Statistics 2014, Fall 2001
advertisement

1
Chapter 6 – Sampling Distributions
In most experiments, we have more than one measurement for any given variable, each measurement
being associated with one randomly selected a member of a population. Hence we need to examine
probabilities associated with events that specify conditions on two or more random variables.
Defn: A set of n random variables 𝑋1 , 𝑋2 , … , 𝑋𝑛 constitutes a random sample of size n from a finite
population of size N if each member of the sample, 𝑋𝑖 , is chosen in such a way that every member of
the population has the same probability of being chosen.
Defn: A set of (continuous or discrete) random variables X1, X2, ..., Xn is called a random sample if
the r.v.’s have the same distribution and are independent. We say that X1, X2, ..., Xn are independent
and identically distributed (i.i.d.).
Note: We will also use the term random sample to the set of observed values 𝑥1 , 𝑥2 , … , 𝑥𝑛 of the
random variables. Prior to selecting the sample and making the measurements, we have 𝑋1 , 𝑋2 , … , 𝑋𝑛 ,
with each 𝑋𝑖 being an (unknown) random quantity having associated probability distribution f(x).
After selecting the sample and making the measurements, we have 𝑥1 , 𝑥2 , … , 𝑥𝑛 .
Note: In practice, it is often difficult to do random sampling. However, random sampling is basic to
the use of the statistical inferential procedures that we will discuss later. These procedures are used for
analyzing experimental data, for testing hypotheses, for estimating parameters (numerical
characteristics of populations), and for performing quality control in manufacturing. In each situation,
we must somehow obtain convincing evidence that the data collected do approximate the conditions of
randomness.
Example : In a manufacturing situation, we have manufactured items coming off an assembly line.
These items are in continuous production, being finished, packaged, and shipped. We do not at any
given instant have access to the entire population of items. If we want to do sampling for quality
control, we must do systematic sampling. Assume that at any given instant, there are 36 items that
have been completed but are not yet packaged and shipped. We number these items from 1 to 36, in
order of production. We choose a random integer between 1 and 36, and select that item for
inspection. Assume that we have selected item number 23 out of that batch. Then, from the next batch
of 36 items coming off the assembly line, we would also inspect item number 23; and we would
inspect item number 23 for each succeeding batch. Do we have confidence that this type of systematic
sampling will give us a representative sample of the population of items? Why or why not?
If the manufacturing process is operating consistently, so that any variation from item to item is due to
chance, then the above method of sampling has a good chance to yield a representative sample from
the population. However, if there are occurrences in the process that, for example, lead to flawed
items at repeated, regularly-spaced time intervals, then this cyclical pattern would tend to prevent
systematic sampling from giving a representative sample.
2
The Sampling Distribution of the Sample Mean
Defn: A statistic is a random variable which is a function of a random sample. The probability
distribution associated with a statistic is called its sampling distribution.
Example: Let X1, X2, ..., Xn be a random sample from a population (probability distribution). The
statistic X
1 n
X i is called the sample mean. Since The Xi’s are random variables, then X is
n i 1
also a random variable, with a sampling distribution.
Some other examples of statistics are:
1 n
X i X 2 ,
n 1 i 1
2
1) The sample variance, S
2) The sample median,
~
X,
Theorem 6.1: Let X1, X2, ..., Xn be a random sample from a distribution having mean and standard
deviation . Then the mean of the sampling distribution of 𝑋̅ is:
n
i 1
X E X E X i
n
n
n
1
i 1
1
The variance of the sampling distribution depends on the size of the population from which the sample
is drawn. If the population is of infinite size, then
n
X2
i 1
1 2 2
.
n
n2
Or if the population is finite, of size N, then
2 N n
X2
.
n N 1
Note: The quantity
𝑁−𝑛
𝑁−1
is called the finite population correction factor. Note that if N is many times the size of n (as is often
the case), then
𝑓𝑝𝑐 =
𝑓𝑝𝑐 ≅ 1.
Note: The quantity 𝜎𝑋̅ (standard deviation of the sampling distribution of the sample mean) is also
called the standard error of the mean. It provides us with a measure of reliability of the sample mean
as an estimate of the population mean. This term will be important when we discuss statistical
inference.
