Chapter 10 Re-expressing Data: Get it Straight! Introduction All
advertisement

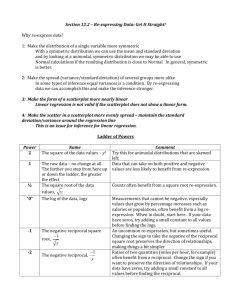
Chapter 10 Re-expressing Data: Get it Straight! Introduction All quantitative data come to us measured in some way, with units specified. But maybe those units aren’t the best choice. Why bother changing units?...because some expressions of the data may be easier to think about. And some may be much easier to analyze with statistical methods. Straight to the Point We cannot use a linear model unless the relationship between the two variables is linear. Often re-expression can save the day, straightening bent relationships so that we can fit and use a simple linear model. Some ways to re-express data are with logarithms, reciprocals, square roots, squaring, etc. Re-expressions can be seen in everyday life—everybody does it. The relationship between fuel efficiency (in miles per gallon) and weight (in pounds) for late model cars looks fairly linear at first: Discuss what you see here in this scatterplot: A look at the residuals plot shows a problem: The original scatterplot shows a negative direction, roughly linear shape, and strong relationship. There do not seem to be any outliers or unusual features. However, there is a definite bend there in the residuals. Let’s just give up… No, wait! All is not lost!! We can re-express fuel efficiency as gallons per hundred miles (a reciprocal) and eliminate the bend in the original scatterplot: The bend in the relationship between Fuel Efficiency and Weight is the kind of failure to satisfy the conditions for an analysis that we can repair by re- expressing the data. This scatterplot is more nearly linear, but the reexpression changes the direction of the relationship. The direction of the association is positive now because we are measuring gas consumption and heavier cars consume more gas per mile. This new model makes better predictions than the previous one! A look at the residuals plot for the new model seems more reasonable: Gallons per hundred miles – what an absurd way to measure fuel efficiency!! Who would ever do it that way?! Answer: everyone except US drivers… Most of the world says “I’ve got to go 100 km, how much gas do I need?” But Americans say, “I’ve got 10 gallons in the tank, how far can I drive?” (we’ll revisit this example in a little bit) Re-expressions think about the data differently, but don’t change what they mean Goals of Re-expression Goal 1: Make the distribution of a variable (as seen in its histogram, for example) more symmetric. Goal 2: Make the spread of several groups (as seen in side-by-side boxplots) more alike, even if their centers differ. Goal 3: Make the form of a scatterplot more nearly linear (because linear scatterplots are easier to model!) Goal 4: Make the scatter in a scatterplot spread out evenly rather than thickening at one end. This can be seen in the two scatterplots we just saw with Goal 3: Practice Exercises Page 239 #1 – 4 Practice Answers Homework Revisiting some things you learned in Algebra 2… Page 239 #5, 6, 7 The Ladder of Powers There is a family of simple re-expressions that move data toward our goals in a consistent way. This collection of re-expressions is called the Ladder of Powers. The Ladder of Powers orders the effects that the re-expressions have on data. Where to start? You may be wondering what to do to the data to reexpress it…It turns out that certain kinds of data are more likely to be helped by particular re-expressions. Power Name Comment 2 Square of data values Try with unimodal distributions that are skewed to the left. 1 Raw data Data with positive and negative values and no bounds are less likely to benefit from re-expression. ½ Square root of data values Counts often benefit from a square root re-expression “0” We’ll use logarithms here Measurements that cannot be negative often benefit from a log re-expression. Reciprocal square root An uncommon re-expression, but sometimes useful. The reciprocal of the data Ratios of two quantities (e.g., mph) often benefit from a reciprocal. –1/2 –1 Just Checking 1. You want to model the relationship between the number of birds counted at a nesting site and the temperature (in degrees Celsius). The scatterplot of counts vs. temperature shows an upwardly curving pattern, with more birds spotted at higher temperatures. What transformation (if any) of the bird counts might you start with? 2. You want to model the relationship between prices for various items in Paris and in Hong Kong. The scatterplot of Hong Kong prices vs. Parisian prices shows a generally straight pattern with a small amount of scatter. What transformation (if any) of the Hong Kong prices might you start with? 3. You want to model the population growth of the US over the past 200 years. The scatterplot shows a strongly upwardly curved pattern. What transformation (if any) of the population might you start with? Example: Cars 1991 Fuel efficiency (mpg) vs. Weight for 38 cars as reported by Consumer Reports Weight Fuel Eff. Weight Fuel Eff. Weight Fuel Eff. 1875 32 2600 27 3100 15 1875 35 2620 22 3375 14 1925 31 2625 26 3375 18 1925 34 2625 28 3355 21 1940 33 2620 34 3500 18 2200 37 2700 28 3575 17 2225 29 2700 26 3700 16 2230 30 2725 27 3800 15 2240 30.5 2800 22 3790 16 2245 34 2825 20 3850 15 2250 31 2825 23 3850 16 2255 27 2850 22 3900 13 3025 21 4000 14 Write the equation for this data Make a scatterplot of the data using your calculator. Homework Page 240 #8, 9, 11, 12 Step-by-Step Example Standard fishing line comes in a range of strengths, usually expressed as “test pounds.” Five-pound test lines, for example, can be expected to withstand a pull of up to five pounds without breaking. The