a good foundation, all we’d get is another Tower of Babel, which is what we mostly find in textbooks and on the web today. Before going any further, it would be prudent to start by rigorously defining just the notion of an output itself. To me, it’s one of those “everybody knows that, so why bother” concepts whose unexamined nature can lead to confusion downstream. Better to pin it down precisely here, even at the risk of being a bit pedantic, a common failing of us academics. For this discussion here, then, an output for a given a piece of software will be defined as a collection of bits whose values are controlled by the software and whose time of appearance at the software’s black-box bounda- p. 14 of 54 Fundamental Concepts and Issues in Software Requirements and Design ry can only be controlled by the software collectively – i.e., the software makes the collected set of bit values available to some receiving entity (hardware circuitry, or perhaps another piece of software), but the timing of the appearance of any proper subset is not under control of the software, only the timing of the initial availability of the entire set is. For example, if the software prepares an output message of 256 bits in length and provides it to a hardware serial port, the software has no further control over when the individual bits or any subsets thereof come out in relationship to one another; that timing will be the province of the hardware. The software output is complete when all 256 bits have been calculated and assembled into some required sequence but the further transfer of those bits outside of the software’s blackbox boundary is not under the control of the software making the required output. 2.1.1 The essential elements of an output requirement in theory: Value and time So what is observable in a software output? Only bit patterns (values) and the time they become available for observation at the blackbox boundary. Time is as important as value. Parnas again: “All systems can be described as real-time systems – even if the real time requirements are weak.” [3] Having the value that provides the result of some calculation show up 8 million years after the program first starts running simply won’t do; no one would set out to spend his or her time writing software that might take that long to produce its outputs. So what is an acceptable time limit, even if it’s best measured in months, not milliseconds? See the software requirements. The theory really is this simple; software requirements are statements about the acceptable values for the outputs and the acceptable times for them to appear. That’s it. There’s an important, all too often hidden, assumption about software and time here that really shouldn’t be hidden: What everyone calls software timing requirements (and all practicing engineers and software requirements standards consider timing part of the software requirements) actually specify the desired behavior of a special purpose machine constructed by the execution p. 15 of 54 Fundamental Concepts and Issues in Software Requirements and Design of the software by some actual, more general purpose, hardware.10 In the most formal sense, the software itself only specifies a mathematical function11 for which time is not an observable characteristic. Time only becomes an observable when the software is actually executed on some physical device. So in reality, software requirements specifications that include timing are not actually specifying merely the software’s requirements but the requirements for a computational system consisting of some general purpose, programmable device and the software that controls its behavior; which is probably one reason the boundary between system engineering and software engineering is not as clear as some documentation standards and textbooks seem to imply. There are other reasons for the fuzzy boundary as well; we’ll look at some of them later. 2.1.2 The essential elements of an output requirement in practice Although the theory of observability of software behavior is as simple as timing and value, in practice there are several key concepts that will shed further light on the nature of software requirements and the process(es) by which they are developed and documented. 2.1.2.1 Values and fields As a matter of practicality, we usually divide the bits of a complete output up into separate fields to make it convenient to specify their acceptable values more or less independently of one another. The entire output, for example, may be a display of aircraft data for air traffic control but since the displayed value for the aircraft’s position will be a function of radar inputs, for example, whereas its call sign (e.g., American Airlines 91) is probably a manual input of ASCII codes, we want to specify the acceptable values for those two items separately. Another reason for breaking up value requirements by fields is that some requirements for fields will require exact values, while others fields will only need to be approximate. Output bits that will display an aircraft call sign, for example, must be exact, while the display of the aircraft’s 10 See Leveson, Safeware [9] Figure 2.1 for a good illustration of this point; although the observation is not original with her. 11 Technically, what is known as a recursively enumerable function. p. 16 of 54 Fundamental Concepts and Issues in Software Requirements and Design position may have some tolerance (accuracy) associated with it. E.g., an output field representing some analogue physical quantity such as position, can never be observed exactly and so the software requirement must include a tolerance e.g., ± ¼ mile. As we will discuss later, software requirements are almost always developed via a process of stepwise refinement, and much of the identification of fields usually has to be done earlier in the requirements development process rather than later; while leaving many of the details (such as classification as exact or approximate) to be deferred to later stages but they’re still requirements, since they tell us which output values will be acceptable and which would not be. 2.1.2.2 Timing requirements specify intervals Unlike values, which can sometimes be required to be exact, the time of an output must always be specified approximately – i.e., somewhere within a (specified) interval of time. So, for example, a requirement to make some output at noon is incomplete; it needs a statement of timing accuracy noon ± a picosecond is a harder requirement to meet than noon ± a minute. Often, we don’t think of ourselves as specifying two separate points in time, merely a single number like a limit on a response time. But the response time limit marks the endpoint of an interval whose start is some externally observable event like the arrival of some input e.g., an operator pushed some button and our software must respond within ¼ second; and that starting point must be specified as part of the software requirements; we don’t want an output showing up before the operator pushed the button that asked for it, that would be unacceptable and the software requirements must make that clear. Although a great many outputs may be simple stimulus- response requirements having an obvious earliest acceptable time, there are other real world timing requirements, like periodics, that will require some thinking about. One way or another, the end result is that a timing requirement must eventually specify two times for each output: The earliest time it’s acceptable and the latest. p. 17 of 54 Fundamental Concepts and Issues in Software Requirements and Design 2.1.2.3 Events, triggers, states, modes, and preconditions The practical specification of timing requirements is based on the concept of an observable event; e.g., an input such as an operator’s pressing of some button. Triggers, states, modes, and preconditions are all sets of one or more such events. 2.1.2.3.1 Events From the requirements engineering standpoint, an event is an instant in time when something happens that is visible from outside the software’s blackbox boundary. An event can be quite simple (an operator pushes some key or button) or arbitrarily complex, e.g., a radar input arrives within 10 seconds after some other event and the distance of the radar report from the closest aircraft is less than the average of … et cetera. During the requirements engineering process, events can (and therefore usually should) be defined via stepwise refinement. Eventually, however, it must be possible to express the characteristics of the event as mathematical functions of only the time and value in the event, possibly (often) in relationship to the times and values of prior inputs and outputs, since those times and values are all that is observable at the software’s blackbox boundary.12 Whether or not a given project needs to ultimately document an event to that level of detail (which specific characteristics of which specific inputs) is a “stopping point of stepwise refinement” question, which, as will be discussed later, can vary from project to project. Safety critical software, for example, presumably needs its written requirements specified in greater detail than do most video games. 2.1.2.3.2 States, modes, and preconditions States, modes, and preconditions are combinations of events that collectively enable later outputs but may or may not by themselves require an immediate output response. For example: Program startup is actually also a blackbox event that’s observable by our software; but although in safety-critical systems that can be important, it’s beyond our scope here for at least the time being.. 12 p. 18 of 54 Fundamental Concepts and Issues in Software Requirements and Design Once three inputs of type A have been received, output their average value within 2 seconds after receiving the last input (and do not output another value until three new inputs are received) The precondition for that output is that there were three prior inputs (of type A). All three terms (state, mode, and precondition) are equivalent; precondition is probably the most technically accurate, but the least often explicitly used in requirements standards. In practice, when the same set of preconditions shows up repeatedly in the requirements for multiple, distinct outputs, most requirements development methodologies and standards tend to call it a mode or a state. For example, there may be a lot of very different outputs that we want our weapon control software to be able to generate only if the captain of the ship has previously authorized weapons release, so all those outputs would depend on the prior receipt of the captain’s authorization. The Captain’s turning a key to arm the weapon systems, for example, might be a precondition for later outputs. Colloquially, the system is then said to have a state or mode13 called, let us say, weaponsFree, and the fireTheMissile or the fireTheCannon outputs would only be required in response to an event signaled later by some other operator’s subsequent input e.g., the Weapons Officer pushing a shootNow button. The Captain’s arming the weapon systems doesn’t cause guns or missiles to be fired; but it’s a precondition for later outputs required by later input events. The Weapons Officer push of the button would then not require the system to fire missiles if the system were not in the weaponsFree mode. It might be required to produce some other output, though, like perhaps a message to the Weapons Officer saying something like, “You dumb shit! Why are you pushing the firing button when weapons release has not been authorized?” Note that there would therefore be two different outputs required under different circumstances (preconditions) by the same input event. So a given output may have both unique preconditions (can’t fire the guns if they’re out of ammunition) and some that are in common 13 Weinberg has a nice, if much too long winded (boy, is this the pot calling the kettle black ;-) discussion of states in An Introduction to General Systems Thinking [11]. p. 19 of 54 Fundamental Concepts and Issues in Software Requirements and Design with other outputs (weaponsFree). Many software requirements standards allow/encourage treating them (unique and shared preconditions) somewhat differently; but there is in fact no theoretical or practical difference between states, modes, and preconditions. All three terms are used in the literature and they are all the same thing, a set of one or more externally visible events whose times and values meet some specified conditions. 