Supplementary Text and Figures

Biological NMR Data Bank (BMRB): White Paper on Future Funding
Contents
Page
I. Executive Summary
II. Introduction
III. BMRB as a Resource for the Biological NMR Community
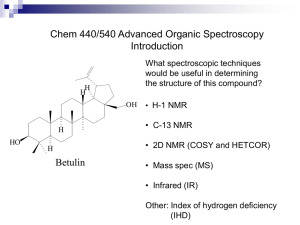
IV. Role of NMR Spectroscopy in Advancing Science and Education
V. History and Organization of the BMRB
VI. BMRB Funding Requirements
VII. Co-signers
VIII. References Cited
3
4
5
6
1
1
2
2 i
I. Executive Summary
The Biological Magnetic Resonance Data Bank (BMRB) has been funded by the National Library of
Medicine (NLM), US National Institutes of Health, since its founding in 1990. The NLM has announced that funding for all of its external centers will be terminated when the current grants run out (09/14/2014 in the case of BMRB). In addition, the current BMRB grant now has been cut 35% below its previous funding level, which was the minimum for full operation. This white paper has been written to provide information about
BMRB and its activities to potential funding agencies.
Advances in the biological sciences are increasingly dependent on the presence of large databases of archived experimental data. Examples of essential databases include the sequence (GenBank, Uni-Prot), pathway (KEGG), structural (wwPDB), and biophysical databases (MassBank, BMRB). Free and open access to these data has supported innumerable research activities, methods development, and medical advances. BMRB alone and in its role as a partner in the Worldwide Protein Data Bank (wwPDB) has had a tremendous impact on the field of biological nuclear magnetic resonance (NMR) spectroscopy and has the strong support of a broad scientific community. Indeed, in recognition of the importance of such data, granting agencies and journals are tightening their requirements for data deposition. BMRB’s large database of protein NMR chemical shifts has been used to develop and refine the software tools routinely used to assign NMR spectra, determine structural restraints, and solve three-dimensional (3D) structures.
These data also have been instrumental in developing algorithms for the calculation of 3D structural models from assigned chemical shifts alone. The growing archives of spectral parameters for proteins, RNA, and
DNA molecules under defined conditions, which provide information about their structures and thermodynamic and dynamic properties, are leading to the development of new methods and a better understanding of protein and nucleic acid function. Protein and recently nucleic acid NMR studies are often directed at potential drug targets or understanding the mechanisms of human disease or human pathogens.
Rapidly expanding genomic, proteomic, and metabolomic studies are generating vast quantities of data that provide extensive lists of the cellular components that make up the biological world. These data are overwhelming our resources for carrying out detailed experimental investigations of the structure and function of medically relevant systems. Computational simulation techniques developed and validated from the extensive and broad sampling of data in public archives are beginning to address this issue. The combination of computer simulations with data from NMR chemical shifts, relaxation parameters, small angle X-ray scattering (SAXS), and other experimental approaches is improving our understanding of conformational dynamics. There is a critical need to continue to build public archives that contain the experimental and computational results underlying the development of next generation technology needed to improve our understanding of complex systems. The BMRB archive is designed to provide the research and educational communities with a unique mix of experimental and computational data in formats that enable and stimulate further research. The impact of the archive on education, basic research, and translational research in the field of human health has been significant and will continue to grow. BMRB has widespread support from within the biomolecular NMR community.
II. Introduction
The growing fields of systems biology, translational medicine, and metabolomics, along with the established biochemical fields of biomolecular structure-function relationships and enzymology are all served by biological NMR spectroscopy. NMR spectroscopy is a unique technology that can be applied to determine
3D structures, investigate molecular interactions, measure binding constants, follow enzyme kinetics, or quantify the primary and secondary metabolome of an organism. Researchers carrying out these studies are characterizing new drug targets, identifying novel pharmaceutical scaffolds for next generation drug candidates, defining biomarkers for disease states, characterizing the metabolic flux within organisms, and providing new insights into the dynamics of biopolymers and conformations of excited states of proteins and nucleic acids that are important for function. Advances in all of these areas by researchers and those developing improved NMR methods have relied on the growth in depth and breadth of the BMRB and the
PDB public data banks. The BMRB archive is unique among biophysical data banks in that the archive contains primary time-domain data generated on the NMR spectrometers, processed spectra, spectral peak characteristics, assigned spectral peak chemical shifts and derived data such as relaxation parameters, p K a
1
values, and for small molecules, atomic coordinates for certain molecules not covered by the wwPDB archive.
