Report - salsahpc
advertisement

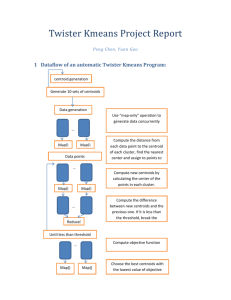
Twister Kmeans - Project Report Prajakta Purohit Swathi Gurram Project Description Run Kmeans implementation on Twister and write a method that helps in determining if the centroid are precise or nearest centroids. We use Twister to run Kmeans because it is more suitable for iterative map reduce. Implementation We had to implement code to run Kmeans map reduce for ten different set of initial centroids. For each set of centroid, we execute the code ten times in order to get an average execution time. We took reading of the Kmeans algorithm this way by without validating the results. We then implanted the validation function using a separate Map, Reduce and Combiner classes. This new validate map task calculates sum of distances for each point to each centroid. The centroids with the smallest sum is the closest to actual centroids. These are files that we had changed: KMeansDataGen.java Made changes to the main method in order to generate 10 different initial centroid sets KMeansClustering.java Added validate method that configures the Validate job for each data set and drives the validation of the centroid set Changed the driveMapReduce method in order to run the kmeans map-reduce for all the 10 input files. For each input file the kmeans algorithm executes 10 times to calculate the average execution time. KMeansValidateMapTask.java The map method calculates the sum of distances for each point of the partition file that the mapper recieves to the final centroid that it belongs to. The ouput of each mapper task is sent to the reducer by the framework. KMeansValidateReduceTask.java The reducer receives outputs from all the mappers. Each mapper receives the sum of distances of final centroids from the points belonging to its own partition. These intermediate sums are collected by the reducer and a final sum is calculated. KMeansValidateCombiner.java Groups the results received from the Reduce tasks and returns it. Data Flow For each set of initial centroids Iterate This 10 times do driveMapReduce to calculate new centroids If the error between the previous and new centroids is greater than a threshold Complete 10 iterations of the set Get final set of centroids Validate the final set of centroids and calculate the best set of centroids Repeat process for all ten input files Print the best set of centroids Comparison between original Kmeans and our Kmeans with Validation For each initial set of centroids: Original Kmeans : runs the Kmeans map-reduce 10 times Our Kmeans : run Kmeans map-reduce 10 times and also invoke the validate map-reduce which check if this is the best set of centroids. Execution time for different input sets 1 0.18 0.16 0.14 0.12 0.1 Original Kmeans 0.08 Kmeans With Validation 0.06 0.04 0.02 0 1 2 3 4 5 6 7 8 9 10 The sequential complexity per iteration is O(NK) for K centers and N points. What is time complexity of each Map Task? Assuming there are m map tasks the complexity of each map task will be O(nk/m). Since the number ‘m’ is constant and that there are only few mappers the complexity will be O(nk). What is time complexity of Reduce task? The time complexity of the reducer is also O(nk) as it calculates the new centroid after it receives input from mappers. What speed up would you expect when N is large for Twister version? In case of sequential kmeans, for each iteration it takes O(nk) whereas using map reduce it takes O(nk/m) where m is the number of mappers. Ideally the speed up obtained by using the map-reduce model is m. In your best solution with lowest objective function value, could you explain or describe the reason? The lowest objective function value is obtained by the points that are closest to the actual centroids of the file. This is being calculated by summing up the distances of every point in the cluster to all the centroids. The centroid set with nearest sum is the closest set.