2.1.2.3.3 Triggers A trigger (the vocabulary is not standard) is an event that actually requires a response from our software. The trigger is the last or most recent event after all the other preconditions have been met after which the software must produce some specified output within some specified time interval or it (the software) will have failed to meet its specification. In our earlier, average value output, example, above, the trigger was the arrival of the last (third) input of type A. In theory, the trigger can be regarded as just another precondition for the output, but it probably deserves its own name (i.e., trigger) since it is the last necessary precondition and therefore serves as a lower bound on the timing of the required output e.g., continuing the average value example, above, the earliest time we want the average value output is the time of the last of the three inputs event plus 2 seconds, the 2 seconds obviously being what is commonly called the response time. Note that although the time of the trigger must be a lower bound for the time of the required output, it need not be the greatest lower bound. For example, we might wish to specify that the earliest time that is acceptable for some output might be the time of the trigger event plus a 1 second delay. 2.1.2.3.4 Positive and negative events Events (including triggers) may be either positive or negative (again, this vocabulary is not standard). A positive event is the occurrence of a change in something externally observable e.g., for interrupt-driven systems, the presence of a new input is a positive event. A negative event is the passage of some specified amount of time without the occurrence of some positive event or set of events. For example, p. 20 of 54 Fundamental Concepts and Issues in Software Requirements and Design If a period of 2 seconds elapses without either the receipt of a message from the radar or an input from the radar operator, output a radarOffline message . Describing a negative condition that way is a quite common, but it is actually a bit abstract and hence ambiguous. Stepwise refinement is crucial to understanding modern software engineering and we’ll examine its role in more detail later; but this radar offline example provides us an opportunity for a good introduction. If our radar goes silent for anything longer than exactly 2 seconds, there will be an infinite number of 2 second intervals of silence, the first one starting 2 seconds after the last message, another starting, for example, 2001 milliseconds after the last message, then another starting 2002 ms, another at 2003, and so on, ad infinitum. And there’s nothing magic about milliseconds there, either; I could have said 20000001 microseconds, or 2000000001 nanoseconds, and so on. There is nothing inconsistent with our requirement as originally worded if our software generates a new radarOffline message for each of such an infinite number of intervals of 2 seconds of radar silence; but that’s probably not what we want (a limitless number of outputs, each signifying that the radar is offline). So the original requirement is ambiguous; it’s fine as a slightly (not terribly) abstract requirement, but eventually the actual start and end points of the silence interval may need to be specified more precisely, as in If there has not been another radar input within the 2 seconds immediately following the receipt of a radar input, output a [single] radar offline message …. Ultimately it is the starting point and the endpoint of an interval that may need to be precisely specified, not just the duration. Why only “may need to be”? That’s a stepwise refinement issue again. For many systems, this last level of detail may not be necessary; but some safety critical systems require proof-of-correctness which could dictate that the more precise level of detail be documented. The more common concern is simply effective communications: Will the designer/programmer reading the requirements know what behavior the requirements specification is really calling for? That’s a simple and casual statement of a really important point. It may seem obvious, but it’s worth emphasizing: The purpose of documenting the software requirements is p. 21 of 54 Fundamental Concepts and Issues in Software Requirements and Design to communicate them to someone. Many practical decisions about levels of detail and documentation style depend on who the intended recipients are as well as the nature of the product being specified. 2.1.2.3.5 Required preconditions: Input capacity or load Most preconditions are obviously very much dependent on the specifics of the application environment the preconditions for a weapon release output are not going to have much in common with the preconditions for dispensing cash from an ATM, for example. But there is a standard type of precondition that should almost always be included in the requirements specification for outputs from many real-time systems and that is a capacity precondition. A hardware platform that provides interrupt-driven I/O, which is more efficient than polling for many real-time applications, can only handle a finite number of interrupts over any finite time interval before the processor will no longer have capacity left to do anything else, including process another interrupt. (I’m oversimplifying here, but only very slightly.) Even very trivial interrupt handling con- sumes both CPU time and memory. The amounts can be very small, so the system’s capacity for that interrupt might be quite large; but there’s always some finite limit on how many interrupts the hardware can process in a given period of time. That limit then needs to be a precondition for “normal” or “not overloaded” mode outputs e.g., If the count of such inputs arriving within the last second is ≤ specifiedCapacity when trigger event whatever occurs, the software shall output the normalMode output as follows But if the count of prior inputs in the last second is > specifiedCapacity when the trigger event occurs, the software shall instead output someOther message with the following characteristics . We may believe that the environment for our computational system is not likely to generate an excessive rate of interrupts (e.g., how fast can a single human operator push the buttons, after all), but that’s exactly the sort of assumption that leads to accidents. In her classic book Safeware, Leveson [9] described a UAV accident where a mechanical failure, survivable in and of itself, led to an excessive number of interrupts being generated to the flight control computer. Not having had a requirement to detect and respond somehow (disable the interrupt, perhaps) to p. 22 of 54 Fundamental Concepts and Issues in Software Requirements and Design this overload, the flight control software crashed in the software sense of the word which was not survivable, and the entire vehicle then crashed shortly thereafter in the physical sense of the word (i.e., a big boom followed by a fire). Note that this concept of capacity need not be as simple as a straight count of input interrupts; it could include categorization of the input. E.g., “Normal mode” is defined as fewer than 50 inputs in the last second of which no more than 10 have an x or y coordinate greater than 5 and no more than 5 of which have an x coordinate greater than 20 … . There is a related concept, often called “load”, which can be defined as the sum of the counts of multiple inputs over some specified time interval. E.g., As a precondition, the definition of normal load is when the sum of the number of air traffic controller inputs plus the number of radar inputs plus the number of flight plan messages input in the last 5 seconds is ≤ 1000. If some inputs are more “important” to the load definition than others (e.g., we think they will take more computational resources to handle), the load, L, can be a weighted total, i.e., L = ∑wi·C(Ii), where C(Ii) is the count of inputs of type Ii over some time interval and wi is the weight for that type of input. The count of interrupts, the weights (if any), the time frame, and the system’s required response to “overload” will all obviously be application dependent; but “capacity” or “load” preconditions of some sort should be specified for all normal outputs for robust systems running on an interrupt-driven platform.14 2.2 Some implication of the focus on observable output behavior Our focus on output behavior has some interesting implications and in fact helps resolve some real world disputations that blur the distinction between requirements and design. And for robustness, of course, such systems should have requirements for dealing with overload, but that’s beyond our scope here. 14 p. 23 of 54 Fundamental Concepts and Issues in Software Requirements and Design 2.2.1 “Processing” and “computing” are not requirements As Parnas noted, “if the value of the outputs is correct, nobody will mind if the inputs are not even read.” A requirement written as, the software shall have the capacity to process up to 45 radar reports per second is sloppy it’s common, but it’s sloppy and unnecessary. It’s sloppy because one can’t actually observe software processing inputs; one can only observe whether or not proper outputs are being produced. It’s unnecessary since the description of the acceptable behavior of required outputs eventually has to include a description of when they are required which, as was discussed earlier, includes the concept of enabling preconditions, so that the “capacity” requirement, above, should be considered as a precondition, as discussed above, rather than a separate requirement in and of itself. In the real world, particularly when considering stepwise-refinement, which we’ll discuss shortly, talking about “input capacity” requirements may not be the worst of sins. But for the moment, as we’re just starting to develop a good conceptual foundation, let’s be purists: Parnas is correct; the processing of inputs is not in and of itself a requirement. Similarly, a poorly written attempt at a requirement