III. BMRB as a Resource for the Biological NMR Community
The mission of the Biological Magnetic Resonance Data Bank (BMRB) is to collect, validate, annotate, archive, and disseminate (worldwide in the public domain) the important spectral and quantitative data derived from NMR spectroscopic investigations of biological molecules and their application to biomedicine.
The goal is to empower scientists in their analysis of the structure, dynamics, and chemistry of biological systems and to support further development of the field of biomolecular NMR spectroscopy. BMRB clearly has contributed to the development of novel methods that have improved the quality and quantity of information derived from NMR studies of biological systems and is uniquely poised to contribute to further developments in these fields. NMR spectroscopy offers a critical approach to expanding our knowledge of the fundamental physical properties of proteins and nucleic acids and how these properties depend on their environment, the dynamic character of their structures, and interactions with other molecules. These applications all have direct relevance to elucidating the molecular basis of disease and to drug discovery.
IV. Role of BMRB in Advancing Science and Education
Biological NMR spectroscopy provides atomic level information about the structure, dynamics, chemical environment, and concentrations of biopolymers and small molecules in pure states and in combination with other molecules. The field continues to evolve as new methods are published for collecting data, processing raw spectral data, extracting peak positions and peak characteristics, deriving structures, and extracting information about the dynamics, thermodynamics, and kinetics parameters of complex systems. Many of these advances have been made possible through the existence of large collections of data available from the public BMRB and wwPDB databases. BMRB exists by virtue of public funding and data deposition requirements imposed by funding agencies and journals. Individual research groups do not have funds to acquire, validate, archive, and distribute the quantities of data required to carry out research studies or methods development that involve statistical analysis and probabilistic tools. Data archived by journals as supplemental materials are not available in formats that can be easily parsed and incorporated into local laboratory databases for research studies and method development.
All detailed biological NMR studies are based on extensive assignments of spectral peaks to specific consuming (months), and error-prone task that relied on the analysis of data from multiple spectra. Initial
3D structures--these technologies will improve as the
BMRB archive expands. A long-term goal of biological
NMR studies has been the ability to calculate 3D structures for proteins and nucleic acids from
Table I. Software development related to BMRB.
Software package Reference Citations
(as of 04/2012) atoms in the molecule(s) being studied. For proteins and nucleic acids, this previously was a tedious, timeadvances in automating the required steps relied on local databases of limited scope, but, with the availability of BMRB’s rapidly growing database of experimental chemical shifts, the technology has evolved and improved. Tools are now available for automating or semi-automating the chemical shift assignment process, validating assigned chemical shifts, and for back calculating chemical shifts from
Abacus
ASCAN
AutoAssign
AVS
CCPN
CS23D
CS-Rosetta
Newton
PANAV
PINE-NMR
Promega rNMR
ShiftX/ShiftX2
SPARTA/SPARTA+
TALOS/TALOS+
VASCO
27
30
201
59
342
73
231
7
4
34
9
17
266/15
252/13
2402/233
6 assigned chemical shift data. Recently, three groups have published tools that address this problem. The software is computationally intensive, difficult to install, and is being continually upgraded. These features make it difficult for the developers to provide wide access to the software and for local labs to install and maintain the software for their use. A publicly funded facility is ideal for making these kinds of tools available to the NMR community. BMRB has collaborated with David
Baker, the developer of one of these approaches (CS-Rosetta), and Miron Livny, the developer of a
2
distributed processing network (Condor) to make the tool publicly accessible. Table 1 lists software influenced by the BMRB archive and its impact as judged by number of citations. On-going improvements in the published methods and the possible development of entirely new ideas will require access to extensive public archives of experimental data gathered from research groups worldwide.
