Reporting the Strength of Effect Estimates for Simple Statistical Analyses
This document was prepared as a guide for my students in Experimental
Psychology. It shows how to present the results of a few simple but common statistical
analyses. It also shows how to compute commonly employed strength of effect
estimates.
Independent Samples T
When we learned how to do t tests (see T Tests and Related Statistics: SPSS),
you compared the mean amount of weight lost by participants who completed two
different weight loss programs. Here is SPSS output from that analysis:
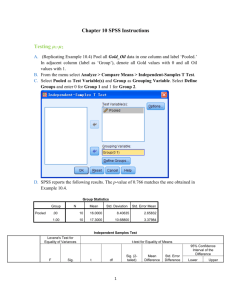
Group Statistics
LOSS
GROUP
1
2
N
6
12
Mean
22.67
13.25
Std. Deviation
4.274
4.093
Std. Error
Mean
1.745
1.181
The difference in the two means is statistically significant, but how large is it?
We can express the difference in terms of within-group standard deviations, that is, we
can compute the statistic commonly referred to as Cohen’s d, but more appropriately
referred to as Hedges’ g. Cohen’s d is a parameter. Hedges g is the statistic we use to
estimate d.
First we need to compute the pooled standard deviation. Convert the standard
deviations to sums of squares by squaring each and then multiplying by (n-1). For
Group 1, (5)4.2742 = 91.34. For Group 2, (11)4.0932 = 184.28. Now compute the
SS1 SS2
91.34 184.28
pooled standard deviation this way: spooled
4.15 .
n1 n2 2
16
Finally, simply standardize the difference in means:
M M 2 22.67 13.25
g 1
2.27 , a very large effect.
s pooled
4.15
An easier way to get the pooled standard deviation is to conduct an ANOVA
relating the test variable to the grouping variable. Here is SPSS output from such an
analysis:
Copyright 2012, Karl L. Wuensch - All rights reserved.
Strength_of_Effect.docx
2
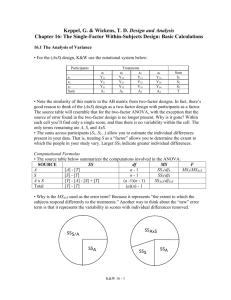
ANOVA
LOSS
Between Groups
W ithin Groups
Total
Sum of
Squares
354.694
275.583
630.278
df
1
16
17
Mean Square
354.694
17.224
F
20.593
Sig.
.000
Now you simply take the square root of the within groups mean square. That is,
SQRT(17.224) = 4.15 = the pooled standard deviation.
An easier way to get the value of g is to use one of my programs for placing a
confidence interval around our estimate of d. See my document Confidence Intervals,
Pooled and Separate Variances T.
Here is an APA-style summary of the results:
Persons who completed weight loss program 1 lost significantly more
weight (M = 22.67, SD = 4.27, n = 6) than did those who completed weight loss
program 2 (M = 13.25, SD = 4.09, n = 12), t(9.71) = 4.47, p = .001, g = 2.27.
Do note that I used the separate variances t here – I had both unequal sample
sizes and disparate sample variances. Also note that I reported the sample sizes,
which are not obvious from the df when reporting a separate variances test. You should
also recall that the difference in sample sizes here was cause for concern (indicating a
problem with selective attrition).
One alternative strength of effect estimate that can be used here is the squared
point-biserial correlation coefficient, which will tell you what proportion of the variance in
the test variable is explained by the grouping variable. One way to get that statistic is to
take the pooled t and substitute in this formula:
t2
4.5382
2
rpb 2
.56. An easier way to get that statistic to
t n1 n2 2 4.5382 6 12 2
compute the r between the test scores and the numbers you used to code group
membership. SPSS gave me this:
Corre lations
GROUP
Pearson Correlation
N
LOSS
-.750
18
When I square -.75, I get .56. Another way to get this statistic is to do a one-way
ANOVA relating groups to the test variable. See the output from the ANOVA above.
SSbetween 354.694
.56. Please note that 2 is the same
The eta-squared statistic is
SStotal
630.278
as the squared point-biserial correlation coefficient (when you have only two groups).
When you use SAS to do ANOVA, you are given the 2 statistic with the standard output
(SAS calls it R2). Here is an APA-style summary of the results with eta-squared.