such as, the software shall compute the cosine function using the following Taylor series approximation algorithm does not actually describe observable behavior from outside the blackbox boundary we can’t see how the software actually computes the cosine. Perhaps, for example, instead of actually computing a Taylor series in real-time, our software will merely look up the cosine in a table of pre-computed values which might be a good design for a very time critical system, lookup of a pre-computed value usually being much faster than dynamic computation. If we’re serious that a requirement must specify observable behavior, and we should be, we must conclude that computation via some specified algorithm (e.g., a Taylor series) cannot in and of itself be a requirement. We’ll examine this subject in more detail later; but the conclusion will still stand: An algorithm cannot be a requirement. p. 24 of 54 Fundamental Concepts and Issues in Software Requirements and Design 2.2.2 Are “thou shalt never …” requirements really requirements? Particularly in requirements for safety critical software, we often see statements like, “the software shall never … [do something bad, like command the nuclear reactor to go to more than 110% power].” Is such a statement a requirement? It would certainly be observable if our software did produce an output that we didn’t want; but how could we observe or test the “never” part of such a requirement? I think the point here is this: Not only must our requirements describe the characteristics of the outputs we want, the flip side is also true and all too often not stated explicitly: Our software must not produce any outputs that are not required. If our software does something else in addition to what we required it to do, either that’s unacceptable or our requirements documentation is incomplete and the acceptable but undocumented behavior needs to be added to it: It is not enough that software do what we want; it better not do anything else. How happy would you be with your email program if every time it sent out an email because you asked it to, it also decided on its own to send a copy to the KGB, the New York Times, or your mother? In terms of requirements, everything not compulsory is forbidden.15 Getting back to our nuclear reactor problem, if we write our re- quirements properly (completely) so that all possible input values lead to required output power levels less than 110%, then correct software that satisfies those requirements will not be capable of violating its “negative” (or “never”) requirements, since there will not be any set of inputs that could result in such an output. So we may be able to verify analytically that our software meets such a requirement even though no finite set of tests can demonstrate it. So is such a “thou shalt not …” statement a legitimate requirement even though it’s not testable? Perhaps, although I personally usually refer to such statements (“thou shalt never …”) as constraints (see below), but there’s no standard vocabulary in the field (literature or practice) that I’m aware of. 2.3 Constraints and Attributes There are two other words that are used quite often as part of these sorts of “theory of requirements engineering” discussions: constraint and attribute. But beyond the ordinary dictionary That’s a reversal of the line “Everything not forbidden is compulsory”. I always though t that line was from Orwell’s 1984, but it’s not; it’s from T.H. White’s The Once and Future King. 15 p. 25 of 54 Fundamental Concepts and Issues in Software Requirements and Design meaning, there’s no standard software engineering definition for either of them. Ask any two software engineers what’s the difference between a requirement and a constraint and the resulting argument, and usually there will be an argument, often starts to sound positively surreal. In the Middle Ages, before we had software, theologians used to argue how many angels could sit on the head of a pin; now we have software vocabulary as a basis for our pointless disputations. Plus ca change, plus c'est la meme chose.16 IEEE Std 830-1998 [6] uses both terms (constraint and attribute) and so apparently considers them to be two separate concepts but lists them as a category (or type) of requirement. But few engineers would use the word “constraint” to describe output characteristics, regardless of the fact that a pointless and abstruse argument about semantics can be made to justify such usage17. And many/most engineers would probably be reasonably happy lumping all the other stuff (maintainability, extensibility, etc.) under the category of “other constraints” or “other attributes” and noting that the set of such possible types of things is (1) unbounded, (2) not rigorously definable, and (3) never of the degree of universal applicability to all possible software development projects that output requirements are. Most requirements standards take a “kitchen sink” approach to these things and list as many as the authors thought important (and no two standards have exactly the same kitchen sink) and then make some sort of disclaimer that not all of them necessarily pertain to any given software project. For example, the old DOD-STD-2167A’s paragraph 1.5, Tailoring of this standard, states: “This standard contains a set of requirements designed to be tailored … . The tailoring process intended for this standard is the deletion of non-applicable requirements.” [7] 16 The more things change, the more they stay the same IEEE Std 830-1998 actually makes the case very concisely on page 9, paragraph 4.7: “Note that every requirement in the SRS limits design alternatives.” To limit is to constrain, so at least according to IEEE Std 830-1998 software requirements are constraints. I don’t know if that’s what the authors intended to say; but it certainly seems to be what they actually wound up saying. The real point, once again, is that since vocabulary is not consistent from document to document, it’s probably best for an engineer to have a really thorough understanding of the fundamental concepts and then try to adapt to whatever vocabulary any given organization or document tries to use. 17 p. 26 of 54 Fundamental Concepts and Issues in Software Requirements and Design A Department of Defense customer might easily agree that portability need not be a requirement for some piece of software (like, for hypothetical example, the avionics software for the F-16) for which custom hardware is already required, so portability is not likely to be of much importance. But I doubt that anyone would ever agree to ignore output characteristics. (“We don’t actually care what the software does so long as it’s portable and maintainable.” Right.) So what’s the point here? 1. Everyone agrees that output characteristics are the essential core of a requirements specification. They may not say it as explicitly as Parnas and his disciples (including me) do, but when properly interpreted (i.e., my way), the standards and procedures actually in use today make it clear enough. 2. Some of the other information that is correctly considered essential to requirements but that may not seem to be output related really is output related when looked at rigorously. The input capacity example we looked at earlier is a prime example of this. 3. All the other stuff, sometimes referred to as the –ilities (e.g., extensibility, portability, maintainability, etc.), may sometimes be important (it varies from project to project) but it’s not as central as outputs are to understanding software requirements and the requirements engineering process. And we can’t seem to agree on a complete set of categories for all this stuff anyway, nor whether any given category is really a requirement, a constraint, an attribute, or something else entirely. Bottom line: There’s general (if sometimes tacit) consensus that outputs and their observable characteristics are the essence of software requirements and that it might be better to use “constraint” or “other attributes” to describe anything else that should appear in the requirements document to guide subsequent analysis and design activities. But don’t become a religious zealot here. If your company wants to insist that reliability is a requirement, don’t argue the point until you’re senior enough to have some credibility. p. 27 of 54 Fundamental Concepts and Issues in Software Requirements and Design 3 How do we come up with requirements? We’ll answer this question in two parts: (1) Where do we start? What are the standard sources of information that will allow us to begin the requirements engineering process? (2) What do we need to do with that initial requirements data? 3.1 Source of requirements There are actually quite a few different sources of requirements information, not all of them necessarily applicable on any one project, but all quite relevant at some time or other to one project or other. 3.1.1 Allocation18 Many large projects, particularly government ones, start with some form of “high level”19 requirements statement or concept of operations followed by a high level design document often called a system specification. The number and nomenclature for such predecessor documents has varied over the years and from customer to customer but the one thing they always have in common is that they are a source of system requirements (more about this term later) some of which will be allocated to software in total or in part. E.g., if the system is going to be an air traffic control system, the system specification might include a statement like, for example, “the system must provide situation displays for up to 200 air traffic controllers per air traffic control center.” Part of that requirement will be allocated to hardware (“the display subsystem must provide 200 controller workstations, each featuring a high resolution monitor of size TBS20”) and part will be allocated to software the software must provide each controller with a geographical display of aircraft position, map data, and weather, along with alphanumeric display of aircraft data such as call sign, destination, etc. Such “system requirements allocated to software” [13] are obviously one source of initial information for software requirements. 18 Distribution according to a plan, according to http://www.thefreedictionary.com/allocation 19 We’ll be discussing the concept of “level” of requirements in the section on stepwise refinement, below. 20 TBS: To be specified [later]; a common placeholder for information not yet determined. TBD (to be determined) is also used for this purpose. p. 28 of 54 Fundamental Concepts and Issues in Software Requirements and Design 3.1.2 Elicitation Requirements elicitation is a fancy name for interviewing the customers or end users of the software to elicit their needs. There have been attempts made to provide a fairly formal framework for such interviews21 , but I’m not aware that any particular technique has achieved much wide spread success. You can (and should) dress it up a bit (some structure to such interviews is better than nothing at all) but ultimately it still comes down to asking your customers/users, “what do you want the software to do?” The results of course will often be fragmentary and fairly abstract (Dilbert has a lot to say on this point22), but nonetheless provide a crucial starting point for downstream stepwise refinement, to be discussed in detail, below (in section 3.2). 