Note: If the random sample was selected from a normal distribution (we write X1, X2, ..., Xn ~
Normal(, ) ), then it can be shown that
3
X ~ Normal ,
.
n
Example: On page 134, Exercise 5.33. If I randomly select a single assembled piece of machinery
from the population of assembled pieces, the time for assembly will be a random variable X having a
Normal(µ = 12.9 min., σ = 2.0 min.) On the other hand, if I select a random sample of size 64 from the
population, the distribution of 𝑋̅, the average assembly time for the sample of pieces, will have a
distribution that is
𝑁𝑜𝑟𝑚𝑎𝑙(𝜇𝑋̅ = 12.9 𝑚𝑖𝑛. , 𝜎𝑋̅ = 0.25 𝑚𝑖𝑛. ).
Note that the variability in the distribution of 𝑋̅ is only one-eighth the variability in the distribution of
X. This is an important concept.
Theorem 6.2 (Law of Large Numbers): Let X1, X2, ..., Xn be a random sample from a distribution
having mean and standard deviation . Then for any positive number ε, we can say that
𝑃(|𝑋̅ − 𝜇| > 𝜀) → 0 𝑎𝑠 𝑛 → ∞.
In other words, as the sample size increases unboundedly, the probability that the sample mean will
differ from the population mean by an arbitrary amount ε will decrease to 0. For larger samples, the
sample mean is more likely to be close to the population mean.
The Law of Large Numbers and Relative Frequency
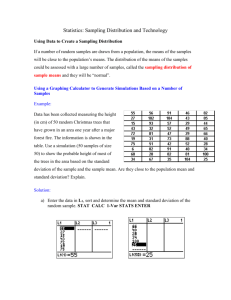
Example: (page 182) Let our random experiment consist of flipping a fair coin twice. Let the event A
= {at least one head}. What is P(A)?
We define a sequence of random variables X1, X2, ..., Xn by saying that 𝑋𝑖 = 1 if the ith performance
of the experiment results in at least one head (event A occurs), or 𝑋𝑖 = 0 if event A does not occur
(result of ith performance of the experiment is two tails).
The 𝑋′𝑖 𝑠 are i.i.d. random variables whose distribution has mean 𝜇 = 0.75 and variance 𝜎 2 = 0.1875.
(Why?).
Let
# 𝑜𝑓 𝑡𝑖𝑚𝑒𝑠 𝐴 𝑜𝑐𝑐𝑢𝑟𝑠 𝑖𝑛 𝑛 𝑡𝑟𝑖𝑎𝑙𝑠
𝑟𝑒𝑙𝑎𝑡𝑖𝑣𝑒 𝑓𝑟𝑒𝑞𝑢𝑒𝑛𝑐𝑦 𝑜𝑓 𝐴 =
.
𝑛
Now, in this case, the sample mean is the relative frequency of occurrence of A, and the probability of
occurrence of event A is 0.75.
The sampling distribution of the sample mean for n repetitions of the experiment will have mean 𝜇𝑋̅ =
𝜎2
𝜇 = 0.75, and variance 𝜎𝑋2̅ = 𝑛 =
sampling distribution decreases.
(0.75)(0.25)
𝑛
=
0.1875
𝑛
. Note that, as n increases, the variance of the
The Law of Large Numbers tells us that, as we perform the random experiment repeatedly, the value of
the sample mean will get closer and closer to the population mean. In this case, the relative frequency
of occurrence of event A will get closer and closer to the probability of occurrence of event A.
4
The following theorem is EXTREMELY important (as well as astonishing). This theorem provides the
basis for our procedures for doing statistical inference.
Theorem 6.3: (Central Limit Theorem) If X1, X2, ..., Xn are a random sample from any distribution
with mean and standard deviation
< +, then the limiting distribution of
X
as n + is standard normal.
n
Note: Nothing was said about the distribution from which the sample was selected except that it has
finite standard deviation. The sample could be selected from a normal distribution, or from an
exponential distribution, or from a Weibull distribution, or from a Bernoulli distribution, or from a
Poisson distribution, or from any other distribution with finite standard deviation. See, e.g., the
example on pages 179-180. See also the illustration on page 184.
Note: For what n will the normal approximation be good? For most purposes, if
that the approximation given by the Central Limit Theorem (CLT) works well.
n 30 , we will say
Example: p. 187, Exercise 6.15.
