lihui_xc7_proj2
advertisement

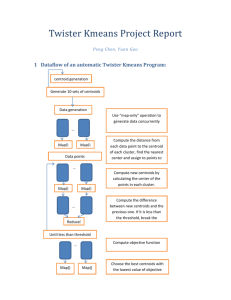
B649 Project 2 Report Hui Li Xiaoyang Chen a. The sequential complexity per iteration is O(NK) for K centers and N points. What is time complexity of each Map Task? Assume there are K centroids, N data points, and L element in each vector. The sequential complexity per iteration is O(NKL+NL+KL), Assume there are M map tasks, complexity of each map task is O((NKL+NL)/M)) b. What is time complexity of Reduce task? The reduce will calculate K/R center coordinates based on temporary center coordinates from L map tasks, where R is the total number of Reduce tasks. So the time complexity of each Reduce Task is O(LK/R) c. What speed up would you expect when N is large for Twister version? Sp = Tseq/Tparallel = O(NKL+NL+KL)/(O(NKL+NL)/M+O(KL/R)) = M d. In your best solution with lowest objective function value, could you explain or describe the reason? 1. Convergence We firstly tested in original Error function: As the Error measurement of the getError() in class KmeansClustering only calculate the error between current centroids and the previous centroids, the result of the whole function could only shows the speed of convergence. So the lowest objective function value is only the best convergence solution. We modified the program and let the program only runs ten times to measure the convergence. In addition, we try use methods in the following paper to get some optimized centroid based on the given generated random initial centroids. However, as time limited, we just finish program of the first step, down sampling in this paper: [1] Refining initial points for k-means clustering, Paul S. Bradley, Usama M. Fayyad, 1998 The following diagram is the distribution of the initial centroid points in our 10 tests, and the final centroid points. We can see the initial centroid point pair with the best convergence result, test No 4 and No 6 (No 5 in zero based display result), has similar distance from each other as the final centroid pair, and the line between their two points are near perpendicular to the line between the two final centroid points, which is generated from initial centroid point of test No 6. The initial centroid point pair with the worst convergence result is far away from each other. The pair of points with mark ‘*’ is the final best centroid points, ‘x’ is the worst cases, ‘o’ is the best cases From the following diagram, the newly generated initial centroids, through the method we use, have better overall convergence than their corresponding original randomly generated centroids. Blue line is the Total Error of the original randomly generated initial centroids Green line is the Total Error of the newly generated initial centroids 2. Object Function Then we modify the map and reduce function, add a signal so that we will run another round of map reduce in different procedure to calculation the average square of distant, which we think is the comparable most efficient solution, and test in newly generated point data. Compare of the error result, original in green, refined in blue According to the comparison diagram above, we can see that the refined start point doesn’t improve the final error result, but only improve the converge performance. Point distribution: ‘*’ points are best final centroid generated from initial point pair No.6. ‘x’ points are initial point pairs, generating the best results From the picture, we cannot tell any special characteristic of the initial point pairs, which generate the best results.