New methods are being developed for the rapid collection and analysis of multi-nuclear, multi-dimensional
NMR spectral data. In some cases these methods rely on expectation values derived from an analysis of the predicted chemical shifts of the molecule being studied. In all cases, validation of new techniques requires testing results against data derived by earlier approaches. Developing efficient and complete NMR spectral peak picking algorithms applicable to a wide variety of NMR experiments with variable spectral quality will require access to NMR time-domain data from a large collection of experimental studies on biological systems with a range of characteristics. Further refinement of automated and validated spectral peak assignment algorithms will require advanced statistical analysis of a very large and diverse database of assigned chemical shifts with and without corresponding 3D atomic coordinate data. Because NMR chemical shifts represent a time-averaged conformation of a molecule in solution, relaxation data describing the conformational flexibility of a molecule will be important for constructing improved algorithms. The importance of macromolecular conformational dynamics to function is increasingly being recognized.
Dynamics and relaxation dispersion NMR studies provide insights into the mechanistic and structural properties of proteins and nucleic acids, and the availability of this information in accessible form should stimulate new approaches to their analysis, as occurred earlier with NMR chemical shift data.
Access to a large collection of NMR experimental data has been essential for the development of NMR spectroscopy as a tool for the analysis of biological structure-function relationships, as a contributor to biomarker identification and drug discovery, and understanding at a structural and atomic level biological pathways and their regulation. Several promising new areas are benefitting from access to BMRB and are
providing results that are taking the archive in new directions. Metabolomics [20, 21] and
in vivo NMR
best approach to studying intrinsically disordered proteins (IDPs) to determine the functional importance of
experimental data. Changes in protein dynamics have been found to underlie mutations related to human
disease [28], and NMR offers the most general experimental approach to understanding such effects.
BMRB provides the sole repository of experimental data relevant to intrinsic disorder and dynamics.
Continued development of the field will require the presence of a public archive for primary experimental
NMR data and the quantitative information derived from these data. Without the BMRB, individual laboratories would be forced to repeat work already paid for by public funds. As a well-curated, autocalibrating database, BMRB provides a valuable resource to the larger scientific community.
V. History and Organization of the BMRB
A proposal was submitted to the National Library of Medicine (NLM), US National Institutes of Health, for funds to create and maintain the NMR data resource. The original grant was funded in 1988 as a Research
Grant (R01), but the funding mechanism was changed later to a Biotechnology Resource Grant Program
In 2008, the NLM announced that it would reduce the number of extramural centers it supports from five to three and that the funding for each would be capped at $500,000 (direct costs / year). BMRB survived that round and was awarded a 5-year grant in 2009, but the funding cap reduced its budget by ~35%. In addition, the NLM announced that funding for all centers would be phased out at the end of the grant period.
The budget decrease was alleviated in the first two years of the renewal by supplements from the American
Recovery and Reinvestment Act. Currently, BMRB is faced with identifying a new source of funding by the date the NLM grant terminates (09/14/2014) and replacing the funds required for full operation of the facility as soon as possible.
BMRB is a member of the Worldwide Protein Data Bank (wwPDB) where it participates in common activities related to descriptions of the three-dimensional structures of proteins and nucleic acids determined by NMR
3
spectroscopy. BMRB was the major player in developing the ADIT-NMR deposition system, which currently is responsible for deposition of >95% of the NMR-derived structures of proteins and nucleic acids. BMRB is responsible for the validation and annotation of NMR chemical shift data and structural restraints released to the public through the BMRB and other branches of the wwPDB. BMRB currently is participating in the wwPDB effort to develop a common deposition system that ultimately will handle 3D structural data acquired by X-ray crystallography, NMR spectroscopy, cryo-electron microscopy, and small angle X-ray scattering experiments. BMRB also is involved in a wwPDB effort on the validation of structures determined by NMR spectroscopy.
Approximately 70% of the activities at BMRB (and 37% of depositions) lie outside of the collaboration with the wwPDB. These activities include the archiving of data associated with the diverse classes of biomolecular NMR studies that do not result in structure determinations. BMRB collects experimental data associated with investigations of intrinsically disordered proteins, studies of excited states of proteins, folding of proteins and RNA molecules, molecular dynamics, molecular interactions and p K a
determinations, and studies of metabolites and other small biomolecules. BMRB has the policy of accepting primary data associated with any type of NMR experiment. In general these include the raw time-domain data, intermediate processed data, and extracted parameters such as (assigned) peak lists. Currently the BMRB archive contains a large collection of primary data for pure metabolites and other small molecules plus data sets for over 200 protein structures solved by NMR spectroscopy at NIH Protein Structure Initiative sites.
