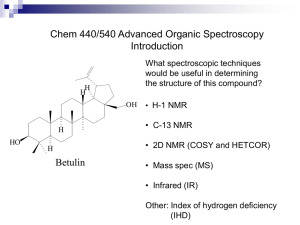
COMBINED METABOLOMIC AND PROTEOMIC ANALYSIS
advertisement

Online Appendix for the following JACC article TITLE: Metabolomic Profile of Human Myocardial Ischemia by Nuclear Magnetic Resonance Spectroscopy of Peripheral Blood Serum: A Translational Study Based on Transient Coronary Occlusion Models AUTHORS: Vicente Bodi, MD, Juan Sanchis, MD, Jose M. Morales, BsC, Vannina G. Marrachelli, PhD, Julio Nunez, MD, Maria J. Forteza, BsC, Fabian Chaustre, BsC, Cristina Gomez, BsC, Luis Mainar, MD, Gema Minana, MD, Eva Rumiz, MD, Oliver Husser, MD, Inmaculada Noguera, PhD, Ana Diaz, PhD, David Moratal, PhD, Arturo Carratala, MD, Xavier Bosch, MD, Angel Llacer, MD, Francisco J. Chorro, MD, Juan R. Viña, MD, PhD, Daniel Monleon, PhD APPENDIX SUPPLEMENTARY MATERIAL Abbreviations and Acronyms NMR = nuclear magnetic resonance PC = principal component PCA = principal component analysis PLS-DA = projection to latent structures for discriminant analysis ppm = parts per million of spectrometer frequency METHODS NMR spectroscopy Total preparation time prior to nuclear magnetic resonance (NMR) detection was less than 15 min. Two L of D2O were added to an aliquot with 20 L of blood serum and placed in a 1 mm high resolution NMR tube. All spectra were recorded in a Bruker Avance DRX 600 spectrometer (Bruker GmbH, Rheinstetten, Germany). Nominal temperature of the sample was kept at 37º C. A single-pulse pre-saturation experiment was acquired in all samples. The chemical shift region including resonances between 0.50 and 4.70 parts per million of spectrometer frequency (ppm) was investigated. The spectra were normalized to total aliphatic spectral area to eliminate differences in metabolite total concentration. The spectra were binned into 0.01 ppm buckets and mean centered for multivariate analysis. Signals belonging to selected metabolites were integrated and quantified using semi-automated in-house MATLAB (The MathWorks Inc. 2006) peak-fitting routines. Multivariate Model Analysis Chemometrics statistical analyses were performed using in-house MATLAB scripts and the PLS Toolbox (Eigenvector Research, Inc.). Principal Component Analysis (PCA) and Projection to Latent Structures for Discriminant Analysis (PLS-DA) were applied to NMR spectra data sets. PCA is able to find low dimensional embeddings of multivariate data, in a way that optimally preserves the structure of the data. PCA technique transforms variables in a data set into a smaller number of new latent variables called principal components (PCs), which are uncorrelated to each other and account for decreasing proportions of the total variance of the original variables. Each new PC is a linear combination of the original variation such that a compact description of the variation within the data set is generated. Observations are assigned scores according to the variation measured by the principal component with those having similar scores clustering together. Where PCA proved inadequate to define clustering, a supervised approach was used. PLS-DA is a supervised extension of PCA used to distinguish two or more classes by searching for variables (X matrix) that are correlated to class membership (Y matrix). In this approach the axes are calculated to maximize class separation and can be used to examine separation that would otherwise be across three or more principal components (1). Validation of the PLS-DA model The PLS-DA model discriminating between controls and patients was cross-validated by the leave-one-out method and externally validated on the new data set obtained on patients with spontaneous chest pain recruited at the Emergency Department. Cross validation is a very useful tool that provides two critical functions in chemometrics. First, cross validation enables an assessment of the optimal complexity of a model. Second, it allows an estimation of the performance of a model when it is applied to unknown data. For a given data set, cross validation involves a series of experiments, hereby called sub- validation experiments, each of which involves the removal of a subset of individuals from a dataset, construction of a model using the remaining objects in the dataset, and subsequent application of the resulting model to the removed objects. Therefore, each sub-validation experiment involves testing a model with objects that were not used to build the model. Typical cross-validation involves more than one