random hence
advertisement

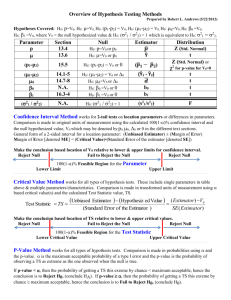
3. Inference in the single regression
This section contains the paragraphs
(3.1) Simple t-tests
(3.2) Confidence intervals for the regression coefficient 1
(3.3) The P value
(3.4) The least square prediction
Sometimes economic theory asserts that the regression coefficients should take
specific values. For example, Friedman’s “Permanent Income hypothesis” put forward
the hypothesis that the intercept term 0 0 . If our model is a macro consumption
function, the slope parameter is the marginal propensity to consume income. Thus,
macro economists might be interested in specific hypothesis regarding 1 . But how
should we proceed to test specific hypothesis on 0 and 1 ?
3.1 Simple t-tests
In this paragraph we shall describe procedures for testing hypotheses on 1 .
When we have learned these procedures, we understand that similar approach can be
used to test hypotheses on the intercept parameter.
A test of 1 will naturally take the sampling distribution of the estimator ˆ1 as
~
a starting point. We know already that in this distribution the expectation E ( 1 ) 1 ,
and that the variance Var ( ˆ1 ) is given by (2.4.4). From the expression (2.2.6) for the
estimator ˆ1 we understand that the distribution of ˆ1 is for given X 1 , X 2 ,..., X N ,
determined by the distribution the dependent variables Y1 , Y2 ,..., YN . We understand
that the distribution of ˆ1 will be unknown until we specify a particular distribution
of Y1 , Y2 ,..., YN .
Everything will be put in order when specify the distribution of the random
1
disturbances 1 , 2 ,..., N . . Hence, we supplement the assumptions (2.1.5)- (2.1.7) by
a fourth one, namely!
i is N (0, 2 )
(3.1.1)
and independently, identically distributed for all
i.
Since Yi is a linear function of i , it follows that:
Yi is N ( 0 1 X i , 2 )
(3.1.2)
The independence of the ’s implies that independence of the Y’s. Since the X’s are
deterministic, all random variation of Yi is determined by the randomness of i .
We also observe that the OLS estimator ˆ1 is a linear function of Y1 , Y2 ,...., YN
We can write:
ˆ1
1
N
(X
i 1
(3.1.3)
i
X)
{( X 1 X )Y1 ( X 2 X )Y2 ... ( X N X )YN }
2
N
ciYi
i 1
where
ci
(3.1.4)
(Xi X )
N
(X
i 1
i
X )2
Since ˆ1 is a linear function of Y1 , Y2 ,...., YN , and all the Y ' s are normally
distributed, it follows from standard results in statistics that the estimator ˆ1 is
normally distributed. We write:
(3.1.5)
ˆ1 is N ( 1 , 2
N
(X
i 1
i
X )2 )
In order to get a better “feeling for the problem”, let us assume that we wish to
test a null hypothesis H 0 : 1 0 , given a certain data set. Suppose that if the
calculated estimate of 1 happens to be situated far from 0, then we reject H 0 .
2
However, we realize that we cannot be certain that this is the correct decision since
ˆ1 is a random variable. How should we approach this problem so that the decision
reject or not reject the hypothesis can be given a sound footing. If follows from (3.1.5)
that when H 0 is correct the distribution of the estimator ˆ1 is given by:
(3.1.6)
ˆ1 is N (0, 2
N
(X
i 1
i
X )2 )
Hence, even if our estimate is situated far from 0, it is not fully contradicted by
the distribution of ˆ1 under H 0 . We understand that whatever decision, regarding
rejecting or not rejecting, we take a certain risk that our decision will be wrong:
We
might reject the null hypothesis when it is in fact true, or we might not reject when it
is in fact false. In this literature one talks about making errors of Type I (the first
situation) or of Type II (the second situation). To solve this dilemma the following
proposal is reasonable. Since we specify a given value of 1 under H 0 , we know the
distribution of ˆ1 when H 0 is true. Utilizing this distribution we can compute the
exact probability of committing a Type I error. In this literature this probability is
called the level of significance of the test. It is so important that it deserve a separate
definition.
