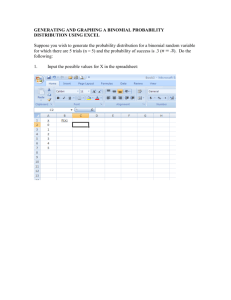
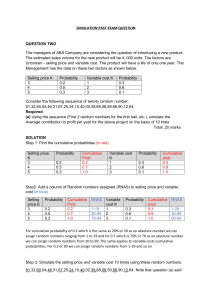
Normal Distributions: The Standard Normal
advertisement

Normal Distributions: The Standard Normal
Perhaps the most important continuous random variable is the normal random
variate which is said to have a normal distribution. The reason for this importance will
become clear when we discuss the Central Limit Theorem. The normal random variable
has the following characteristics.
The density function is given by
1 x
2
1
f ( x)
e 2
2
x
which is valid for -∞ < µ < ∞, and σ > 0. What is e? What is π?
The density function is bell-shaped. If, for example, you choose µ = 0 and σ = 1, then
the density function reduces to
1
f ( x)
2
e
1 2
x
2
(0.3989)e
x2
2
x
x
Thus you can use EXCEL to easily graph this function as shown below.
-3
-2
-1
0
1
2
3
This distribution is symmetric about µ.
The two parameters, µ and σ, which describe this distribution have very nice
interpretations. It turns out that for a random variable X distributed as the density
function defined in the first bullet,
E[X] = µ and Var(X) = σ2.
As a result, a normal random variable has a distribution
which is entirely specified by µ and σ; that is, by its mean
and variance (or standard deviation).
How do we compute probabilities from f(x)?
In this case, f(x) cannot be integrated by standard analytic methods. Instead, tables of
areas have been created using computational procedures for numerical integration.
The table we have available to us provides the area under f(x) to the left of any value you
look up, where µ = 0 and σ = 1. This is the cumulative area. For example, if we want to
know the area below f(x) to the left of 0.83, look down the left column until you find .8,
and across the top row until you find .03. At the intersection of the row and column you
should find the number .7967 as shown below.
This number is the area we are interested in. If we call our normal random variable (µ =
0 and σ = 1) Z, then we can make the statement
P{Z < 0.83} = 0.7967
What is P{ Z > 0.83}?
P{Z < -0.83}?
P{Z > -0.83}?
Normal random variables with µ = 0 and σ = 1 are called standard normals. We
will use Z to represent a standard normal.
Compute the following probabilities. You will find that it is helpful to make a diagram.
(a) P{0 < Z < 1.54} =
(b) P{Z > 0.65} =
(c) P{Z > -0.65} =
(d) P{-1.96 < Z < 1.96} =
(e) P{Z < 2.33} =
(f) P{-2.58 < Z < 2.58) =
(g) P{-3.10 < Z < 1.25} =
(h) P{1.47 < Z < 3.44} =
Next let’s find the value of c which makes the following statements true.
(a) P{Z < c} = .0055
(b) P{-2.67 < Z < c} = .9718
(c) P{Z > c} = .0384
(d) P{-c < Z < c} = .8132
The value zA is the unique value that makes the following probability statement true:
P{Z > zA} = A.
How can we interpret zA?
Determine the following values:
z.01 =
z.05 =
z.10 =
Using EXCEL to compute Standard Normal probabilities
Norm.s.dist(c) returns the area (probability) to the left of the value c.
Norm.s.dist(c) = P{Z < c}
Once again, the key is to draw a diagram until you are familiar with how EXCEL and
our table works.
Norm.s.inv(prob) takes an argument of a cumulative probability and returns the value
c on the normal distribution corresponding to that cumulative probability.
P{Z < Norm.s.inv(prob)} = prob
How can we get z.01? z.05?