The Biochemistry Department at the University of Wisconsin has been highly supportive of BMRB. In early
2012, BMRB moved into 2000 ft 2 of newly remodeled space, which includes a server room, a conference room, an office for the Director, and cubicles for programmers, annotators, and student workers. BMRB benefits from its proximity to the National Magnetic Resonance Facility at Madison (NMRFAM), which also is located in the Biochemistry complex. BMRB staff members consult NMRFAM staff members on a regular basis for answers to technical questions and as a test bed in developing new services.
BMRB disseminates data and other resources through the website ( www.bmrb.wisc.edu
) and mirror sites in
Osaka, Japan (bmrb.protein.osaka-u.ac.jp/) and Florence Italy (http://bmrb.cerm.unifi.it/). The Osaka site also accepts data depositions and carries out data processing and validation activities. A deposition system for atomic coordinate data from NMR studies of biological molecules not accepted by the PDB has been developed by BMRB and is operated by the PDBj-BMRB group in Osaka.
In addition to spectroscopists and programmers, the BMRB team includes professors in computer science.
Prof. Miron Livny (Department of Computer Sciences, University of Wisconsin-Madison) and his team provide support in distributed processing and data visualization. Prof. Yannis Ioannidis (Department of
Informatics and Telecommunications, University of Athens, Greece), along with BMRB staff members and others in the NMR community, have constructed an ontology for biological NMR referred to as NMR-STAR
(http://www.bmrb.wisc.edu/formats.html). The Self-defining Text Archival and Retrieval (STAR) language
STAR file format. The ontology defines the allowed NMR-STAR file content in a tag-value system used to archive and exchange NMR data and supports the schema for a relational database that contains the
BMRB archive. The wwPDB mmCIF and pdbx ontologies and formats [33-35] also are designed using
STAR. NMR-STAR is now at version 3.1 and continues to expand and evolve with developments in the field. BMRB maintains compatibility between NMR-STAR and pdbx as part of its role in the wwPDB.
VI. BMRB Funding Requirements
To maintain the BMRB archive in its current state, to sustain BMRB operations at a minimal level, and to develop the archive to meet the needs of customers requires 6.5 full-time employees and an additional 6-8 part-time student workers. In addition, BMRB is led by world renowned experts in the fields of biological
NMR spectroscopy and computer sciences and advised by a board of NMR experts with specialties covering various areas of biological NMR spectroscopy. The full BMRB staff would include 3.5 FTEs with expertise in biological NMR spectroscopy (a team leader responsible for all day-to-day operations, a lead annotator, a person responsible for processing NMR restraints data and maintaining the BMRB web site, and a person responsible for collecting and processing the metabolomics data). Two of these individuals
4
(the team leader and the person processing the NMR restraints and maintaining the web site) require software programming knowledge. Three additional individuals with professional software programming skills are required to develop and maintain the BMRB data deposition, validation, processing systems, relational database archives, and the data query and visualization tools that underlie the BMRB web site.
The student workers are essential for processing, validating, and annotating in a timely manner the more than 800 BMRB entries received each year. Funds are also required for BMRB to meet its obligations as a partner in the wwPDB. These include travel funds for BMRB staff members to attend wwPDB workshops and for the BMRB Head and two members of the biomolecular NMR community representing BMRB to attend the annual meeting of the wwPDB Advisory Committee. The total budget required is about $800,000
(DC) / year.