3.1.3 Interface analysis What we often call the “context” of a software system consists of all the external systems it interfaces with. A radar data processing system, for example, will obviously interface with one or more radars. Often, many such external systems are already in existence at the beginning of a new software project. In such cases, a blackbox description of their input/output characteristics, often called an interface specification, is therefore available right from the beginning (of a new software development project); their inputs will come from some of our our software’s outputs and their outputs will be some of our software’s inputs. Analysis of such interface documentation is a prime source of software requirements information. 3.1.4 Human-Machine Interface (HMI) design From one viewpoint, the HMI is just another interface, whose documentation, as discussed above, is a good source of requirements for the software that will drive it i.e., provide displays and computer generated controls for it (e.g., pull down menus). But the design of the human-machine interface is a specialized discipline in and of itself and produces specialized documents. These documents may go by different names in different environments. The U.S. Department of Defense, for example, usually calls them something like a concept of operations document and a set of operational sequence diagrams. Usually, they are produced by human factors engineers for review by customers/users, and often such work is done 21 See, for example, http://www.engr.sjsu.edu/~fayad/current.courses/cmpe202-fall2010/docs/Lecture-5/Tech-ReqElicitation-Paper.pdf 22 See http://dilbert.com/strips/comic/2002-02-20/ , http://dilbert.com/strips/comic/2006-02-26/, and http://dilbert.com/strips/comic/2006-01-29/, for example. p. 29 of 54 Fundamental Concepts and Issues in Software Requirements and Design before the software engineering job gets started. Such documentation would then be a rich source of requirements information for a downstream software development project. Often, however, the software engineering team itself is responsible for developing the HMI. 3.1.4.1 Conceptual HMI 3.1.4.2 Semantic 3.1.4.3 Syntactic 3.1.4.4 Lexical 3.1.5 Prototyping (including modeling and simulation) Although I’m sure purists might sneer, from the requirements engineering standpoint, I’m mostly going to lump prototypes, models, and simulations together as a single technique. Prototypes, particularly HMI prototypes, are a rich source of software requirements. If you’re not sure what the HMI should look like (i.e., what the requirements are), whip up some sample screens. They don’t even have to be interactive; there are many drawing packages available to draw up static but realistic images of what symbols for aircraft might look like when displayed or what menus might look like, what colors, what fonts, etc. It is much easier for customers and potential users to review such things in pictorial form. In practical terms, there is often no alternative; using narrative text to describe the details of visual phenomena is a fool’s errand. Such HMI models and prototypes are a major adjunct to requirements elicitation for the HMI. Interactive models (of the HMI) are even better than static pictures; but even static pictures seem to me to qualify as a form of HMI model. When the human factors types and the customers agree that they like the look-and-feel in the pictures, they can turn them over to the software team and say, “make the software displays and controls look like these pictures.” In other words, “here are some software requirements.” Prototyping, modeling, and simulation can all be used for algorithms as well as HMI. Now it’s true, as we discussed earlier, that an algorithm per se is never a requirement, but, as we will discuss later, it’s also true that sometimes we have no alternative except to run elaborate simulations or models and conclude that a given algorithm, say, for predicting where a maneuvering target will be 30 seconds into the future, is the best we can come up with. We still should be careful to word our requirement properly, the algo- p. 30 of 54 Fundamental Concepts and Issues in Software Requirements and Design rithm as a definition, as in, to continue our example, the software shall display a predicted position that is ±1/4 mile of the position defined by the following algorithm that we just spent two years and $106 modeling the effectiveness of … . So the algorithm is still not a requirement, it’s a definition used in stating the real requirement, and the details of the definition were developed by modeling and simulation. 3.1.6 Engineering judgment Particularly in the case of initial information received by allocation from a predecessor document or via elicitation from customers, it is often the job of the software engineer to take the initial information that is not yet sufficiently detailed and, via stepwise refinement (section 3.2), add more details based on engineering judgment. In other words, you study all the information from whatever starting points are available to you and then you fill in the blanks by guessing. (Aren’t “engineering judgment” and “informed synthesis” so much more impressive than “guessing”?) As a management issue, it is obviously important to have such synthesized requirements detail reviewed and approved by the customer, if at all possible, or by other experienced engineers, or both. But that’s a management issue more than software engineering one. With or without such review and approval (preferably with, obviously), engineering judgment by the software engineering team itself often accounts for a significant subset of the usually rather large volume of documented requirements details. 3.1.7 Engineering analysis, particularly completeness analysis Much requirements information comes from analysis of already existing requirements information. E.g., if we see a requirement to turn on the green light if the user has entered a valid authorization code, one would expect there should probably be another requirement somewhere stating what’s required as a response to an invalid user input. For another example, if we see a requirement to generate a valveOpen command, wouldn’t we also expect to see some other requirement somewhere to generate a valveClose command? Derivation of additional (sometimes known as “derived”) software requirements via such completeness and robustness analysis of an earlier set of software requirements is a complex subject that I may or may not provide an overview of later. (If I don’t and you’re interested, find a copy of my Ph.D dissertation somewhere.23 ;-) 23 Completeness, robustness, and safety in real-time software requirements specifications, see http://books.google.com/books/about/Completeness_Robustness_and_Safety_in_Re.html?id=m7RmpwAACAAJ p. 31 of 54 Fundamental Concepts and Issues in Software Requirements and Design 3.2 Stepwise refinement and functional decomposition Once some initial set of requirements has been identified, (presumably from one or more of the sources of initial requirements discussed above), requirements engineering for all but the simplest projects usually proceeds via what is called “stepwise refinement”, proceeding from the more abstract to the more detailed in a series of gradual steps. Even at the very beginning of a software development project, when we start to merely describe the purpose for which the software is to be developed, we are recognizably starting a stepwise refinement of output information. To state, for example, that the purpose of some software for use in the control room of a nuclear power plant is to control the operators’ coffee pot as well as the nuclear reactor itself is to say that the software must generate outputs to do those things. We may not yet know exactly how many separate outputs we’ll need, much less the detailed behavioral characteristics for each one, but identifying their existence and purpose(s) is a valid and essential first step. It’s a great deal more abstract than we’ll ultimately need, of course, but it’s a start. There have been a variety of techniques developed to organize requirements engineering (we’ll study at least two of them later), but an underlying principle for almost all of them was and is stepwise refinement and the concept is central to understanding and doing requirements engineering. It is not only the software requirements, by the way, that are developed via stepwise refinement, designs and tests are as well. (In fact, the concept of stepwise refinement seems central to the engineering of large complex systems of any sort, not just software; but that philosophic a discussion is beyond our scope here.) Later, we’ll look at how the concept of stepwise refinement pertains to software design as well, and how that fact contributes to the confusion between requirements and design. But for now I want to use the concept of stepwise refinement to try to clear up several common misconceptions about the nature of software requirements. 3.2.1 The stepwise refinement of requirements In requirements engineering, once you have some level of description of the intended goals, purposes, functions, or capabilities of your software (all of these terms have been used more or less interchangeably at various times in various standards and textbooks), a next obvious step is to p. 32 of 54 Fundamental Concepts and Issues in Software Requirements and Design start to identify individual outputs, but it can often be helpful to take smaller steps by breaking down our overall purposes into a set of smaller purposes or merely sub-groupings or aggregates of functionally related outputs. Perhaps, to continue our reactor control example, we still can’t yet identify our specific outputs, but we can note that we will need both pressure control outputs and temperature control outputs. The process can continue through as many steps as seem useful. E.g., perhaps reactor pressure control will require our software to generate some outputs for the control of pump speed and other outputs for opening or closing various valves. How many such steps of refinement are needed? There’s no simple answer to that question, since it varies from project to project and can even vary from one area to another within the same project. E.g., coffee pots probably being simpler than nuclear reactors, identifying the set of outputs necessary to control the coffee pot may take fewer steps than doing it for the reactor itself. Later we’ll see that there are some consequences to this variation in levels of refinement and detail. Is the stepwise refinement of requirements done when the individual outputs have been identified? Certainly not; we have quite a bit more work to do other than merely the identification of an output; we have to described each output’s required behavior and this description too very often benefits from stepwise refinement. E.g., consider the following steps in specifying the acceptable values for some output: (a) Software shall provide air traffic controllers with displays to aid them in their maintenance of their situational awareness (b) Software shall display aircraft position data (c) Software shall display aircraft position data graphically, overlaid on a map (d) Software shall display the aircraft position data graphically with an accuracy of ± 1 mile [± 1 mile of actual aircraft position] relative to the map p. 33 of 54 Fundamental Concepts and Issues in Software Requirements and Design (e) The software shall output an estimated x/y position for each aircraft that is within ± 1/10 mile of the value defined by the following equations: … [3 pages of Kalman filtering equations] Two questions come to mind here: 1. Are all those statements, above, legitimate software requirements? And if not, what are those that are not? 2. Is there any standard number of levels of refinement? Which is more or less the same question as, is there any standard nomenclature for different levels of requirements detail? E.g., what’s the difference between a system requirement and a software requirement? 