Methods for Comparing a Single Numeric Variable across Two
advertisement

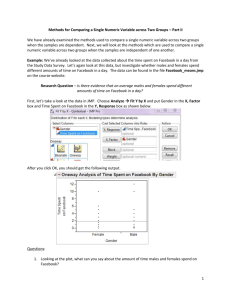
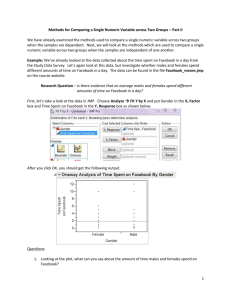
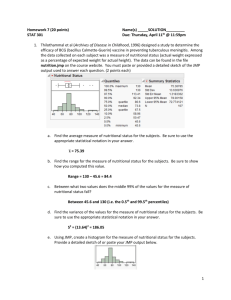
Methods for Comparing a Single Numeric Variable across Two Groups We will now consider methods that allow researchers to make comparisons on a numeric variable between two different groups. The appropriate method used will depend on the fashion in which the data are collected. Dependent (or Paired) Samples – The responses collected from one group/individual are linked or influenced by the responses from the second group/individual. The “pairing” of the observations could occur naturally or the treatments could be assigned in a manner which is conducive to pairing the observations. That is, once one member of the pair has been selected, the researcher automatically knows who/what the second member of the pair is. Dependent (or paired) samples could arise from… One person performing two tasks or getting two treatments and comparing the responses. Two similar individuals could each get a single randomly assigned treatment and the responses compared. Independent Samples – The data are collected independently from each population and the responses from one group should in no way influence the responses of the second group. That is, no natural pairing exists. Example: Determine whether each of the following scenarios is an example of a dependent/paired sample or an independent sample. Explain your reasoning. a. Is autism marked by different brain growth patterns in early life, even before an autistic diagnosis is made? Studies have linked brain size in infants and toddlers to a number of future ailments, including autism. One study looked at the brain sizes of 30 autistic boys and 13 nonautistic boys (control) all who had received an MRI scan as toddlers. The whole-brain volume (in ml) was recorded for each boy. b. Woo and McKenna (British Journal of Dermatology, 2003) investigated the effect of broadband ultraviolet B (UVB) therapy and topical calcipotriol cream used together on area of psoriasis. One of the outcome variables from the study is the Psoriasis Area and Severity Index (PASI). Twenty subjects were measured at baseline and after eight treatments, recording their PASI score each time. 1 c. The effect of supplementation on bone formation was assessed in six healthy adult dogs. For each dog, bone formation was measured for a 12-week period of phosphate supplement as well as for a 12-week control period. It is of interest to see if the phosphate supplement increases bone formation. d. Some archeologists theorize that ancient Egyptians interbred with several different immigrant populations over thousands of years. To see if there is any indication of changes in body structure that might have resulted, researchers measured the breadth (measured in mm) of a random sample of male Egyptian skulls dated from 4000 B.C. and from 200 B.C. (Ancient Races of the Thebaid, 1905). Example: The degree of clinical agreement among different physicians on the presence or absence of generalized lymphadenopathy was assessed in 32 randomly selected participants from a prospective study of male sexual contacts of men with AIDS or an AIDS-related condition. The total number of palpable lymph nodes was assessed by two physicians, and interest lies comparing the two physicians. The data can be found in the file LymphNodes.jmp on the course website. Research Question – Is there evidence that these two physicians disagree in their assessments of generalized lymphadenopathy? A portion of the data is given below. Question: 1. Is this an example of an independent or a dependent sample? Explain. 2 Comment: For these data, the first observation listed under Doctor A is related to the first observation listed under Doctor B since the two measurements were made on the same person. The ___________________ has been randomly selected; therefore, once we have chosen Patient 1 to be assessed by Doctor A, the ___________ patient will also be assessed by Doctor B, resulting in dependent/paired samples. To answer the research question given above, we’re going to need to work with the ________________ and NOT the actual measurements taken. Question: 2. Why do you think it is more appropriate to work with the differences rather than the actual measurements taken? First, we’ll need to compute the differences in JMP by creating another column. We can accomplish this using the following steps: Create a new column by double-clicking in the heading area next to Doctor B. Next, rename the column Difference. Your JMP file should now look like the one given below. Next, right-click on the Difference heading and choose formula as shown below. 3 Next, in the dialogue box that appears, enter the following into the white space in the center as shown below. Click OK and the difference for each observation should now be shown for each patient. For this hypothesis test, our parameter of interest is the true population average of the differences, which is denoted by µdifference. Our best estimate of this parameter will be the sample mean of the observed differences, denoted x difference. The sample standard deviation of the differences will also be used and is denoted sdifference. Comment: The observed differences represent a single column of data. Therefore, the hypothesis test used will be the same procedure as the hypothesis test for a single mean. Step 0: Define the research question. Is there evidence these two physicians disagree in their assessments of generalized lymphadenopathy? Step 1: Determine the appropriate null and alternative hypotheses. H0: µdifference = 0 Ha: µdifference ≠ 0 4 Step 2: Check the assumptions behind the test and calculate the test statistic. We’ll again need to check whether the sample size (i.e. number of pairs) is sufficiently large or the differences are normally distributed. npairs = 32 ≥ 30 √ Since the sample size is larger enough, we can now calculate the test statistic. We’ll need the following summary statistics from JMP. x difference = ______________ sdifference = ______________ npairs = ______________ µdifference = ______________ t= x difference -μ difference = s difference n pairs Step 3: Find the p-value. Step 4: Report the conclusion in context of the research question. 5 We can also take a look at the 95% confidence interval for the mean difference: Questions: 3. Do the doctors agree in the number of lymph nodes? How do you know based on the confidence interval? 