DF-position-paper-final-20150409
advertisement

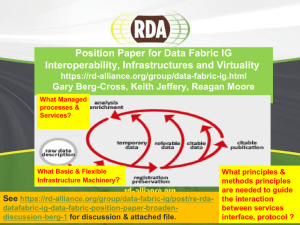
Data Fabric Position Paper: Berg-Cross, Jeffery, and Moore The Data Fabric Interest Group (DFIG) has gotten off to a rapid start with a draft white paper, acquisition of use cases, and presentations at Plenaries. Alternate views of the Data Fabric scope and purpose are now starting to emerge. The intent of this paper is present some ideas on these views and to promote discussion of them within the community Data Fabric Background and Motivation: Until now DFIG has concentrated mainly on (a) the data workflow within an e-research environment applicable in any domain and (b) how this relates to existing Research Data Alliance groups. The objective is to understand, through use cases, how research data is acquired, managed, manipulated, analyzed, simulated, and displayed in each of the domains and let emerge commonalities of process and (best) practice that may be re-used. From the DFIG web page: “The loose concept of the Data Fabric is a more nuanced view of data, data management and data relations along with the supporting set of software and hardware infrastructure components that are used to manage this data, along with associated information, and knowledge. This vision offers the possibility to formulate more coherent visions for integrating some RDA work and results.” Some members of DFIG wish to explore an additional, particular aspect of fundamental importance to RDA: interoperability. Put simply, we wish to bring interoperability (within and cross-domain) aspects into the DF discussions as a ‘first class citizen’ alongside all the other aspects of the research data lifecycle in a domain. Modern research and data management environments are varied across disciplinary projects with multiple types of data and processing resources. As a result in contrast with earlier silos of research that led to discipline specific data management solutions for Interoperability between the existing silos as well as between new emerging technologies, a higher degree of integration is essential for the construction of a data fabric for interdisciplinary research. Interoperability Vision for DF: Multiple projects are exploring construction of data management environments. The technologies they develop can be viewed as components of a data fabric, provided the systems are able to interoperate. The projects need to be expanded and generalized from specific domains into the larger research arena in part by engaging with RDA in order to further the advancement of data interoperability. Two use cases that illustrate these requirements are EUDAT and the DataNet Federation Consortium. Two major extensions to the data fabric vision are emerging from these use cases: 1. Interoperability mechanisms required for sharing data, information, and knowledge. This can be quantified as the sharing of digital objects that comprise the basic elements of research (observational data, experimental data, simulations); the sharing of provenance, descriptive, and structural information (stored as metadata attributes about the digital objects, users, and data fabric environment); and the sharing of knowledge procedures (stored as workflows, web services, and applications). It is not sufficient to make digital objects discoverable and retrievable. Researchers also need the ability to manipulate the digital objects, parse the data formats, and share the procedures. The ability to share procedures has multiple implications: The procedure that generates information/metadata about a digital object can be saved. The procedure can be re-executed to generate the associated information, enabling the verification of the information associated with a digital object. This is essential for establishing trust in the sources that provide the digital objects. If a researcher can re-execute a procedure and obtain the same result, reproducible datadriven research is possible. In a data fabric, the procedures should be executable at both the repository where the digital objects are stored, and the research environment local to the researcher. Procedures should be transportable, enabling either the movement of data to a remote service, or the encapsulation of the service for local execution. 2. Federation mechanisms needed to assemble collaborations that span institutions, data management environments, and continents. If interoperability mechanisms exist across versions of data management technology, a collaboration environment can be created that federates each of the participating environments into a unified system. There are multiple versions of federated systems: Shared name spaces for users, files, and services. A shared name space for users provides a single sign-on environment for use of the federated services. A shared name space for files enables formation of virtual collections that span administrative domains. A shared name space for services enables re-use of procedures across researcher resources. Shared services for manipulating digital objects. A simple approach is to move digital objects to the shared service through a broker, accessing the service through its access protocol. A more sophisticated approach is to encapsulate the service in a virtual machine environment, for movement to the local research resources for execution. Third-party access. It is possible to implement shared services by posting requests to a third party, such as a message queue, and eliminate direct communication between the federated system components. The posted message can request the application of a service, which is processed by the remote system independently of the original request. Both of these aspects imply (and need) virtualization: that is the hiding of complexity from the end-user. Here the use of Virtual machines in a CLOUD or GRID environment is required to manage dynamic resource allocation, scalability, distributed parallelism, energy efficiency and other aspects. Most importantly, it is necessary to work at the appropriate level of abstraction in order to allow the computing environment/middleware to behave optimally. Too low or prescriptive a level constrains the environment, too high or abstract a level does not indicate clearly the requirement of the user. Recent work from an Expert Group in Europe has come up with Triple-I Computing as a concept (InformationIntention-Incentive model proposed by [Schubert and Jeffery, 2014]1) and already research projects are addressing the challenges therein. One of these research directions (named BigMESH) is exploring mathematical signatures of all the components in such an environment within a framework of deploying optimally non-Turing / von Neumann architectures (i.e. distributed, parallel, non-sequential, 1 http://ec.europa.eu/digital-agenda/en/news/complete-computing-toward-information-incentive-and-intention communication not CPU intensive applications) over existing von-Neumann provision. For all these reasons virtualization, like interoperability, is an important topic for DF discussion. Analysis and Conclusions: We have made a useful start but the DF vision needs to be expanded but also focused. We need to consider framing DF and its services broadly as data use and applications taking into account the available context or environment. Good data management practices and services are necessary and support this, but are not sufficient to handle interoperability. Improved metadata for data in context with enhanced semantics are one aspect to consider for enhanced interoperability. Another aspect to consider is the emergence of a mathematical foundation for federation of data management systems (e.g. work by Hao Xu). In both the BigMESH and DataNet Federation Consortium projects mathematical signatures are being explored. A signature of a data management system defines the types of entities and the operations that are supported. The signature can be expressed as an algebra that defines operations on entities. Interoperability between data management systems can then be defined in terms of operations on the algebras. Entity types can be converted for interaction between the repositories, and equivalent operations can be mapped. What is interesting, is that assertions about operations within a data management system can also be mapped to assertions within other data management systems. The mathematical foundation defines the minimal properties needed for federation between systems. The DF IG can provide an integrated forum for defining what needs to change to enable Interoperability – a hard but tractable problem and something for DF to keep its eye on.