Methods for Comparing a Single Numeric Variable across Two
advertisement

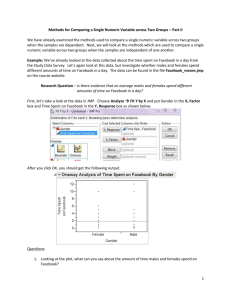
Methods for Comparing a Single Numeric Variable across Two Groups – Part II We have already examined the methods used to compare a single numeric variable across two groups when the samples are dependent. Next, we will look at the methods which are used to compare a single numeric variable across two groups when the samples are independent of one another. Example: We’ve already looked at the data collected about the time spent on Facebook in a day from the Study Data Survey. Let’s again look at this data, but investigate whether males and females spend different amounts of time on Facebook in a day. The data can be found in the file Facebook_means.jmp on the course website. Research Question – Is there evidence that on average males and females spend different amounts of time on Facebook in a day? First, let’s take a look at the data in JMP. Choose Analyze Fit Y by X and put Gender in the X, Factor box and Time Spent on Facebook in the Y, Response box as shown below. After you click OK, you should get the following output. Questions: 1. Looking at the plot, what can you say about the amount of time males and females spend on Facebook? 1 Step 0: Define the research question. Is there evidence that on average males and females spend different amounts of time on Facebook in a day? Step 1: Determine the appropriate null and alternative hypotheses. Since we have two separate groups (population means) to consider, we’ll have to use two population means in our hypotheses. H0: µmales = µfemales Ha: µmales ≠ µfemales Step 2: Check the appropriate assumptions and find the test statistic. We’ll need to check that either __________ samples are sufficiently large or ___________ populations are normally distributed. We will use the methods discussed previous for checking normality. 2. Which condition/assumption has been met for these data? Note: You can get the summary statistics, histograms, and normal quantile plots from JMP by choosing Analyze Distribution and putting time spent on Facebook in the Y, Columns box and gender in the By box as shown below. Females: 2 Males: Since, the sample sizes are sufficiently large and we have found no evidence of unequal variances, we can now carry out what is called the pooled t-test. Looking at the output from the Fit Y by X, click on the red drop-down arrow and choose Means/Anova/Pooled t. You should get the following output. Notes: The test statistic computed looks at the difference in the sample means ( x male x female ), denoted by Difference in the output above. The standard error of the difference, denoted Std Err Diff in the output above, summarizes the variability of the two groups assuming the variability is the same. The t Ratio given in the above output is the test statistic and is computed by dividing Difference by Std Err Diff. 3. Give the value of the test statistic output. How did JMP compute this value? 3 Step 3: Find the p-value. The p-values are given in the same order as in the previous hypothesis testing output we’ve seen. 4. What is the p-value for this test? Step 4: Report the conclusion in context of the research question. Example: Consider the data found in the file BirthWeights.jmp found on the course website. The data summarize the birth weights of babies and whether the mother was an ex-smoker or a non-smoker. Step 0: Define the research question. Is there evidence the average birth weight for babies born to ex-smokers is smaller than the average birth weight of babies born to non-smokers? Step 1: Determine the appropriate null and alternative hypotheses. H0: µex-smokers ≥ µnon-smokers Ha: µex-smokers < µnon-smokers Note: We’ll have to make sure the order of the groups in the hypotheses matches the order in which JMP computed the difference so that we use the appropriate p-value. 4 Step 2: Check the appropriate assumptions and find the test statistic. We’ll need to determine whether the sample sizes are sufficiently large or the data are normally distributed. Ex-smokers: Non-smokers: 5. Which condition, large samples or normal distributions, has been met? 6. What is the test statistic for this test? How did JMP compute it? 5 Step 3: Find the p-value. Note: JMP found the difference in sample means by taking x NonSmoker x ExSmoker . Therefore, the nonsmoker group should be listed as the first group in our hypotheses. Therefore, the test in JMP is testing the following hypotheses: H0: µnon-smokers ≤ µex-smokers Ha: µnon-smokers > µex-smokers Step 4: Report the conclusion in context of the research question. Example: Another question on the Student Data Survey asked about the number of Facebook friends a person has. The data can be found in the file Facebook_Friends.jmp on the course website. Research Question - Is there evidence that females on average have more Facebook friends than males? 6 Example: The data set Walleye.jmp from the course website contains information about the walleye population in two Minnesota Rivers – Minnesota and Mississippi Rivers. It is of interest to compare the mercury levels (HGPPM) of the walleye from the two rivers. Research Question – Is there evidence that there is a difference in the average mercury levels of the fish contained in the Minnesota and Mississippi Rivers? Example: Another question on the survey asked each individual to report how many songs they have on their ipod. You can find the data in the file ipod.jmp on the course website. Research Question – Is there evidence that on average men have more songs on their ipod than women? 7