Combining techniques for software quality classification
advertisement

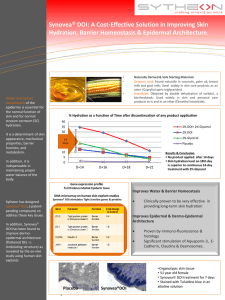
METHOD DESCRIPTION Combining techniques for software quality classification: An integrated decision network approach Nan-Hsing Chiu RUBEN DE JONG 3812065 GROUP 2 Introduction Organizations in the software industry rely heavily on the quality of the software they produce. It is, after all, the quality of their product. As a logical consequence, ensuring the quality of the software is a process which receives high priority at all stages of development. Software quality classification is a methodology which seeks to predict the software quality on a modular basis. Specifically, it should accurately point out which module is likely to contain faults, i.e. the module is fault-proneness (fp); or not likely to contain faults, i.e. the module is not fault-proneness (nfp). This allows focus on the fp modules. There has been a history of software quality classification techniques. Using a single software quality classification model is risky, since it can lead to suboptimal results (Macdonell & Shepperd, 2003). On the other hand, using multiple of these models will give a more accurate result. In fact, the most optimal implementations vary between these models (Jeffery, Ruhe, & Wieczorek, 2001). However, there is no universal model which applies to all software. To create a universal model, the existing models have to be combined. This is done in an integrated decision network (IDN). The optimal combination of models is done through particle swarm optimization (PSO). This universal model is based on Artificial Neural Networks (ANN) (Thwin & Quah, 2005), as a result, the model is shaped like a neural network: - - Input layer: the input layer consists of input nodes which represents the feature values of the module. Model layer: the model layer consists of model nodes which are the software quality classification models to be used with the feature values. These models each provide 2 results; a normal result node, being 1 if fp and 0 if nfp; and an inverse result node, which gives 0 if fp and 1 if nfp. Each of these results are then combined into a single result using a weight, this weight differs per model. More specifically, the results are multiplied by their individual weights and then summed up. As a result, some models will have a stronger contribution than other models. Output layer: The combined result is then compared to a certain threshold. If the result exceeds the threshold, the software module is deemed to be fp. Otherwise it is nfp. Getting the optimal combination of models through PSO is achieved by applying PSO to the weights of the results in the model layer. The PSO algorithm will search for the optimal weights by comparing the model’s result to the actual fault data of the software module. If the result is insufficiently accurate, the algorithm will keep searching for better weights. The author, Nan-hsing Chiu, is an assistant professor and Chairman of Department of Information Management at Ching Yun University in Zhongli City, Taiwan. His fields of specialty are Artificial Intelligence, Software Engineering and Engineering. Example Feature value 1 1 fp CART result CART CART inverted result 0 Weight W1 threshold = 1.2 Weight W2 Feature value 2 0 nfp Output Weight W3 C4.5 result Weight W4 C4.5 C4.5 inverted result Feature value 3 1 Figure 1 This is an example of using IDN on a software module (figure 1). The example is fairly restricted, as there are more software quality classification models than just CART and C4.5. Here, the three feature values of the software module are used as the input nodes. They are each fed to the software quality classification models, CART and C4.5. The models, in turn, give the two results, the normal result and the inverted result. At this point the weights of each result node have to be calculated through PSO. Generally speaking, PSO will calculate the accuracy of each result (classification). A general demonstration of PSO follows: We have 4 weights: W1, W2, W3 and W4. Let’s say they are initialized randomly at W1: 0.40, W2: 0.60, W3: 0.15 and W4: 0.50. Now the first evaluation does not result in a good enough fitness (unsurprisingly). After a few iterations of PSO, the weights are accepted by the evaluation function. This final result is W1: 0.85, W2: 0.10, W3: 0.70 and W4: 0.15. 