3.2.2 Levels of requirements detail and the process versus product distinction So is a statement like, Software shall provide air traffic controllers with displays to aid them in their maintenance of their situational awareness a software requirement? I think it is; it states that some outputs are going to have to exist, which, since existence is an observable characteristic, makes it a statement about output characteristics, which makes it a valid requirement. The only possible reason I can see for saying that’s it’s not a software requirement would be to say that it’s so abstract or “high level” that it is better viewed as a system-level requirement, which, as we’ll discuss shortly, seems a somewhat pointless distinction. At the other extreme, at least one very influential software engineering theorist considers the lowest level of detail to be design, not requirements: “For example, the output data item … should change value, when the aircraft crosses 70 latitude; how the program detects this event is left to the implementation.” [4] I think the confusion in either case is at least partly due to a failure to bear in mind the product versus process distinction, the difference between an engineering product (e.g., a requirements p. 34 of 54 Fundamental Concepts and Issues in Software Requirements and Design specification or an implementation) and the process of producing it, a distinction that it’s important to keep in mind when trying to understand the jargon of requirements engineering. The identification of some outputs or classes of related outputs (e.g., air traffic control displays) may be done very early in the engineering process by people called systems engineers, as opposed to requirements engineers or software engineers, and documented in something called a system specification, and the final fleshing out and documentation of some of the behavioral details may not occur years later until the implementation phase when some coder adds some notes somewhere. But when in the overall software process the requirements information is developed seems to me is not as important nor as easy to unambiguously categorize as to what artifact the information pertains. Attempts to assign process-dependent categories such as “architectural requirement” 24, or “implementation” to software behavioral characteristics usually run aground because, as we saw earlier in this course, there’s no universal model or vocabulary for the phases of the software development process. Some models may include architectural design and detailed design as separate phases; other models don’t, for example. A project team that does not consider “architecture” a distinct design phase25 will probably have a different view of the necessity for, and the type of information to be included in, architectural requirements than a team that devoutly believes architecture is a different type of design than detailed design, for example. End result here? Trying to impose fuzzy categories like “system level” or “design” requirements on what are really just stepwise refinements of software output behavior is usually more trouble than it’s worth. There are dozens, if not hundreds, of books and web pages providing ad hoc taxonomies of “types” of software requirements, and no two of them have come up with the 24 See http://blogs.msdn.com/b/nickmalik/archive/2009/06/26/should-some-requirements-be-called-out-asarchitectural-requirements.aspx, for example. 25 Big projects are probably more likely to consider architectural design as a separate stage than are small ones. But so what? Does that mean small projects don’t do real software engineering? Hardly. And there are a lot more small software engineering projects than big ones. p. 35 of 54 Fundamental Concepts and Issues in Software Requirements and Design same taxonomy.26 Much, not all, but much, of the confusion is a result of a trying to develop or compare taxonomies which are based on a mix of when the information is first developed, what sort of people develop it, and the name of the document that records it. Such ad hoc taxonomies may be useful guides sometimes (rarely, in my opinion) but they certainly shouldn’t be thought of as providing any fundamental insights into the basic concepts of software requirements. 3.2.3 Abstraction, stepwise refinement, and “levels” of software requirements 3.2.3.1 Imperfect correlation between refinement steps and abstraction levels Stepwise refinement is a process; level of detail refers to the abstraction in the documentation product. The concepts are obviously related (a requirements specification probably gets pretty detailed after a dozen steps of refinement), but the two concepts don’t correlate as perfectly as we might like. Different levels of detail may be required for different areas of a project and it may take a different number of steps to get to what might seem to be the same level of detail. There are both practical and theoretical reasons for the imperfect matchup. 3.2.3.1.1 Practical reasons for the variation 3.2.3.1.1.1 Variation in starting point Any given software development effort often starts with differing pieces of its initial requirements at quite varying levels of abstraction. Perhaps the customer or user has thought through some areas much more thoroughly than others; perhaps there are even from the beginning detailed interface specification for existing systems with which the new software must interface (i.e., make outputs to) whereas there will obviously be no such details on systems that don’t exist yet but are still in the “conceptual” stage of their own development cycle. Perhaps a detailed but incomplete simulation or prototype is available for some parts of our system but not others. The point here is that the starting points for different projects or even different parts of a single pro- 26 For example, compare the Wikipedia article at http://en.wikipedia.org/wiki/Requirements_analysis, the section on “Types of Requirements” with http://www.accompa.com/requirements-management-blog/2012/04/types-ofsoftware-requirements/ . p. 36 of 54 Fundamental Concepts and Issues in Software Requirements and Design ject can vary widely in the level of requirements detail available at the very start and unless some consumer community (e.g., trainers, people who will train the system’s end users) needs a more abstract view, there’s usually no obvious advantage to going backwards and trying to document all the missing abstract requirements if the more detailed ones are already documented. 3.2.3.1.1.2 Variation in stopping point Just as there is no standard starting level of requirements abstraction, there is no standard stopping level either. Different types of projects or even different parts of the same project may need to provide different levels of detail. In theory, at the lowest level of detail, we could provide a mathematical function describing the relationship between each individual bit of an output and the bit values of prior inputs. I know of no engineering project that has ever done this. Perhaps the shortest step up in abstraction is the concept of a “field”, a bunch of related bits. Most projects probably eventually specify output requirements in terms of required fields – e.g., … the software shall output aircraft kinematic data in Cartesian (x, y) coordinates and (𝑥̇ , 𝑦̇ ) velocity components. They may or may not call the details requirements, but whether they think of them as requirements or design (or even interface specification) they usually do, eventually, produce a written specification of acceptable field values for each field; e.g., … the output of flight level, FL, shall be in units of 100 feet above mean sea level from 0 to 100,000', so 0 ≤ FL ≤ 1000, accurate ±100' But consider the development of an app for an iPad. Can the outputs from the app be regarded as being composed of fields? Surely. Is there usually a written specification of the acceptable characteristics for each field (e.g., color, font, location on the screen, etc)? Probably not very often. Almost certainly, the requirements for iPad apps are originally expressed at a fairly high level of abstraction e.g., let’s have an app to display a clock and the weather forecast at our location and then the project proceeds into a prototyping phase to develop a “look-and-feel” p. 37 of 54 Fundamental Concepts and Issues in Software Requirements and Design that the various stakeholders, whoever they are, ultimately agree is acceptable. So does the software have detailed behavioral characteristics? Surely, no way to avoid it. But no one wrote down the requirements for them. The desired appearance and behavior were probably developed by prototyping and the requirement, probably not even stated explicitly was, “make the real thing look and feel like the prototype”. Now consider our old friend the nuclear reactor controller. OK to just have a high-level statement of capabilities (e.g., control the rod positions) and then start experimenting with prototype code on a real reactor to see if it blows up or not? No? So a reactor control project probably needs to provide more detail in its requirements than does an iPad app. The point to remember here is that there is no standard level of abstraction for either the starting or stopping points of the requirements engineering process and this variation can even occur in different areas within the same project, much less between projects. 3.2.3.1.1.3 The omission of unnecessary intermediate levels When doing stepwise refinement, we shouldn’t force the documentation of levels that we don’t need. Looking again at the air traffic control display example earlier, it’s not clear that we really did much interesting intellectual work going from (a) Software shall provide air traffic controllers with displays to aid them in their maintenance of their situational awareness to (b) Software shall display aircraft position data Maybe we never needed to explicitly state level (a) in writing since we knew (b) as soon as we started thinking about these requirements at all. Fine; stepwise refinement is a tool, not a religious ritual; it should be used when it’s useful and not when it’s not and some judgment is always required. But in general, more levels of stepwise refinement to the final stopping point provide more and earlier opportunities for review and smaller conceptual leaps from each level to the next, thus reducing the likelihood of misunderstanding. Waiting until the requirements p. 38 of 54 Fundamental Concepts and Issues in Software Requirements and Design document is thousands of pages long before asking customers and other engineers to review it is likely to be pretty inefficient. How many intermediate products should be prepared for review by whom and how to impose some degree of uniformity in level of detail within each one is a very non-trivial project management issue that’s our field has never successfully answered with any degree of rigor whatsoever. 