3
Persons who completed weight loss program 1 lost significantly more
weight (M = 22.67, SD = 4.27, n = 6) than did those who completed weight loss
program 2 (M = 13.25, SD = 4.09, n = 12), t(9.71) = 4.47, p = .001, 2 = .56.
One-Way Independent Samples ANOVA
The most commonly employed strength of effect estimates here are 2 and 2
(consult your statistics text or my online notes on ANOVA to see how to compute 2). I
have shown above how to compute 2 as a ratio of the treatment SS to the total SS. If
you have done a trend analysis (polynomial contrasts), you should report not only the
overall treatment 2 but also 2 for each trend (linear, quadratic, etc.) Consult the
document One-Way Independent Samples ANOVA with SPSS for an example summary
statement. Don’t forget to provide a table with group means and standard deviations.
If you have made comparisons between pairs of means, it is a good idea to
present d or 2 for each such comparison, although that is not commonly done. Look
back at the document One-Way Independent Samples ANOVA with SPSS and see how
I used a table to summarize the results of pairwise comparisons among means. One
should also try to explain the pattern of pairwise results in text, like this (for a different
experiment): “The REGWQ procedure was used to conduct pairwise comparisons
holding familywise error at a maximum of .05 (see Table 2). The elevation in pulse rate
when imagining infidelity was significantly greater for men than for women. Among
men, the elevation in pulse rate when imagining sexual infidelity was significantly
greater than when imagining emotional infidelity. All other pairwise comparisons fell
short of statistical significance.”
Correlation/Regression Analysis
You will certainly have reported r or r2, and that is sufficient as regards strength
of effect. Here is an example of how to report the results of a regression analysis, using
the animal rights and misanthropy analysis from the document Correlation and
Regression Analysis: SPSS:
Support for animal rights (M = 2.38, SD = 0.54) was significantly correlated
with misanthropy (M = 2.32, SD = 0.67), r = .22, animal rights = 1.97 +
.175Misanthropy, n = 154, p =.006.
Contingency Table Analysis
Phi, Cramer’s phi (also known as Cramer’s V) and odds ratios are appropriate for
estimating the strength of effect between categorical variables. Please consult the
document Two-Dimensional Contingency Table Analysis with SPSS. For the analysis
done there relating physical attractiveness of the plaintiff with verdict recommended by
the juror, we could report:
Guilty verdicts were significantly more likely when the plaintiff was
physically attractive (76.7%) than when she was physically unattractive (54.2%),
2(1, N = 145) = 6.23, p = .013, C = .21, odds ratio = 2.8.
Usually I would not report both C and an odds ratio.
4
Cramer’s phi is especially useful when the effect has more than one df. For
example, for the Weight x Device crosstabulation discussed in the document TwoDimensional Contingency Table Analysis with SPSS, we cannot give a single odds ratio
that captures the strength of the association between a person’s weight and the device
(stairs or escalator) that person chooses to use, but we can use Cramer’s phi. If we
make pairwise comparisons (a good idea), we can employ odds ratios with them. Here
is an example of how to write up the results of the Weight x Device analysis:
As shown in Table 1, shoppers’ choice of device was significantly affected
by their weight, 2(2, N = 3,217) = 11.75, p = .003, C = .06. Pairwise comparisons
between groups showed that persons of normal weight were significantly more
likely to use the stairs than were obese persons, 2(1, N = 2,142) = 9.06, p = .003,
odds ratio = 1.94, as were overweight persons, 2(1, N = 1,385) = 11.82, p = .001,
odds ratio = 2.16, but the difference between overweight persons and normal
weight persons fell short of statistical significance, 2(1, N = 2,907) = 1.03, p = .31,
odds ratio = 1.12.
Table 1
Percentage of Persons Using the Stairs by Weight Category
Category
Obese
Percentage
7.7
Overweight
15.3
Normal
14.0
Of course, a Figure may look better than a table, for example,
Percentage
Figure 1. Percentage Use of Stairs
Weight Category
For an example of a plot used to illustrate a three-dimensional contingency table,
see the document Two-Dimensional Contingency Table Analysis with SPSS.
5
Copyright 2012, Karl L. Wuensch - All rights reserved.