VII. Co-signers
BMRB Principals
John L. Markley, Head, BMRB, Biochemistry, University of Wisconsin-Madison
Eldon L. Ulrich, Director, BMRB, Biochemistry, University of Wisconsin-Madison
Miron Livny, Computer Sciences, University of Wisconsin-Madison
Yannis Ioannidis, Department of Informatics and Telecommunications, University of
Athens, Greece
Members of the BMRB Advisory Board
Hashim Al-Hashimi, Chemistry & Biophysics, University of Michigan
Cheryl H. Arrowsmith, Medical Biophysics, University of Toronto, Canada
Martin Blackledge, IBS/LRMN, Grenoble, France
Val érie Copié, Chemistry & Biochemistry, Montana State University
Mei Hong, Chemistry, Iowa State University
Gaetano T. Montelione, CABM, Rutgers Univeristy
Others in the biomolecular NMR community
R. Andrew Byrd, Structural Biophysics Laboratory, Frederick National Laboratory
Jeffrey C. Hoch, Molecular, Microbial, and Structural Biology, University of Connecticut
Health Center
Kurt W üthrich, The Scripps Research Institute
5
VIII. References Cited
1. Grishaev A, Steren CA, Wu B, Pineda-Lucena A, Arrowsmith C, Llinas M. (2005) ABACUS, a direct method for protein NMR structure computation via assembly of fragments. Proteins 61(1): 36-
43.
2. Fiorito F, Herrmann T, Damberger FF, Wuthrich K. (2008) Automated amino acid side-chain
NMR assignment of proteins using (13)C- and (15)N-resolved 3D [ (1)H, (1)H]-NOESY. J Biomol
NMR 42(1): 23-33.
3. Zimmerman DE, Kulikowski CA, Huang Y, Feng W, Tashiro M, Shimotakahara S, Chien C, Powers
R, Montelione GT. (1997) Automated analysis of protein NMR assignments using methods from artificial intelligence. J Mol Biol 269(4): 592-610.
4. Moseley HN, Sahota G, Montelione GT. (2004) Assignment validation software suite for the evaluation and presentation of protein resonance assignment data. J Biomol NMR 28(4): 341-55.
5. Fogh R, Ionides J, Ulrich E, Boucher W, Vranken W, Linge JP, Habeck M, Rieping W, Bhat TN,
Westbrook J, Henrick K, Gilliland G, Berman H, Thornton J, Nilges M, Markley J, Laue E. (2002)
The CCPN project: an interim report on a data model for the NMR community. Nat Struct Biol
9(6): 416-8.
6. Wishart DS, Arndt D, Berjanskii M, Tang P, Zhou J, Lin G. (2008) CS23D: a web server for rapid protein structure generation using NMR chemical shifts and sequence data. Nucleic Acids Res
36(Web Server issue): W496-502.
7. Shen Y, Lange O, Delaglio F, Rossi P, Aramini JM, Liu G, Eletsky A, Wu Y, Singarapu KK, Lemak A,
Ignatchenko A, Arrowsmith CH, Szyperski T, Montelione GT, Baker D, Bax A. (2008) Consistent blind protein structure generation from NMR chemical shift data. Proc Natl Acad Sci U S A
105(12): 4685-90.
8. Chylla RA, Hu K, Ellinger JJ, Markley JL. (2011) Deconvolution of two-dimensional NMR spectra by fast maximum likelihood reconstruction: application to quantitative metabolomics. Anal Chem
83(12): 4871-80.
9. Wang B, Wang Y, Wishart D. (2010) A probabilistic approach for validating protein NMR chemical shift assignments. J Biomol NMR 47(2): 85-99.
10. Bahrami A, Assadi AH, Markley JL, Eghbalnia HR. (2009) Probabilistic interaction network of evidence algorithm and its application to complete labeling of peak lists from protein NMR spectroscopy. PLoS Comput Biol 5(3): e1000307. PMCID: PMC2645676
11. Shen Y, Bax A. (2010) Prediction of Xaa-Pro peptide bond conformation from sequence and chemical shifts. J Biomol NMR 46(3): 199-204.
12. Lewis IA, Schommer SC, Markley JL. (2009) rNMR: open source software for identifying and quantifying metabolites in NMR spectra. Magn Reson Chem 47: s123-s6. NIHMSID: 165967
13. Han B, Liu Y, Ginzinger SW, Wishart DS. (2011) SHIFTX2: significantly improved protein chemical shift prediction. J Biomol NMR 50(1): 43-57.