0.85*1+0.10*0+0.70*0+0.15*1 = 1.0. This is lower than the threshold of 1.2, meaning that the software module is deemed to be nfp by IDN. The final result is depicted in figure 2. Feature value 1 1 fp CART result CART CART inverted result 0 Weight 0.85 threshold = 1.2 Weight 0.10 Feature value 2 0 nfp Output: nfp Weight 0.70 C4.5 result Weight 0.15 C4.5 Feature value 3 Figure 2 C4.5 inverted result 1 Related literature There are many software quality classification models that have been developed over the years. Most of these are used in the IDN model. There is the Classification and Regression Trees (CART) model (Khoshgoftaar, Allen, Jones, & Hudepohl, 2000), the SPRINT model (Khoshgoftaar & Seliya, 2002), the C4.5 Decision Trees model (Khoshgoftaar & Seliya, 2004) and the Support vector machines (SVM) model (Xing, Guo, & Lyu, 2005). Most of these models use the fp/nfp results (Chen & Huang, 2009). Another interesting model which is more relative to IDN is the Artificial Neural Networks (ANN) model (Thwin & Quah, 2005), which uses Neural Networks to predict software quality, and was more successful prediction-wise than other network models. This model forms a basis for IDN, as can be noticed in the structure of IDN. Using multiple models as a single model seems like an optimal model, as it has been pointed out that varying between multiple models gives the best results (Jeffery et al., 2001). Moreover, relying on fixed models has been shown to pose a risk (Macdonell & Shepperd, 2003). Combining the models is a more difficult problem, however. Early attempts at combining software quality models did not take everything into account (Schapire, 1999). Combination has been successful with decision tree classifiers, which had a significantly better performance rating than other models (Bouktif, Sahraoui, & Kégl, 2002). The introduction of the evolutionary searching technique PSO (Kennedy & Eberhart, 1995) allows solving certain complex problems. PSO has certain advantages over other genetic algorithms, namely that mutation and crossover operators are not required, allowing it to have a better performance than other genetic algorithms (Wang, Yang, Teng, Xia, & Jensen, 2007). Moreover, experiments involving PSO resulted in finding optimal solutions quickly and with a high probability that the solution found is in fact correct (Nanni & Lumini, 2009). PSO has also been used by the author before in software quality classification, where he proposed a model based on weights of grey relational classifiers (Chiu, 2009). In the paper, PSO is used to explore these grey relational classifier weights. References Bouktif, S., Sahraoui, H. A., & Kégl, B. (2002). Combining Software Quality Predictive Models: An Evolutionary Approach. Proceedings of the International Conference on Software Maintenance - ICSM, Montréal, Canada, 385-392. doi:10.1109/ICSM.2002.1167795 Chen, L.-w., & Huang, S.-j. (2009). Accuracy and efficiency comparisons of single- and multi-cycled software classification models. Information & Software Technology - INFSOF, 51(1), 173181. doi:10.1016/j.infsof.2008.03.004 Chiu, N.-h. (2009). An early software-quality classification based on improved grey relational classifier . Expert Systems With Applications - ESWA, 36(7), 10727-10734. doi:10.1016/j.eswa.2009.02.064 Jeffery, R., Ruhe, M., & Wieczorek, I. (2001). Using Public Domain Metrics To Estimate Software Development Effort. Proceedings of the IEEE International Software Metrics Symposium METRICS, London, England, 16-27. doi:10.1109/METRIC.2001.915512 Kennedy, J. N., & Eberhart, R. C. (1995). Particle swarm optimization. Proceedings of the International Symposium on Neural Networks - ISNN, Dalian, China. doi:10.1109/ICNN.1995.488968 Khoshgoftaar, T. M., & Seliya, N. (2002). Software Quality Classification Modeling Using The SPRINT Decision Tree Algorithm. IEEE Transactions on Applications and Industry, 365-374. doi:10.1109/TAI.2002.1180826 Khoshgoftaar, T. M., & Seliya, N. (2004). Comparative Assessment of Software Quality Classification Techniques: An Empirical Case Study. Empirical Software Engineering - ESE, 9(4), 229-257. doi:10.1023/B:EMSE.0000027781.18360.9b Khoshgoftaar, T. M., Allen, E. B., Jones, W. D., & Hudepohl, J. P. (2000). Classification-tree models of software-quality over multiple releases. IEEE Transactions on Reliability - TR, 49(1), 4-11. doi:10.1109/24.855532 Macdonell, S. G., & Shepperd, M. J. (2003). Combining techniques to optimize effort predictions in software project management. Journal of Systems and Software - JSS, 66(2), 91-98. doi:10.1016/S0164-1212(02)00067-5 Nanni, L., & Lumini, A. (2009). Particle swarm optimization for prototype reduction. Neurocomputing - IJON, 62(4-6), 1092-1097. doi:10.1016/j.neucom.2008.03.008 Schapire, R. E. (1999). Theoretical Views of Boosting. Proceedings of the European Conference on Computational Learning Theory - EuroCOLT, Nordkirchen, Germany, 1-10. doi:10.1007/3540-49097-3_1 Thwin, M. M., & Quah, T.-s. (2005). Application of neural networks for software quality prediction using object-oriented metrics. Journal of Systems and Software - JSS, 76(2), 147-156. doi:10.1016/j.jss.2004.05.001 Wang, X., Yang, J., Teng, X., Xia, W., & Jensen, R. (2007). Feature selection based on rough sets and particle swarm optimization. Pattern Recognition Letters - PRL, 28(4), 459-471. doi:10.1016/j.patrec.2006.09.003 Xing, F., Guo, P., & Lyu, M. R. (2005). A Novel Method for Early Software Quality Prediction Based on Support Vector Machine. Proceedings of the International Symposium on Software Reliability Engineering - ISSRE, Chicago, Illinois, USA, 213-222. doi:10.1109/ISSRE.2005.6