3.2.3.1.2 Theoretical (but real) variation in possible levels of abstraction The practical concerns discussed above, were intended to make it clear why different projects or different parts of a project might need a different number of refinement steps to achieve different levels of detail at the end. But they don’t shed any light on the perennial quest to develop a standard set of well defined levels of abstraction – e.g., system level requirements versus subsystem level requirements versus high level software requirements versus low level software requirements versus design requirements, ad freaking nauseum. I understand the attraction of such a hierarchy, but I think the quest is quixotic and the reasons are relevant to our discussion here with regard to the fundamental concepts of software requirements. 3.2.3.1.2.1 Value and time needn’t share the same number of levels of abstraction As we discussed earlier, for each output there are obviously several distinct types of information that must ultimately be documented, including both value and timing information. They both obviously permit various levels of abstraction and there’s no obvious correlation between the levels of abstraction for time and levels of abstraction for value. The earlier example of levels of abstraction in the requirements for the display of aircraft symbology for air traffic controllers illustrated different levels of abstraction in the description of required values. The timing information similarly can be described at different levels of abstraction, e.g., 1) The software shall keep the displayed symbols’ positions up-to-date 2) The software shall refresh the displayed symbols’ positions periodically 3) ... every 0.5 seconds 4) ... every 0.5 seconds ± 0.1 seconds p. 39 of 54 Fundamental Concepts and Issues in Software Requirements and Design 5) ... every 0.5 seconds ± 0.1 seconds phase locked to an external clock (as opposed, for example, to relative to its previous periodic output) There’s no obvious relationship between the number of useful levels of abstraction for such timing information and the number of useful levels for value information, which has certainly complicated any attempts to develop standard names for different levels of requirements in general. 3.2.3.1.2.2 Intrinsically missing levels of abstraction in some requirements There’s also a problem of intrinsically inapplicable levels of abstraction in certain requirements. Consider a requirement of the form, “the software shall display an output position that is accurate to within ± ½ mile of the actual position of the actual aircraft.” That seems a useful “intermediate” level of abstraction for some value requirement intermediate because eventually a lower level of abstraction will need to be specified, e.g., “the software shall output a position for the aircraft that is within ±¼ miles of the reference value defined by the following algorithm: … .” Now consider an apparently quite similar requirement to display a recommended course for an interceptor to steer to intercept a target, “the software shall display a recommended course to steer that is within ±3 of ...?” Of what? There’s no physically observable phenomenon to use as a reference for the course to steer requirement that matches in abstraction the reference in the position requirement. It thus seems to me that we are left with little alternative but to conclude that some requirements or pieces of requirements can intrinsically have more possible levels of abstraction than others; which again makes it difficult to come up with any standard number of levels and nomenclature for them. In summary, then, there is no standard vocabulary for describing or categorizing different levels of detail other than the obvious but not terribly informative “higher or less detailed” and “lower or more detailed”. And, for the reasons discussed above, it seems unlikely that any such standard with a sound philosophic foundation can be developed, not that that has stopped people from trying. The only practical advice I can give a young engineer here is that when someone else refers to something like “high level” or “low level” software requirements, try, without being p. 40 of 54 Fundamental Concepts and Issues in Software Requirements and Design obnoxious about it, to get them to provide examples. Don’t bother asking for definitions, just examples. And if you are given definitions, take them with a large grain of salt.27 3.2.3.1.3 Some consequences: System requirements versus software requirements again The phrase “software-intensive systems” is in pretty widespread use (there’s an IEEE standard, for example [5] ) and its definition seems obvious from the phrase itself: Many systems, e.g., an autopilot, have both hardware and software components but many or all of the most important requirements for such a system are related to its software outputs – i.e., the autopilot only exists to generate outputs that will drive actuators for control surfaces even though there will certainly be important requirements or constraints on the autopilot hardware as well, so the whole engineering job is certainly more than just a software engineering job. The point being that there will almost certainly be (there certainly should be) some sort of system requirements document, but many of the requirements written there will sound exactly like what most of us would call very high level software requirements (oops, shit; even I use that damned “level” terminology sometimes). Contrast an autopilot with a dam, for example. The dam may eventually include software control systems for valves and generators, but no one would consider the most important characteristics of the dam to be related to software outputs the way an autopilot’s important characteristics are related to software. So, returning to our autopilot example of a softwareintensive system, if there is a document called a system requirements document that contains requirements about software outputs, are those system requirements or software requirements? It’s not clear to me that that’s a distinction worth making, to be honest; but it is clear that some engineers answer that question one way and others, the other – there’s no agreement on that vocabulary, in other words. Again, the process/product distinction may be helpful here: My view: Some software requirements (product) may be developed early in the overall systems engineering process and initially documented in something called, for example, a systems requirements 27 RTCA DO-178C/EUROCAE ED-12C, Software considerations in airborne systems and equipment certification [13] discusses high level and low level requirements explicitly. The definitions provided remain contentious and attempts to clarify them have not been successful. Many practitioners (not all) regard them as close to useless, which is distressing, to say the least, in such an important safety standard. p. 41 of 54 Fundamental Concepts and Issues in Software Requirements and Design document or a systems specification, but at some point downstream in the engineering process such information will be treated as software requirements and will eventually probably be identified as such. To me, the when and where and level of detail don’t matter; they’re software requirements because they specify something about outputs that the software will eventually have to produce. In practical terms, if you wind up working on a software intensive system that uses some specification standard that calls for both a system specification and a software requirements specification (almost all military projects do); don’t lose too much sleep worrying about such things. If you are told to write some system requirements, ask if there’s an example somewhere from some other project which could give you a feel for the rough level of detail expected. As I mentioned before, if in some areas you somehow already know more details than seem appropriate for a “system-level” document, put in the details anyway; it’s almost never worth the trouble to try to work backwards, going up abstraction levels. The point of stepwise refinement is to help you get down to the details. Once you’ve got the details closer to the “real” requirements, the intermediate abstractions used to get there are not likely to be of much use to anyone. There are occasional exceptions to this observation, but for now, they’re irrelevant. 3.2.4 Stepwise refinement of the Human-Machine Interface When, as noted earlier, development of the HMI and its software requirements is to be done by the software engineering team 4 Are there different types of output requirements? Earlier, I deliberately chose to exclude from our discussions a great many (but not standardized) possible “types” of requirements (e.g., maintainability) that don’t relate to output characteristics and are generally understood to not be as “required” as output characteristics are. We’re then left with another interesting question, are there useful distinctions among different types of requirements relating to output characteristics? The answer is that it depends what you mean by “types”, and there are some particularly important concepts to be addressed in this regard. p. 42 of 54 Fundamental Concepts and Issues in Software Requirements and Design 4.1 Are functional and performance requirements distinct types of requirements? Maybe, but... . An obvious interpretation is that functional requirements describe what the software is supposed to do and performance requirements describe how well it must do those things; but for software, the concept of performance is not as well defined as we might like and there are issues to be aware of. Many software engineers, particularly those working on real-time, systems, often use “performance requirements” to refer to timing behavior and use “functional requirements” to refer to value characteristics, as in, the output value must look like some specified mathematical function of the input value; but it’s not that simple. 4.1.1 The term “functional” is overloaded. In the first place, in order for the software’s behavior to be considered acceptable, it must surely meet its specified timing requirements. If it doesn’t, it is, to say it colloquially, not working properly. Another way to say “not working properly” is “non-functional”, as in, without a motor in it, my car is non-functional. So software is functional only when it’s meeting all its output requirements, including its timing requirements, which are nonetheless not functional requirements? In other words, the set of requirements that the software must satisfy to be considered functional is bigger than the set of its functional requirements? The problem here is our overloading of the word “function”, which sometimes is used a synonym for “purpose” (e.g., the function of the software in this computer is to control the nuclear reactor) and sometimes refers to a mathematical relationship, e.g., y=f(x). The former usage includes timing requirements, the latter doesn’t. Both uses appear often in the literature. 