14. Neal S, Nip AM, Zhang H, Wishart DS. (2003) Rapid and accurate calculation of protein 1 H, 13 C and
15 N chemical shifts. J Biomol NMR 26(3): 215-40.
15. Shen Y, Bax A. (2007) Protein backbone chemical shifts predicted from searching a database for torsion angle and sequence homology. J Biomol NMR 38(4): 289-302.
16. Shen Y, Bax A. (2010) SPARTA+: a modest improvement in empirical NMR chemical shift prediction by means of an artificial neural network. J Biomol NMR 48(1): 13-22.
17. Shen Y, Delaglio F, Cornilescu G, Bax A. (2009) TALOS+: a hybrid method for predicting protein backbone torsion angles from NMR chemical shifts. J Biomol NMR 44(4): 213-23.
18. Cornilescu G, Delaglio F, Bax A. (1999) Protein Backbone Angle Restraints From Searching a
Database for Chemical Shift and Sequence Homology. J Biomol NMR 13(3): 289-302.
19. Rieping W, Vranken WF. (2010) Validation of archived chemical shifts through atomic coordinates. Proteins-Structure Function and Bioinformatics 78(11): 2482-9.
6
20. Gebregiworgis T, Powers R. (2012) Application of NMR Metabolomics to Search for Human
Disease Biomarkers. Comb Chem High Throughput Screen.
21. Wishart DS. (2011) Advances in metabolite identification. Bioanalysis 3(15): 1769-82.
22. Begley JK, Redpath TW, Bolan PJ, Gilbert FJ. (2012) In vivo proton magnetic resonance spectroscopy of breast cancer: a review of the literature. Breast Cancer Research 14(2): 207.
23. Serkova NJ, Brown MS. (2012) Quantitative analysis in magnetic resonance spectroscopy: from metabolic profiling to in vivo biomarkers. Bioanalysis 4(3): 321-41.
24. Kurth J, Defeo E, Cheng LL. (2011) Magnetic resonance spectroscopy: a promising tool for the diagnostics of human prostate cancer? Urol Oncol 29(5): 562-71.
25. Glunde K, Jiang L, Moestue SA, Gribbestad IS. (2011) MRS and MRSI guidance in molecular medicine: targeting and monitoring of choline and glucose metabolism in cancer. NMR Biomed
24(6): 673-90.
26. Lerche MH, Meier S, Jensen PR, Hustvedt SO, Karlsson M, Duus JO, Ardenkjaer-Larsen JH. (2011)
Quantitative dynamic nuclear polarization-NMR on blood plasma for assays of drug metabolism.
NMR Biomed 24(1): 96-103.
27. Schneider R, Huang JR, Yao M, Communie G, Ozenne V, Mollica L, Salmon L, Jensen MR,
Blackledge M. (2012) Towards a robust description of intrinsic protein disorder using nuclear magnetic resonance spectroscopy. Molecular Biosystems 8(1): 58-68.
28. Manley G, Loria JP. (2012) NMR insights into protein allostery. Arch Biochem Biophys 519(2):
223-31.
29. Ulrich EL, Markley JL, Kyogoku Y. (1989) Creation of a Nuclear Magnetic Resonance Data
Repository and Literature Database. Protein Seq Data Anal 2(1): 23-37.
30. Hall SR. (1991) The STAR File: A New Format for Electronic Data Transfer and Archiving. Journal
of Chemical Information and Computing Sciences 31: 326-33.
31. Hall SR, Cook APF. (1995) STAR dictionary definition language: initial specification. Journal of
Chemical Information and Computing Sciences 35: 819-25.
32. Hall SR, Spadaccini N. (1994) The STAR File: Detailed Specifications. Journal of Chemical
Information and Computing Sciences 34: 505-8.
33. Bourne PE, Berman HM, McMahon B, Watenpaugh KD, Westbrook JD, Fitzgerald PMD. (1997)
The Macromolecular Crystallographic Information File (mmCIF). Methods Enzymol 277: 571-90.
34. Westbrook JD, Bourne PE. (2000) STAR/mmCIF: an ontology for macromolecular structure.
Bioinformatics 16(2): 159-68.
35. Westbrook JD, Fitzgerald PM. (2003) The PDB format, mmCIF, and other data formats. Methods
BiochemAnal 44: 161-79.
7