convention in selling fishing line is that the price of a spool doesn’t vary with strength. Higher test pound line is thicker, though, so spools of fishing line hold about the same amount of material. Let’s look at Length and Strength of spools of fishing line manufactured by the same company and sold for the same price at one store. Question How are the Length on the spool and the Strength related? And what re-expression will straighten the relationship? THINK I want to fit a linear model for the length and strength of fishing line. I have the length and “pound test” strength of fishing line sold by a single vendor at a particular store. Let Length = length in yards of fishing line on the spool Strength = the test strength in pounds 3500 3000 2500 2000 1500 1000 500 0 0 100 200 300 400 The plot shows a negative direction and an association that has little scatter but is not straight. SHOW Let’s try a re-expression of the data to make it more nearly linear. Below is a scatterplot of the square root of Length against the strength: Strength vs Sqrt(Length) of Fishing Line 60 sqrt(length) 50 40 30 20 10 0 0 50 100 150 200 Strength 250 300 The plot is less bent, but still not straight. Let’s try the logarithm of Length against Strength: Strength vs Log(Length) in Fishing Line LOG(LENGTH) 4 3 2 1 0 0 50 100 150 200 STRENGTH 250 300 350 350 This is much better, but still not straight, so let’s take another step up the ladder to the reciprocal 0 Strength vs -1/Length for Fishing Line 0 50 100 150 200 250 300 350 -0.002 -1/Length -0.004 -0.006 -0.008 -0.01 -0.012 Strength Maybe now I moved too far along the ladder. A half-step back is the -½ power (the negative reciprocal square root) (we use negative to preserve the direction of the relationship) Strength vs -1/Sqrt(Length) of Fishing Line 0 0 50 100 150 200 -1/sqrt(Length) -0.02 -0.04 -0.06 -0.08 -0.1 -0.12 Strength 250 300 350 TELL It’s hard to choose between the last two alternatives. Either of the last two choices is good enough. What should we choose? I’m going to go with the negative reciprocal of the length. Now that the re-expressed data satisfies the straight enough condition, we can fit a linear model by least squares. Using a calculator, I found: -1 = -0.000343- 0.0000316(Strength) Length We can use this model to predict the length of a spool, say, 35-pound test line: -1 = -0.000343- 0.0000316(35) Length = -0.001449 We could leave the result in these units, but here we want to transform the predicted value back into yards. Length = -1/-0.001449 = 690 yards Example Plan B: Attack of the Logarithms When none of the data values is zero or negative, logarithms can be a helpful ally in the search for a useful model. Try taking the logs of both the x- and y-variable. Then re-express the data using some combination of x or log(x) vs. y or log(y). TI Tips Let’s revisit the Arizona State tuition data. Recall that when we tried to fit a linear model to the yearly tuition costs, the residuals plot showed a distinct curve. This curved pattern indicates that data re-expression may be in order. If you have no clue which re-expression to try, the Ladder of Powers may help. We just used that approach in the fishing line example. Here, though, we can paly a hunch. It is reasonable to suspect that tuition increases at a relatively consistent percentage year by year. This suggests that using the logarithm of tuition may help. Tell the calculator to find the logs of the tuitions, and store them as a new list. Perform the regression for the logarithm of tuition vs. year Do you know what the model’s equation is? Remember, it involves a logarithm! Can you estimate the tuition for 2001? Make sure you think!!! Example Multiple Benefits We often choose a re-expression for one reason and then discover that it has helped other aspects of an analysis. For example, a re-expression that makes a histogram more symmetric might also straighten a scatterplot or stabilize variance. Why Not Just Use a Curve? If there’s a curve in the scatterplot, why not just fit a curve to the data? The mathematics and calculations for “curves of best fit” are considerably more difficult than “lines of best fit.” Besides, straight lines are easy to understand. We know how to think about the slope and the y-intercept. What Can Go Wrong? Don’t expect your model to be perfect. Don’t stray too far from the ladder. Don’t choose a model based on R2 alone: Beware of multiple modes. Re-expression cannot pull separate modes together. Watch out for scatterplots that turn around. Re-expression can straighten many bent relationships, but not those that go up then down, or down then up. Watch out for negative data values. It’s impossible to re-express negative values by any power that is not a whole number on the Ladder of Powers or to re-express values that are zero for negative powers. Watch for data far from 1. Data values that are all very far from 1 may not be much affected by re-expression unless the range is very large. If all the data values are large (e.g., years), consider subtracting a constant to bring them back near 1. What have we learned? When the conditions for regression are not met, a simple reexpression of the data may help. A re-expression may make the: Distribution of a variable more symmetric. Spread across different groups more similar. Form of a scatterplot straighter. Scatter around the line in a scatterplot more consistent. Taking logs is often a good, simple starting point. To search further, the Ladder of Powers or the log-log approach can help us find a good re-expression. Our models won’t be perfect, but re-expression can lead us to a useful model. Homework Page 241 #15, 17, 27 and Alligators Problem (above)