Example: The fracture strength of tempered glass averages 14 (measured in thousands of p.s.i.) and
has a standard deviation of 2. What is the probability that the average fracture strength of 100
randomly selected pieces of tempered glass will exceed 14,500 p.s.i.?
1
Example: Shear strength measurements for spot welds have been found to have a standard deviation of
10 p.s.i. If 100 test welds are to be measured, what is the approximate probability that the sample
mean will be within 1 p.s.i. of the true population mean?
The T Distribution
Use of the above discussion (Central Limit Theorem, etc.) to draw conclusions about the value of the
population mean, µ, from a measured value of the sample mean, 𝑥̅ , has a flaw. If we have to depend
on sample data for information about the population mean, then we would tend not to know the value
of the population standard deviation, either. We would also have to estimate σ. We need to modify
our theory somewhat to take this complication into account. We introduce another probability
distribution that allows us to use sample data alone to make inferences about the population mean.
Theorem 6.4: If 𝑋̅ is the mean of a random sample of size n taken from a normal distribution having
mean µ and standard deviation σ, and if
𝑛
1
2
𝑆 =
∑(𝑋𝑖 − 𝑋̅)2
𝑛−1
𝑖=1
is the sample variance, then the random variable
𝑋̅ − 𝜇
𝑆
( )
√𝑛
has a t-distribution with degrees of freedom ν = n – 1.
𝑡=
5
The t-distribution (which is actually a family of distributions, characterized by the degrees of freedom)
has characteristics similar to those of the standard normal distribution, as we can see from the figure on
page 187. Note that for large d.f., the t(n-1) distribution is very close to the standard normal
distribution. In fact, the standard normal distribution provides a good approximation to the t(n-1)
distribution for n of size 30 or more.
Note: Cut-off values and various tail probabilities for the t-distribution, with various values for ν, may
be found in Table 4 on page 516. Note that in order to use this table, we must know the degrees of
freedom in the particular exercise.
Example: page 188.
The Sampling Distribution of the Variance
The above discussion provides us with the tools to do inference about the value of a population mean.
If we want to do inference about the value of a population variance, 𝜎 2 , then we need to discuss the
sampling distribution for the sample statistic, 𝑆 2 , that we use to estimate the population variance. For
this, we need to introduce another family of probability distributions, the chi-square family.
Theorem 6.5: If 𝑆 2 is the variance of a random sample of size n taken from a normal distribution with
variance 𝜎 2 , then the random variable
(𝑛 − 1)𝑆 2 ∑𝑛𝑖=1(𝑋𝑖 − 𝑋̅)2
2
𝜒 =
=
𝜎2
𝜎2
has a chi-square distribution with degrees of freedom ν = n – 1.
Note: Cut-off values and various tail-probabilities for the chi square distribution, with various values
for ν, may be found in Table 5 on page 517. Note that in order to use this table, we must know the
degrees of freedom in the particular exercise.
Example: p. 190.
The F-Distribution
When we do analysis of experimental data, our conclusions about whether the experimental treatments
had an effect will be based on a statistic which may be imagined as a “signal-to-noise” ratio, with the
“signal” being the treatment effect (differences among the treatment groups) and the “noise” being the
variability of the data within treatment groups.
The sampling distribution of this statistic is given in the following theorem. This statistic may also be
used to do inference about the differences between two population variances.
Theorem 6.6: If 𝑆12 and 𝑆22 are the variances of independent random samples of size 𝑛1 and 𝑛2 ,
respectively, taken from two normal distributions having the same variance, then the random variable
𝑆12
𝐹= 2
𝑆2
6
has an F distribution with parameters 𝜈1 = 𝑛1 − 1 (the numerator degrees of freedom) and 𝜈2 = 𝑛2 −
1 (the denominator degrees of freedom).
Note: Cut-off values and various tail-probabilities for the F distribution, with various values for 𝜈1 and
𝜈2 , may be found in Table 6 on pages 518-519 (note that this table is an abbreviated version of an Ftable that would be used in practical situations). Note that in order to use this table, we must know the
values of the two degrees-of-freedom parameters in the particular exercise.
We will come back to the F distribution later in the course.