4.1.2 There may be performance requirements that are not timing related. Required accuracy, for example (e.g., the ± 0.1 miles in a requirement to output an aircraft position ± 0.1 miles) is sometimes considered a performance requirement but sometimes not. The IEEE Standard Glossary of Software Engineering Terminology [8], in its definition for “performance requirement” includes accuracy as an example of a performance requirement. But then the IEEE Std 830-1998 lists accuracy as a functional requirement. Published opinions about p. 43 of 54 Fundamental Concepts and Issues in Software Requirements and Design functional versus performance requirements continue to be inconsistent in this area (accuracy as a functional or a performance requirement) and others as well. For another example, consider Google. I just recently read somewhere that Google is once again seeking to “improve the performance of its search engine”. That particular use of the word performance does not refer to timing at all but to a qualitative assessment of the utility of the order in which search results are displayed. Google’s users want to see the most relevant results first and Google certainly wants to oblige them. My guess is that most engineers who use the phrase “functional requirement” (I try to avoid it myself) would agree that displaying a list is a functional requirement and so asking, or trying to specify, how “good” Google’s list of search results must be seems to be talking about the performance of a functional requirement. And that use of “performance” has nothing to do with timing (and it seems to me it’s a bit too much of a stretch to call it accuracy). Perhaps it would be better to say that there are two types of performance, timing performance and value performance. It would certainly make a nice, clean requirements engineering rule to say that every output value has to have a timing performance requirement (e.g., within ¼ second of the trigger event) and also a value performance requirement like accuracy, or something more complicated, as in the Google example. I actually like that idea (distinguishing between value performance and timing performance) but you need to be aware of two points: First, that jargon is pretty much my own, I’ve not seen it in print anywhere (never looked for it, to be honest); and second, not all outputs seem to have value performance requirements. If, to change back to a simpler example, the value of some output must be the count of students currently enrolled in SE300, it does not seem to make sense to ask how good that count must be (the value performance, in other words). Similarly, I can’t see a relevant performance metric for the output of a string value – e.g., the last name of some person. From a purists point of view I suppose we could just say that those are degenerate cases with a value accuracy of ±0; but to me that seems pretty pointless. The end result as I see it is as follows: p. 44 of 54 Fundamental Concepts and Issues in Software Requirements and Design 1) Some output values need value performance requirements, some don’t. 2) Classifying a given output field (or even the entire output, as in the Google example) as requiring a value performance requirement is part of the stepwise refinement of that output. We may be able to decide that a field needs an accuracy (or other performance requirement, a la the Google list) long before we know exactly what the details of that value performance requirement need to be. That’s part of what stepwise refinement is all about. 3) Numeric accuracy should be considered a value-performance requirement 4) Some value-performance requirements, like the “goodness” of the Google list, can be much more complicated than simple numeric accuracy 4.1.3 Theoretic limitations Although in practice we can usually state the requirements for output values without reference to output times and vice versa, there’s no reason in theory that they are necessarily so easily separable. We could, for example, require that the value of an output represent the time in seconds from program startup to the appearance of the output. That’s it; the only requirement on that output. It is observable, testable, and a complete characterization of acceptable behavior (for that one output). The software may not ever produce that output (or it may produce gazillions of instances), but if it ever does, we know how to determine whether or not a given occurrence is compliant with the requirement. So which part is the functional part and what’s the timing performance part? Would this be a useful real world output? I doubt it, but so what? My point is that there doesn’t seem to be any theoretic basis for asserting that functional and performance requirements can be cleanly separated. So there doesn’t seem to be any standard way to define performance and functional requirements unambiguously and in practice there has been confusion and inconsistency in the published literature in this area for decades. As a practical matter, whenever you encounter the term “functional”, one of your first concerns should be to resolve the “purpose” versus “mathematical function” p. 45 of 54 Fundamental Concepts and Issues in Software Requirements and Design ambiguity. It’s not that there’s really a right choice or a wrong one, it’s just that you need to know which meaning is intended in the context the term appears. Eventually, when actually doing the requirements engineering, you’ll need to determine which output fields need value-performance requirements and, perhaps more importantly, how to express them in observable terms. Numeric accuracy as a value-performance requirement is easy to express; a verifiable performance requirement for Google’s search item ordering is harder. In reality, for something like Google’s list, we may never come up with a meaningful performance requirement for some of our value requirements; we may just have to skip that level of stepwiserefinement. Instead we may do quite a bit of modeling, simulation, or other analysis and eventually come up with an algorithm that seems “good enough”, having never explicitly defined what we mean by that in other words what the “true” value-performance requirement is. Use of a “good enough” algorithm in a requirements document is thus actually a pretty common practice, but we shouldn’t be lazy about it: If we can, in fact, define “good enough” in observable terms we really should do so and leave the actual algorithm until later, in the design documentation. But if we can’t, we can’t; which is why so many requirements documents are so loaded with algorithms that the boundary between requirements and design seems to have been thoroughly blurred. But it need not be quite as blurry as it sometimes appears: The real requirement, remember, is still just to produce something that merely looks like it was computed by the specified algorithm, not to actually compute using the specified algorithm. Careful choice of wording can make that clearer. Not, compute the sin of using the following Taylor series algorithm, but, the output must be within ±0.001% of the reference value defined by the following algorithm: … 4.2 Other types of output requirements Even after eliminating what are sometimes called the “ilities” (e.g., maintainability, extensibility, etc.) and many other possible requirement types because they are not related to outputs, there are still quite a few other “types” of output-related requirements floating around various textbooks, articles, and web sites. Most have no standard usage or intellectual rigor to recommend them and tend to be one author’s view of something that, although it may be interesting sometimes, is p. 46 of 54 Fundamental Concepts and Issues in Software Requirements and Design not broadly applicable to software in general. E.g., what applicability do business rules28 have to avionics software? But there are a couple of terms that are in general enough usage that we should discuss them here: robustness requirements and derived requirements. In my opinion, neither one of them is actually a distinct type of output requirement but instead each refers to distinctions in the process i.e., when or how in the requirements engineering process these “types” of requirements are developed. 4.2.1 Robustness requirements Robustness requirements refer to output requirements in response to off nominal or invalid inputs; and usually we don’t get around to worrying about such things until we’ve first figured out what our outputs should look like in response to valid inputs. The concept and terminology seem intuitively useful, but there’s nothing intrinsic to any output requirement itself that identifies it a robustness requirement. Here, for example, are two possible related requirements: 1. If the input value is < 100, the software shall turn on the blue light within ¼ second. 2. If the input value is ≥100, the software shall turn on the orange light within ¼ second. Which one is the robustness requirement? Or perhaps neither of them is perhaps there’s no “invalid” data, just one of two different outputs desired depending on some input value. And that of course is the key: As we’ll discuss later, a complete requirements specification should include requirements to deal with all physically possible input values. Which one(s) represent “nominal” behavior and which, if any the “robustness” is not intrinsic to the requirement. We may not get around to thinking about robustness until long after specifying the nominal requirements, but once we do so, the robustness requirements are just requirements like any others. Since robustness is not an intrinsic characteristic of a requirement, I think it better to regard it as 28 One very well known textbook [10] seems to state that all software requirements are business rules or at least are derived from business rules (derived by what I would presume is stepwise refinement); various online documents say similar things (see http://scn.sap.com/docs/DOC-20035, for example). The point here is not that there’s no relationship between business rules and software requirements for business related software; the point is that it doesn’t make sense to regard business rules as a type of requirement as universally applicable as output characteristics. p. 47 of 54 Fundamental Concepts and Issues in Software Requirements and Design a process distinction rather than a type distinction usually we try to develop and document the requirements for nominal input data first; later we think about robustness to come up with some other requirements, i.e., outputs to be made when input data is off-nominal. 