FAQ_assignment2a.doc
advertisement

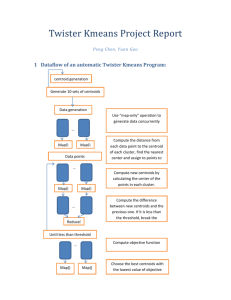
FAQ of Assignment2 ver 1.5a Note the assignment is updated: the box inside part1, question 1.1. Originally: Use Binary K-means method to find the two centroids. Assume you use all available samples in building the centroids at all stages of calculations. Now modified as Use Binary K-means method to find the four centroids. Assume you use all available samples in building the centroids at all stages of calculations. Question1. I would like to ask about the AdaBoost programming question of assignment 2. It is stated that, "Your program should output the text of the parameters required on screen." I assume here it means the parameters of the resulted strong classifier. But then, what parameters can be printed about a strong classifier in text? I tried to reference the examples in lecture notes, but when it comes to the strong classifier, it is all graphs. I can only think of printing out every weak classifiers' parameters and their confidence values inside the strong classifier. Answer1 : what I mean is the strong classifier in slide 17 of ch7 , ie. αt and ht(x) for each t.An example is in slide 50 of ch7. http://www.cse.cuhk.edu.hk/~khwong/www2/cmsc5707/5707_07_adaboost.ppt T H(x) sign αt ht (x) t 1 Question2 Another rather strange point I have found in my program. When I look into the result strong classifier generated by my program, I found there's some duplicated weak identifiers in different iterations, and with different confidence values e.g. h2 = dimension:vertical, threshold:-7.5, direction:-1, confidence:0.77022 h5 = dimension:vertical, threshold:-7.5, direction:-1, confidence:0.43768 Despite this, when I apply the strong identifier back to the test dataset, it does work perfectly. I'd like to know if it is normal for AdaBoost to re-pick the same weak classifier at later iterations. Answer2: The answer is yes. Weak classifiers can be reused. Written: Q1: Am I supposed to write down centroids from K-means clustering and Binary split Kmeans? I am not sure the square blanket in Q1 is hint or another question :(. Answer: it is a typo. "Use Binary K-means method to find the two centroids. Assume you use all available samples in building the centroids at all stages of calculations." It should be "Use Binary K-means method to find the four centroids. Assume you use all available samples in building the centroids at all stages of calculations." I will double check and announce it later. What is the iteration of 2 means in Q1? Does it means we need to update centroids twice? (one after splitting and one after grouping data points)? answer: It means at each split (say for 2 centroids required at this stage) , you update the centroids using all data, so it may take several iterations to regroup data so that two centroids are stable. For a simple question like this , 1 or 2 times are enough. After the stage for 2 centroids, you need to split the data into 4 groups and you do regrouping to find the 4 centroids, again using 2 iterations. For a bigger problem, you may need to update more than 2 times at each stage, ie. the stages are : 2 centroids stage, 4 centroids stage, 8 centroids stage etc. question: >>If above guess is true, what is the best value for doing so in term of efficiency? Since centroids may or not may changed during “iteration”, how can I ensure this is the best value? answer: Usually your measure the residual error (the data classified to that group is closer to the group centroid than any other centroids) , after many iterations, there should be no error in classification at that stage. Then you stop. As I said, 2 is enough for this small problem. In fact for a larger problem , so keep iterations for each stage to be a finite number may create small error, but it can be tolerated for better efficiency. Q3: Question: Does 24×24 detection windows means 24 x 24 pixel windows? Answer:yes How can I take W, H into considerations in this question? Or in other word, How the pixels affect # of features founded in detection window? answer: If the feature is of a certain size in pixel, calculate the number of different features that can be found in the 24x24 pixel windows. You should study examples in the lecture note, than you should be able to solve that problem. Q4: Question: For the programming part, is it a must to write MATLAB program? Is it ok if I use octave or even other programming language? Answer: all other languages are allowed. Q5: Question: I am confused about some statements appeared in question 2 and question 3 in Written Assignments in assginment 2 of CMSC5707, they are saying that : "You may find the answer by manual calculation, solve it by programming is optimal". I feel that you want us to solve it by programming and actually I also want to solve it by programming. But whether you mean that we can post our code direclty in word file and get our results? But it is WRITTEN part instead of PROGRAMMING part So my question is: if we solve it by programming, whether you mean that we can write our code directly in the word file to solve it even it is in WRITTEN part? Answer: If you solve it by manually write the steps clearly. If you find the answer it by programming (any programming language is acceptable), you need to give us the source code of that language.