Chapter 18 - TeacherWeb
advertisement

"It has been proved beyond a shadow of a doubt that smoking is one of the leading causes of
statistics."
Fletcher Knebel
Chapter 18: SAMPLING DISTRIBUTION MODELS (Pages 410 - 431)
OVERVIEW: One examines samples in order to come to reasonable conclusions about
the population from which the sample is chosen. One must be statistically literate in order
to glean meaningful information from a sample. This involves an awareness of what the
sample results tell us, along with what they don't tell us. A statistic calculated from a
sample may suffer from bias or high variability, and hence not represent a good estimate
of a population parameter.
Ideal Situation:
Another Route:
Parameter:
Statistic:
Quanity
Mean
Std. Deviation
Proportion
Statistic
Parameter
Will all samples of the same size give us the same statistics?
Sampling Variability( Sampling Error):
Why we consider a sample statistic to be a random variable w/ a distribution.
Sampling distribution of a statistic:
The following example demonstrates some of the statistical concepts developed in this section.
Consider the three element population P ={1,2,3}.
The mean of P is
The standard deviation of P is =
The variance of P is 2 =
These values are parameters, since they are derived from a population.
Now, consider all possible samples of size 2, with replacement. There would be 32 = 9 such samples.
The Sampling Distribution Model, which contains the stats for every possible sample of size 2, looks
like this:
Sample Sample Mean = x
Sample Var. = s2
Sample St.Dev.= s
1,1
1
0
0
1,2
1.5
.5
.707107
1,3
2
2
1.4142
2,1
1.5
.5
.707107
2,2
2
0
0
2,3
2.5
.5
.707107
3,1
2
2
1.4142
3,2
2.5
.5
.707107
3,3
3
0
0
MEANS
A statistic is unbiased if the mean of the sampling model is equal to the true value of the parameter
being estimated.
Dist. of Means
The table shows that...
-the mean of the sampling distribution model means is the mean ( )of the population. This illustrates
that a sample mean is an unbiased statistic/estimator of the population mean. (The distribution of
sample means "centers" around the mean of the population.)
-the mean of the sampling model variances (s2) is equal to the variance ( 2) of the population. This
illustrates that a sample variance (s2) is an unbiased statistic/estimator of the population variance. (The
distribution of sample variances "centers"around the variance of the population.)
- A sample standard deviation is not an unbiased estimator of the population standard deviation. In this
example, the mean of the sample standard deviations is s = 0.628539, and the standard deviation of the
population is = 0.81649658. (The distribution of sample standard deviations does "not center" around
the standard deviation of the population.)
* Note: An unbiased statistic itself may fall above or below the true value of the parameter, but the
distribution of the statistics mean will be equal to the mean of the parameter.
How does knowing that the numbers do this when it comes to sampling distribution models help us?
If a few assumptions are met by checking some conditions, then we are allowed to apply the
Normal Model to our information.
Assumptions and Conditions:
1. Independence Assumption: The sampled values must be independent. It is hard to be sure unless
they give us this information in the problem, therefore we just check the
Randomization Condition:
10% Condition:
2. Large enough Sample Condition: If the original population distribution is Normal, then the sample
can be small. If the original population distribution is skewed, then have to have a bigger sample.
When these conditions are met, not only can we apply the Normal Model but we can also use
The Central Limit Theorem which is often referred to as the Fundamental Theorem of Statistics.
CLT: says that the mean of a random sample has a sampling distribution whose shape can be
approximated by a Normal model. The larger the sample, the better the approximation will be.
*Even cooler than that, the CLT says that no matter what the shape of the distribution is originally, as
the sample size increases, the sampling distribution model will get more and more normal.
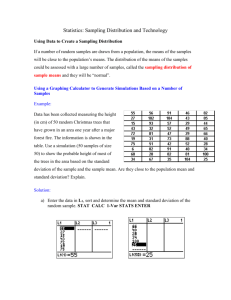
Let’s investigate some pennies!
So the Central Limit Theorem says that the sampling distribution of any mean is approximately Normal.
The sampling distribution model for a mean
When a random sample is drawn from any population with mean and standard deviation ,
it’s sample mean, x , has a sampling distribution with the same mean but the
standard deviation will be SD(x)
Therefore, the model we use is N(
.
,
).
Ex1. SAT scores should have mean 500 and standard deviation 100. What about the mean of random
samples of 20 students?
Solution:
Think – We are interested in the distribution of possible means from samples of SAT
scores from 20 students. SAT scores have a mean of 500 and a standard deviation of 100,
and since the SAT is standardized, it’s reasonable to assume that the model for all SAT
scores is Normal.
Independence Assumption: It’s reasonable to think that the SAT scores of the 20 randomly sampled
students will be independent, as long as the students weren’t all from the same university.
Random Sampling Condition: The 20 students were sampled randomly.
10% Condition: 20 students represent less than 10% of all students.
Big Enough Sample Assumption: Histogram of the population is unimodal and roughly symmetric.
n = 20 is large enough for CLT to take effect
Under these conditions, the sampling distribution of x has a Normal model with mean
Show -
Tell –
Ex2. Speeds of cars on a highway have mean 52 mph and standard deviation 6 mph, and are likely to be
skewed to the right (a few very fast drivers). Describe what we might see in random samples of 50 cars.