4.2.2 Derived requirements Derived requirements are similarly process based. Once we realize, for example, that we’ll be making outputs to some external system and we look up its interface and communication rules in its documentation, we discover that before it will accept the outputs we want to make to it, we first have to do some initial handshaking to establish our identity or agree on the protocol we’ll use. So we have some new output requirements to initialize the interface. These new requirements would generally be considered to be derived requirements, but once again, there’s no standard meaning for the phrase (derived requriemts). The phrase is also sometimes/often used to refer to relationships from the stepwise refinement process itself as when a more detailed requirement is said to be derived from an earlier, more abstract predecessor. So as far as I can tell, identification of a requirement as a robustness or derived requirement doesn’t tell us anything about the information we need to specify or how to specify it. Instead, it refers to the relationship between some requirement and some other requirement(s) that we specified earlier. Although they’re possibly/probably useful as intuitive concepts for helping understand the sequencing of some aspects of the requirements engineering process itself, their too casual usage as designating distinct “types” of requirements is an unfortunate habit that should be avoided. The Wikipedia entry on “Requirements Analysis”29 contains a large collection of “types” of requirements that are overlapping, far from universally agreed to, incomplete (in that there are lots of other types in the literature), and of dubious real world utility in any event (so I suppose the incompleteness really doesn’t matter much either; who cares if other equally pointless types have been omitted ;-) Perhaps what such articles should say instead is that, as part of the process of 29 http://en.wikipedia.org/wiki/Requirements_analysis p. 48 of 54 Fundamental Concepts and Issues in Software Requirements and Design developing requirements, one should consider such factors as robustness, business rules, et cetera. 4.3 Types of requirements versus pieces of requirements Another source of difficulty in standardizing “types” of requirements is that there is no standard definition for the phrase “a requirement” all by itself – note the singular article there. If we want to say that some requirement is of type T, we presumably need to have some idea as to what information needs to be included in the requirement by virtue the fact that it is of type T, otherwise what’s the point of identifying types of requirements at all? For example, is a number like ¼ second used in describing a required response time limit: A requirement in and of itself (so in this case a requirement could be a single number), or One of two necessary pieces of information for a single timing requirement – e.g., the earliest possible time the output is allowed to (start to) appear is the time of some button being pushed and the latest acceptable time is the time of that button push + ¼ second, so that in this case, a requirement is a pair numbers, or Just one of many pieces of the total set of information needed to specify a single output requirement – i.e., the sum total of all the information necessary to characterize the acceptable behavior for a single output. The point here, in our discussion of types of requirements, is that what many people would consider a genuine “type” of requirement (e.g., a stimulus-response requirement versus a periodic) can, and often is, equally well viewed by other practitioners as merely a description of the options for some piece or pieces of a complete output requirement rather than a type of requirement in and of itself. There’s no standard usage here and thus little likelihood of any standard set of types of requirements. Personally, I usually try to refer to such pieces without using the word “requirement” e.g., response time limit of some output rather than response time requirement. But most working engineers are not usually so scrupulous, although in this particular case, it seems a minor peccadillo. The important point is that rather than argue about the existence of different types of requirements, focus on making sure you know and have specified all infor- p. 49 of 54 Fundamental Concepts and Issues in Software Requirements and Design mation necessary to describe the acceptable behavior of some output: value, timing, trigger, and other preconditions. 5 Issues with requirements documentation 5.1 Textual requirements standards Internal interfaces, intentional and accidental. 5.2 Model based requirements documentation 5.3 Prototyped requirements 6 Explicit versus implicit design methodologies One result of the more or less inevitable intertwining of requirements and design is that several decades back, some theorists started to distinguish between what were called explicit and implicit requirements and design methodologies.30 Explicit methodologies try to keep the requirements engineering processes (activities) and their work products strictly separate from design i.e., the requirements process is to produce a blackbox requirements specification, the design process is to produce a design specification which is simple and nicely intuitive from a theoretic point of view but generally not workable in practice for the various reasons we’ve discussed here. Implicit methodologies started to be developed when some theorists realized that, since the distinction (between requirements and design information) was difficult if not impossible to maintain, we should think about the best way to go about doing them together just because they’re going to be intertwined doesn’t mean there aren’t better and worse ways to intertwine them. “Accidental” design, as we discussed earlier, is rarely likely to be very good. Yes, it’s preliminary and The concept is not at all original with me it was used by a professor of mine in graduate school, Dr. Peter Freeman at UC Irvine but I am currently unable to find an attribution for it. (And my old professor, Dr. Peter Freeman, has not answered the email I sent him.) 30 p. 50 of 54 Fundamental Concepts and Issues in Software Requirements and Design subject to change; but preliminary work often (always?) biases later work people are reluctant to go backwards; there’s pressure to just accept what’s been done and move on. Most “standard” software engineering methodologies in use today are now deliberately (as opposed to accidently) implicit ones and they fall into two major categories: transformationally intensive and transactionally intensive: Transformationally-intensive systems. Transformationally (or algorithmically) intensive systems are those where the difficult part of the software requirements is in the specification of the mathematical transformations that describe the required relationship of the input data to the output data. A system like the radar data processing one discussed earlier is transformationally-intensive. The design of a transformationally-intensive system is driven by considerations of coupling and cohesion (subjects we’ll discuss in some detail later) among processing (transformational) entities. Transactionally-intensive system. Transactionally-intensive systems are those where the data transformations relating inputs to outputs are not mathematically complicated, but there are a great many seemingly distinct outputs (transactions), most of them a function of several, often a great many, different and apparently unrelated inputs with complex inter-relationships among them. A system like Blackboard, which can display a list of classes a student is enrolled in, a list of announcement from all a student’s classes, a roster of students for a given class, a list of assignments for a given class, the details of a single assignment, a spreadsheet of grades for all the assignments, et cetera, is transactionallyintensive. For transactionally-intensive systems, descriptions of what’s required tend to be procedurally oriented rather than mathematically oriented e.g., search the database, find the student, find the classes the student is enrolled in, find the announcements from those classes, put them in a list, and display them. The design of transactionallyintensive systems tends to be data driven, in that the design reflects the relationships among the data items. p. 51 of 54 Fundamental Concepts and Issues in Software Requirements and Design In reality, few systems are purely transactional or transformational; the definitions are not sufficient precise as to be unambiguously disjoint. Many systems are a mix of both aspects, so the two terms really describe the endpoints of a continuum. But the distribution of systems along the continuum is far from uniform. Most systems fall fairly obviously towards one end or the other lots of diverse data types with few complicated transformations or lots of complex transformations on a conceptually simple set of data items. The reason the distinction matters at all is that the two most successful methods for getting started on requirements engineering are oriented to the two different endpoints data flow analysis for transformationally-intensive systems and object-oriented analysis for transactionally-intensive ones, both of which we’ll discuss in some detail later. Both data flow and object-oriented analyses, being implicit methodologies, produce a preliminary, abstract model of the system as a means of managing the requirements development and organizing the requirements documentation. The models (data flow or class diagrams) include data flows or data classes that are not necessarily directly observable in the software’s outputs, which is why these techniques are not “explicit”, or pure blackbox. But these abstract entities turn out to be a good basis for subsequent design. So although at the beginning, the intent of both techniques is to focus on requirements, the documentation results mix observable characteristics (requirements) with abstract design information, which, as previously noted, is one of the reasons the distinction in practice between requirements and design is rather blurred. p. 52 of 54 Fundamental Concepts and Issues in Software Requirements and Design 7 References [1] Swartout and Balzer, "On the inevitable intertwining of specification and implementation," Communications of the ACM, vol. 25, no. 7, p. 438–440, July 1982. [2] F. Bauer, "Software Engineering is that part of Computer Science which is too difficult for the Computer Scientist," [Online]. Available: http://en.wikiquote.org/wiki/Friedrich_Bauer. [3] Parnas and Clements, "A rational design process: How and why to fake it," IEEE Transactions on Software Engineering, vol. 12, no. 2, Feb 1986. [4] K. Heninger, "Specifying software requirements for complex systems: new techniques and their applications," IEEE Transactions on Software Engineering, vol. SE6, p. 213, Jan 1980. [5] IEEE 1471: IEEE Recommended Practice for Architectural Description of Software-Intensive Systems., 2000. [6] IEEE Std 830-1998, Recommended Practice for Software Requirements Specifications. [7] DOD-STD-2167A, Military Standard, Defense System Software Development. [8] IEEE Std 610.12 Standard Glossary of Software Engineering Terminology, 1990. [9] N. Leveson, Safeware. [10] Sommerville, Software Engineering. [11] G. Weinberg, An Introduction to General Systems Thinking. [12] MIL-STD-498 Software Development and Documentation. [13] RTCA, DO-178C Software considerations in airborne systems and equipment certification, 2012. p. 53 of 54 Fundamental Concepts and Issues in Software Requirements and Design p. 54 of 54