sub-validation experiment by selection of different subsets of individuals for model building and model testing. Leave-one-out cross-validation involves the use of a single observation from the original sample as the validation data, and the remaining observations as the training data. This is repeated in a manner that each observation in the sample is used once as the validation data. Leave-one-out is ideally suited for datasets with limited number of samples. Crossvalidation provided a root mean square of 0.3677 and a cross error of 0.0875. Q residual and Hotelling T2 for 95% confidence intervals were 0.541 and 12.11 respectively. The annotated loadings plots of the 3 latent variables of the PLS-DA model are plotted in Figure S2 of this Supplementary Material. Reference 1. Trygg J, Holmes E, Lundstedt T. Chemometrics in metabonomics. J Proteome Res 2007;6:469-79. LOGISTICS REPORT Sample preparation and analysis in an experienced laboratory The application of the model presented in this manuscript to new data is straightforward in a properly set up NMR laboratory. The computer controlling the NMR spectrometer needs to have a valid MATLAB license for samples classification according to our model. The key aspect in the success of our approach is to have a NMR spectrometer ready for serum measurements 24 horus a day. If that is the case, the total time since a serum sample enter the lab until a final classification report is produced may be as short as 15 minutes. Sample preparation for NMR measurements is really simple (as mentioned above, it only includes addition of D2O to the sample). The measurement, including temperature equilibrium and the pulse sequence takes 8 minutes. Finally, once the free induction decay is produced, pre-processing of the spectra, transfer to the MATLAB environment and application of the model may be partially automatized and performed in just 1 to 2 minutes. In our laboratory, the total processing time of an individual sample is around 15 minutes. In addition, large series of samples can be processed by automated robots with the ability to process hundreds of samples in a few hours. Financial aspects for setting up a metabolomics laboratory Although the initial investment required for setting up a NMR laboratory is important, the low cost of the subsequent measurements combined with the high amount of information that each spectrum produces can make the laboratory profitable in a few years. Because of the latest advances in NMR technology, namely, magnet shielding and compact consoles, a NMR laboratory can be established in almost every normal laboratory space. Magnetic disturbance and vibrations in the room should be minimized. A trade off between performance and maintenance costs probably makes a 400 MHz standard bore magnet the most cost-effective solution. Automatic sample changer is essential for high throughput although in the case of Emergency Room applications this may not be required. Although there are just a few NMR spectrometer manufacturers in the world, the price of a fully equipped NMR spectrometer varies between countries even for the same manufacturer and model. A rough estimate of the cost of a standard 400 MHz shielded magnet with a new compact console and a probe for 1H spectroscopy may be around 350k euros. The magnet requires cryogenic filling of the deward. Liquid nitrogen must be filled weekly and liquid helium must be filled approximately every three months. The cost for this cryogenics during 1 year in Spain is 10k euros. Sample solvent-matched NMR tubes cost 2 euros the unit. For an average of 20 samples per day coming from the Emergency Department, we estimate that a cost per sample of 15 euros will allow to cover the costs in just three years. Figure S1 Title. NMR spectra of the experimental model. Caption. Comparison of all overlapped spectra collected in blood serum of swine before (top spectra) and immediately after (bottom spectra) ischemia. Most representative metabolites have been labeled. Abbreviations. UFA = unsaturated fatty acids. Figure S2 Title. Loadings plots of the PLS-DA model for discrimination, based on the NMR spectra of peripheral blood serum, of patients with angioplasty-induced myocardial ischemia from angiography control patients. Caption. The most representative metabolites to discriminate patients with angioplastyinduced myocardial ischemia from angiography control patients have been labeled. Abbreviations. Aceglyco = acetyl groups of glycoproteins. Ala = alanine. CCC = cholinecontaining compounds. Chol = cholesterol. Cre = total creatine. FA = fatty acids. FA (1) = CH3 groups in fatty acids. FA (2) = CH3 groups close to a CO group (CH3-CO-) in fatty acids. Gln = glutamine. Gluc = glucose. Gly = glycine. Glyc = Glycerol. Gsx = glutamate + glutathione. ILV = isoleucine + leucine + valine. LV = latent variable. PEA = phosphoethanolamine. PUFA = polyunsaturated fatty acids. Tau = taurine. TG = triglycerides. UFA = unsaturated fatty acids. Figure S3 Title. Performance of single metabolites and of the PLS-DA model for discrimination of spontaneous acute chest pain patients with and without a final diagnosis of myocardial ischemia. Caption. ROC curves for the discrimination of spontaneous acute chest pain patients with and without a final diagnosis of myocardial ischemia based on the PLS-DA model (F) and on the levels of single metabolites (A to E) showing no spectral overlapping and the most statistically significant differences in the angioplasty balloon-induced myocardial ischemia model (column 7 of Table 2 of the manuscript). A) Triglycerides (AUC 0.74); B) Acetate (AUC 0.65); C) Glutamine (0.67); D) Phosphoethanolamine (AUC 0.73); E) Lactate (0.69); F) PLS-DA model (AUC 0.90). Abbreviations. AUC = area under the receiver operating characteristics curve. PLS-DA = projection to latent structures for discriminant analysis. ROC = receiver operating characteristics. Table S1. Resonance frequency (in ppm) for metabolites detected and quantified by NMR spectroscopy in blood serum of angiography controls and in angioplastyinduced myocardial ischemia patients Metabolite dominant Chemical shift (ppm) in the spectral region Cholesterol 0.70 Triglycerides 0.87 Leucine 0.95 Isoleucine 1.00 Valine 1.02 3-hydroxybutyrate 1.21 Fatty acids (1) 1.27 Alanine (overlapped) 1.48 Fatty acids (2) 1.60 Acetate 1.93 Unsaturated FA 2.00 Glycoproteins (acetyls) 2.04 Fatty acids (3) 2.24 Glutathione 2.32 Glutamate 2.36 Glutamine 2.41 Polyunsaturated FA 2.72 Asparagine 2.95 Albumine lysyl (4) 3.00 Albumine lysyl (5) 3.02 Creatine 3.04 Choline 3.20 Phosphocholine 3.21 Glycerophosphocholine 3.22 Taurine 3.25 Proline 3.37 Glucose 3.48 Glycine 3.54 Glycerol 3.63 Tyrosine+Phenylalanine 3.96 Phosphoethanolamine 4.08 Lactate 4.14 Abbreviations. FA = fatty acids. ppm = parts per million. Table S2. Clinical characteristics of angiography controls and of angioplastyinduced myocardial ischemia patients Angioplasty- Angiography induced ischemia controls (n=20) (n=10) Age (mean ± SD. years) 64 10 66 10 0.4 Male sex (%) 15 (75) 4 (40) 0.1 Diabetes (%) 7 (35) 1 (10) 0.3 Current smoker (%) 5 (25) 2 (20) 1.0 Hypertension (%) 13 (65) 6 (60) 1.0 Hypercholesterolemia (%) 15 (75) 5 (50) 0.3 Previous angioplasty (%) 5 (25) 4 (40) 0.6 Previous surgery (%) 0 (0) 0 (0) 1.0 Previous revascularization (%) 5 (25) 4 (40) 0.6 Previous infarction (%) 9 (45) 4 (40) 1.0 ST-segment depression (%) 4 (20) 2 (20) 1.0 T-wave inversion (%) 3 (15) 0 (0) 0.5 Treatment with beta-blockers (%) 11 (55) 5 (50) 1.0 Treatment with nitrates (%) 11 (55) 5 (50) 1.0 Treatment with statins (%) 14 (70) 5 (50) 0.4 p Table S3. Clinical characteristics of patients with spontaneous chest pain with and without a final diagnosis of myocardial ischemia Without With myocardial myocardial ischemia ischemia (n=20) (n=10) Age (years) 62 15 64 14 0.5 Male sex (%) 14 (70) 7 (70) 1.0 Diabetes (%) 12 (60) 4 (40) 0.7 Current Smoker (%) 4 (20) 2 (20) 1.0 Hypertension (%) 15 (75) 5 (50) 0.8 Hypercholesterolemia (%) 12 (60) 6 (60) 1.0 Previous angioplasty (%) 2 (10) 2 (20) 0.7 Previous surgery (%) 0 (0) 0 (0) 1.0 Previous revascularization (%) 2 (10) 2 (20) 0.7 Previous infarction (%) 2 (10) 2 (20) 0.7 ST-segment depression (%) 2 (10) 2 (20) 1.0 T-wave inversion (%) 0 (0) 0 (0) 0.5 Treatment with beta-blockers (%) 4 (20) 2 (20) 1.0 Treatment with nitrates (%) 2 (10) 1 (10) 1.0 Treatment with statins (%) 10 (50) 5 (50) 1.0 p Table S4. Spectral weights/loadings contributions to the PLS-DA model See Book 1 in MS Excel file. Table S5. PLS-DA model scores, final diagnosis and predicted diagnosis in the data set of patients with angioplasty-induced myocardial ischemia and angiography controls See Book 2 in MS Excel file. Table S6. PLS-DA model scores, final diagnosis and predicted diagnosis in the data set of patients with spontaneous chest pain evaluated in the Emergency Department See Book 3 in MS Excel file.