Definition 3.1. The level of significance of a test is that probability we accept for
rejecting H 0 when H 0 is true.
Usually the level of significance ( ) is chosen to be a small number, typically
=0.05, =0.025, 0.01 etc.
What remains to know before we can actually carry out a test of a particular
hypothesis about 1 is a few more technical calculations.
Suppose
wish
to
test
the
null
10 is a specified number.
3
hypothesis
H 0 : 1 10
where
Assuming that H 0 is true we know that
N
(X
ˆ1 is N ( 10 , 2
(3.1.7)
i 1
i
X )2 )
From this fact follows immediately that.
ˆ1 1
Z
(3.1.8)
N
(X
2
i 1
i
X )2
ˆ 1 1
is N (0,1)
Std ( ˆ1 )
Hence , the normalized variable Z has a standard normal distribution with mean 0
and standard deviation 1. But to be used as a test statistic, Z has a serious
drawback since it depends on the variance 2 which is unknown to us. But we
2
are almost home. We know that the estimator ˆ given by (2.4.7) is an unbiased
2
2
estimator of . It is very tempting to substitute this estimator for in (3.1.8).
Hence, we have:
T
(3.1.9)
ˆ1 10
ˆ 2
(X
i
ˆ1 10
ˆ ( ˆ1 )
Std
X )2
where Stdˆ ( ˆ1 ) denotes the estimated standard deviation of ˆ1 . Luckily, we also
know the distribution of the random variable T . Usually, we call it Student’s
t-distribution, a distribution which closely related to the N (0,1) distribution. It is
uni-modal and symmetric about 0. The mean E (T ) 0 and the variance is given by
Var(T ) N N 2, so that Var(T ) 1 when N increases.
Figure (3.1.1)
When we test the null hypothesis H 0 : 1 10 , it is reasonable to test H 0 against
4
the three alternative hypotheses specified below, that is to say:
(3.1.10)
H0
H 1A
H A2
1 0
1 01
1 01
H A3
1 01
Let us describe the procedure to follow when we wish to test H 0 against H 1A
and we choose a level of significance . In this case we doubt the truth of
H 0 when
the estimate ˆ1 is considerably larger than 10 . The larger the difference between
ˆ1 and 10 , the more we doubt the truth of H 0 . The chosen level of significance of
the test, , helps us to determine a threshold or critical value of the test statistic T. If
the observed value of the test statistic, T ( ˆ1 10 ) Stdˆ ( ˆ1 ) is larger than the
threshold value, the null hypothesis is rejected.
Since the test statistic T is t-distributed under H 0 , the critical value t c is
determined from the equation:
(3.1.11)
P T tc
where is the chosen level of significance of the test.
Decision rule: Reject H 0 when the estimated value Tˆ of the test statistic (3.1.9)
falls in the interval to the right of the critical value t c , that is if
Tˆ tc , if Tˆ tc
do not reject H 0 .
Figure (3.1.2)
Put in formal terms: if Tˆ (tc , ) reject H 0 if Tˆ (, tc ) do not reject H 0 .
If we wish to test our null hypothesis against H A2 with a level of significance ,
5
the procedure is similar. In this case we doubt the truth of H 0 when the estimate ˆ1
is considerably smaller than 10
Decision rule: Reject H 0 when the estimate Tˆ (,tc ) . Do not reject when
Tˆ (tc ,) .
Figure (3.1.3)
The procedure for testing H 0 : 1 10 against H A3 : 1 10 with level of
significance , follows the same guiding lines.
In this case we are doubtful about the null hypothesis when the estimate ˆ1 is
either much larger or much smaller than 10 This indicates that one shall restrict
intervals in both tails of the t-distribution. The critical value t c / 2 is determined from
the equation:
(3.1.12)
P( T tc / 2 )
Decision rule: Reject
H0
when the estimate
Tˆ
satisfies
Tˆ tc
Tˆ (,tc / 2 ) or Tˆ (tc / 2 ,) . Do not reject H 0 when Tˆ (tc / 2 , tc / 2 ).
The decision rule is illustrated below:
Figure (3.1.4)
6
i.e.