4. Which doctor tends to find more palpable lymph nodes? How do you know? 5. To what degree do the doctors differ? Example: A company manufactures a homeopathic drug it claims can reduce the time it takes to overcome jet lag after long-distance flights. A researcher would like to test their claim and recruits nine people who take frequent trips from San Francisco to London to participate in the study. The researcher randomly assigns a person to the placebo for one of their trips and the drug for the other, in random order. Each participant is then asked how many days it took them to recover from jet lag for each condition. The data can be found in the file flight.jmp on the course website. Question: 6. Explain why this is an example of a dependent sample. Step 0: Define the research question. Is there evidence the homeopathic drug reduces the time it takes a person to recover from jet lag? 6 Step 1: Determine the appropriate null and alternative hypotheses. Step 2: Check the assumptions behind the test and calculate the test statistic. Step 3: Find the p-value. Step 4: Report the conclusion in context of the research question. We can also take a look at the 95% confidence interval for the mean difference: Question: 7. What does the confidence interval say about the effectiveness of the drug compared to the placebo? 7 Next, we will look at the methods which are used to compare a single numeric variable across two groups when the samples are independent of one another. Example: Hoekema et al. (Journal of Oral Rehabilitation, 2003) studied the craniofacial morphology of 26 male patients with obstructive sleep apnea syndrome (OSAS) and 37 healthy male subjects (nonOSAS). One of the variables of interest was the length from the most superoanterior point of the body of the hyoid bone to the Frankfort horizontal (measured in millimeters). The data can be found in the file Hyiod.jmp on the course website. Research Question – Is there evidence of a difference in the average length of the hyoid bone to the Frankfort horizontal for the two groups? First, let’s take a look at the data in JMP. Choose Analyze Fit Y by X and put Group in the X, Factor box and Hyoid Length in the Y, Response box as shown below. After you click OK, you should get the following output. Questions: 1. Looking at the plot, what can you say about the length of the hyoid bone to the Frankfort horizontal for the two groups? 8 Step 0: Define the research question. Is there evidence of a difference in the average length of the hyoid bone to the Frankfort horizontal for the two groups? Step 1: Determine the appropriate null and alternative hypotheses. Since we have two separate groups (population means) to consider, we’ll have to use two population means in our hypotheses. H0: µOSAS = µnon-OSAS Ha: µOSAS ≠ µnon-OSAS Step 2: Check the appropriate assumptions and find the test statistic. We’ll need to check that either __________ samples are sufficiently large or ___________ populations are normally distributed. We will use the methods discussed previously for checking normality. 2. Which condition/assumption has been met for these data? Note: You can get the summary statistics, histograms, and normal quantile plots from JMP by choosing Analyze Distribution and putting time spent on Facebook in the Y, Columns box and gender in the By box as shown below. OSAS: 9 Non-OSAS: Since, it is reasonable to assume the distribution is normal for both populations, we can now carry out what is called the pooled t-test. Looking at the output from the Fit Y by X, click on the red drop-down arrow and choose Means/Anova/Pooled t. You should get the following output. Notes: The test statistic computed looks at the difference in the sample means ( x OSAS x non-OSAS ), denoted by Difference in the output above. The standard error of the difference, denoted Std Err Diff in the output above, summarizes the variability of the two groups assuming the variability is the same. The t Ratio given in the above output is the test statistic and is computed by dividing Difference by Std Err Diff. 3. Give the value of the test statistic output. How did JMP compute this value? 10 Step 3: Find the p-value. The p-values are given in the same order as in the previous hypothesis testing output we’ve seen. 4. What is the p-value for this test? Step 4: Report the conclusion in context of the research question. Example: Consider the data found in the file BirthWeights.jmp found on the course website. The data summarize the birth weights of babies and whether the mother was an ex-smoker or a non-smoker. Step 0: Define the research question. Is there evidence the average birth weight for babies born to ex-smokers is smaller than the average birth weight of babies born to non-smokers? Step 1: Determine the appropriate null and alternative hypotheses. H0: µex-smokers ≥ µnon-smokers Ha: µex-smokers < µnon-smokers Note: We’ll have to make sure the order of the groups in the hypotheses matches the order in which JMP computed the difference so that we use the appropriate p-value. 11 Step 2: Check the appropriate assumptions and find the test statistic. We’ll need to determine whether the sample sizes are sufficiently large or the data are normally distributed. Ex-smokers: Non-smokers: 5. Which condition, large samples or normal distributions, has been met? 6. What is the test statistic for this test? How did JMP compute it? 12 Step 3: Find the p-value. Note: JMP found the difference in sample means by taking x NonSmoker x ExSmoker . Therefore, the nonsmoker group should be listed as the first group in our hypotheses. Therefore, the test in JMP is testing the following hypotheses: H0: µnon-smokers ≤ µex-smokers Ha: µnon-smokers > µex-smokers Step 4: Report the conclusion in context of the research question. Example: Can we conclude that patients with primary hypertension (PH), on average, have higher total cholesterol levels (mg/dl) than normotensive (NT) patients? This was one of the inquiries of interest for Rossi et al (Journal of the American College of Cardiology, 2003). The data can be found on the file PH.jmp on the course website. Research Question – Is there evidence that the average total cholesterol level is higher for PH patients than for NT patients? 13 Example: The data set Walleye.jmp from the course website contains information about the walleye population in two Minnesota Rivers – Minnesota and Mississippi Rivers. It is of interest to compare the mercury levels (HGPPM) of the walleye from the two rivers. Research Question – Is there evidence that there is a difference in the average mercury levels of the fish contained in the Minnesota and Mississippi Rivers? 14