Solution:
Think – We are interested in the distribution of possible means from samples of speeds from 50 cars on
the highway. Speeds have a mean of 52 mph and a standard deviation of 6 mph, with a distribution that
is skewed to the right.
Independence Assumption: It’s reasonable to think that the speeds of the 50 randomly sampled cars
will be independent.
Random Sampling Condition: The 50 speeds were sampled randomly.
10% Condition: 50 cars represent less than 10% of all cars.
Big Enough Sample Assumption: Even though the distribution is skewed, the Central Limit Theorem
applies, since thesample size, 50 cars, is large. Under these conditions, the sampling distribution of x
has a
Show -
Tell –
Ex3. At birth, babies average 7.8 pounds, with a standard deviation of 2.1 pounds. A random sample of
34 babies born to mothers living near a large factory that may be polluting the air and water shows a
mean birthweight of only 7.2 pounds. Is that unusually low?
Solution:
Think – We are interested in the probability that a sample of babies has mean birthweight less than 7.2
pounds. At birth, babies average 7.8 pounds, with a standard deviation of 2.1 pounds. The model for
birthweights should be roughly unimodal and symmetric, if not Normal.
Independence Assumption: It’s reasonable to think that the weights of the 50 randomly sampled babies
will be independent.
Random Sampling Condition: The 34 babies were sampled randomly.
10% Condition: As long as more than 340 babies were born to mothers living in the vicinity of the
factory, 34 babies represent less than 10% of all babies. Since the model for all babies is unimodal and
symmetric, the Central Limit Theorem applies, especially since the sample size, 34 babies, is large.
Under these conditions, the sampling distribution of x has a Normal model,
Show
Tell –
Sample Proportions
Consider a simple random sample (SRS) of 1,000 people from a large population. If X represents the
number in this sample who are Republicans, then there are 1,001 possible values of X, namely
0,1,2,3,..., 998, 999, 1000. If p̂ (p-hat) represents the possible sample proportions of Republicans in the
sample, then there are 1,001 possible values of p̂ , namely 0/1000, 1/1000, 2/1000,..., 998/1000,
999/1000, 1000/1000.
For a given sample, we might find p̂ = .56. For another sample, we might find p̂ = .52. We could
choose many SRS's and calculate a p̂ for each sample. In general, we would expect the distribution of
p̂ to be approximately normal.
Once again, if a few assumptions are met by checking some conditions, then we are allowed to apply a
Normal Model to our information.
Assumptions:
1.
2.
Since it is hard to check assumptions, we verify the following conditions:
1. Randomization Condition:
2. 10% Condition:
3. Success/Failure Condition:
If we choose an SRS of size n from a large population with population proportion p having some
characteristic of interest, and if p̂ is the proportion of the sample having that characteristic, then
-
-
- The standard deviation of the sampling distribution is
- So, in symbolic notation we have the following distribution:
Example:
The Census Bureau reports that 40% of the 50,000 families in a particular region have more
than one color TV in their household. What is the probability that a SRS of size 100 will indicate 45% or
more households with more than one color TV when the population proportion is 40%?
Solution
p _____, n ______, pˆ ____
a.check assumptions/conditions
Randomization Condition:
10% Condition:
Success/Failure Condition:
b. calculate
go to the z-chart or use the TI to do a normcdf(
there is a probability of roughly
that a sample of size 100 will have a proportion of .45 or
more when the population proportion is .40. In other words a sample proportion of .45 is not
necessarily an unexpected event, and could easily occur due simply to sampling variation.
Example:
Suppose it is known that 60% of the registered voters in a district of over 20,000 people are
Republicans. If you choose an SRS of 1000 registered voters,
(a) what is the probability that the proportion of registered voters in the sample is
between 58% and 62%?
(b) what is the probability that the sample will contain no more than 550 Republicans?
First, note that both assumptions and conditions are satisfied. The sample proportion p̂
has mean =
and standard deviation =
Response to (a):
Using the TI-83, normalcdf(
Response to (b):
1. Records at a large university indicated that 20% of all freshman are placed on academic
probation at the end of their first semester. A random sample of 100 of this year’s freshman
indicated that 25% of them were placed on academic probation at the end of the first
semester. The results of this sample:
(A) are surprising since it indicates that 5% more were placed on probation than was expected.
(B) are surprising since SAT scores have been increasing over the past few years.
(C) are not surprising since the standard deviation of the sampling distribution is 4%.
(D) are surprising since the standard deviation of the sampling distribution is .4%.
(E) are biased since the increase of 5% could not happen w/o injecting bias into the sample.
2. According to the manufacturer, the average proportion of red candies in a package is 20%. An 8oz.
package contains 250 candies. Find the probability that a randomly selected 8 oz. package contains less
than 45 red candies.
3. A mathematics department published the claim that a minimum of 70% of students enrolled in their
classes receive a final grade of C- or better in any semester. A SRS of 50 students from the department’s
classes indicated that only 65% of the students had a C- or better. What is the probability that a sample
of this size will have a result that differs from the claimed proportion by more than 5%(above or below)?
Would such a result surprise you? State a conclusion.
4. A SRS of size 200 is taken from a population of 1,000 people in a professional organization regarding
preferences on the issues of raising dues. What is the probability that this sample will produce a result
of 10% or less favoring the raise when it is known that 3.5% of the population favors the raise?
5. Find the size of a SRS needed so that the probability that its proportion differs from the population
proportion by more than 2%(above or below) is .1. Assume that the population proportion is .63.