When we test a null hypothesis against one-sided alternatives, we talk about
one-sided tests. Figures (3.1.2)-(3.1.3) illustrate such tests. In the same way Figure
(3.1.4) illustrates a two-sided test.
When we test the null hypothesis H 0 : 1 10 against the two-sided alternative
hypothesis H A3 : 1 10 , we have seen that the decision rule is to reject H 0 when
the test statistic takes a value in either of the two tails of the t-distribution.
3.2 Confidence intervals for the regression coefficient 1
Closely related to a two-sided test with level of significance , is the
construction of a confidence interval for 1 with confidence coefficient (1 ) .
Many textbooks seem to prefer the idea of constructing a confidence interval. The
procedure is simple:
We know that:
(3.2.1)
T
ˆ1 1
is t distributed with N 2 degrees of freedom.
Stdˆ ( ˆ1 )
When we construct a symmetric interval with confidence coefficient (1 ), we
first determine the critical value t c / 2 in the way we have explained above. The
probability of the event tc / 2 T tc / 2 is obviously (1 ).
Formally, we put:
(3.2.2)
ˆ 1
P tc / 2 1
tc / 2 1
Stdˆ ( ˆ1 )
Then we can solve the two inequalities with respect to 1 , attaining:
ˆ (ˆ1 ) 1 ˆ1 tc Std
ˆ (ˆ1 )] 1
P[ˆ1 tc Std
(3.2.3)
2
2
The interval (3.2.3) is equivalent to the interval appearing in (3.2.2). The upper
7
and lower limits are random since the OLS estimator ˆ1 and Stdˆ ( ˆ1 ) are random
variables. Since (3.2.3) follows directly from (3.2.2), one can interpret it by saying
that the interval has a (1 ) probability of covering the true value 1 .
When the estimates ˆ1 and Stdˆ ( ˆ1 ) are attained the two limits appearing in
(3.2.3) are simply given numbers. Although, it may be tempting, it will be incorrect to
say that the unknown parameter 1 is situated between these two limits with
probability (1 ). The point is that there is no random variables involved when we
consider the estimated limits. The statement: “the unknown slope parameter 1 is
contained in the estimated interval” is either true (i.e. 1 is contained in the interval) or
not true (i.e. 1 is not contained in the interval). So when the sample of observations
are given we calculate the two bounds of the interval and present the result in the
form.
“A 100(1 )% confidence interval for 1 computed from the observed
sample is ( Lˆ , Uˆ ) where Lˆ and Uˆ denote the two bounds of the interval”
Above we indicated that there is a close connection between constructing a
two-sided test for 1 and calculating a confidence interval for 1 . The two-sided
test approach leads to the rule: Reject H 0 when the absolute value of the test
statistic exceeds the threshold t c / 2 i. e. reject when Tˆ tc / 2 . Thus, we shall not
reject H 0 when
Tˆ tc / 2 or
t
c
/2
Tˆ tc / 2
which is equivalent to the
conclusion we deduced by constructing the confidence interval for 1 .
Above we have described in detail how to proceed when testing a null hypothesis
H 0 : 1 10 against three standard alternatives H 1A , H A2 and H A3 . We understand
that the same approach applies directly when we wish to test a null hypothesis on the
intercept 0 .
8
Now we use the test statistic
(3.2.4)
G
ˆ0 0
Stdˆ ( ˆ0 )
By standard arguments G is t-distributed with (N-2) degrees of freedom. From
now on we can continue as above.
3.3 The P-value
In constructing the simple t-tests a notion that naturally emerges is the so called
p-value. The p-value, also called the significance probability, is the probability of
drawing a value of the test statistic at least as adverse to the null hypothesis as the one
we actually computed in our sample, assuming the null hypothesis is correct.
Let us assume that we wish to test
(3.3.1)
H 0 : 1 0
against
H 1A : 0
with level of significance . From what has been said above we know the decision
rule: Reject H 0 when the calculated value of the test statistic, Tˆ , is larger than the
critical value t c .
When H 0 is true, we know the test statistic
(3.3.2)
T
ˆ1
is t distributed with N 2 degrees of freedom.
Stdˆ ( ˆ1 )
In order to illustrate a dilemma which easily occurs we use the following figure.
Figure (3.3.1)
In this figure the critical values t 0c.05 and t 0c.15 correspond to the significance
9
levels 0.05 and 0.15 . When the estimates ˆ1 and Stdˆ ( ˆ1 ) are available, we
compute the test statistic Tˆ using (3.3.2). Our decision rule says that if Tˆ is situated
to the right of the relevant critical value t c , we shall reject H 0 . We notice that the
decision to reject H 0 depends on the chosen level of significance . Let us now
have a closer look at the computed value, Tˆ , of the test statistic T . When H 0 is
true we know that the test statistic T has a t-distribution with N 2 degrees of
freedom. Therefore, it is simple task to compute the probability of the event P T Tˆ
under H 0 . It is precisely this probability which is called the P value . That is:
(3.3.3)
P value P T Tˆ
given that H 0 is true.
A specific illustration is shown in Figure (3.3.1). Since Tˆ is situated to the left of
t 0c.05 , the P value will be larger than 0.05 . But it will be smaller than
0.15 since it is situated to the right of t 0c.15 .
Above we have computed the P-value when we tested H 0 against the one-sided
alternative H 1A . If we faced the test problem:
(3.3.4)
H 0 : 1 0 against H A3
(i.e. the two-sided alternative), the situation is a bit different. Let Tˆ denoted the
estimated value of T . If Tˆ 0 we compute the probability P T Tˆ , this
probability is multiplied by 2 since we test against a two-sided alternative. If Tˆ 0
we compute the probability P T Tˆ and multiply by 2.
When we test a null hypothesis against a one-sided alternative, we could the call the
calculated P value a one-sided P value. Similarly, when we test against a
two-sided alternative we could call the P value a two-sided P value .
Owing to what we have deduced above, we have the following conclusion:
10
Reject H 0 whenever the computed P-value is less than the level of significance . If
the P-value is larger than the significance level do not reject H 0 .
Calculating P-values are informative, but our decision dilemma is unchanged:
Shall we reject or not reject the null hypothesis. Any interest in the P-value cannot
conceal this fact.
3.4 The least square prediction
Some times the ultimate aim of our econometric modeling is to predict the value
of the dependent variable (for example a future value of Y ), given the values of the
P
explanatory variables. If X denotes the value of the explanatory variable X, the
value of the dependent variable is, according to our model, given by:
(3.4.1)
Y 0 1 X P
Since the random disturbance fluctuates in a purely random fashion, our best
prediction of is given by the mean E 0. If
we know the structural
parameters 0 and 1 , a natural predictor is given by:
(3.4.2)
Y P 0 1 X P
since the disturbance terms are uncorrelated the best predictor of is, of course, its
mean 0 .
But 0 and 1 are unknown and have to be estimated. It is very reasonable to use
the OLS estimators ˆ0 and ˆ1 . Hence, an estimator of the predictor is given by:
(3.4.3)
Yˆ P ˆ0 ˆ1 X P
As a measure of the prediction uncertainty it is natural to use the prediction error
P
F (Y Yˆ P ) . Since both Y and the predictor Yˆ are random variables, F is
certainly also random. However, we observe directly:
(3.3.4)
E( F ) E(0 1 X P ˆ0 ˆ1 X P ) 0
11
(3.3.4) follows from the unbiasedness of the OLS estimators ˆ0 and ˆ1 .
As to the variance of the prediction error we calculate:
(3.4.5)
Var ( F ) Var (Y Yˆ P ) Var (Y ) Var (Yˆ P )
2
P
The variance of Y is simply , the variance of Yˆ is calculated using
(2.4.3)-(2.4.5), giving
1
(X P X 2)
Var (Yˆ P ) 2 ( N
)
N
2
(Xi X )
i 1
(3.4.6)
Hence, we have:
1
( X P X )2
Var ( F ) (1 N
)
N
2
(Xi X )
2
(3.4.7)
i 1
P
Note that the variance of F has a minimum when X X . In this formula
everything is known except for the variance 2 .
2
However, we have a natural estimator of (given by (2.4.7) above). Using
standard arguments we deduce:
Y Yˆ
P
(3.4.8)
Std (Y Yˆ P )
is t - distributed with N 2 degrees of freedom.
where:
(3.4.9)
1
( X P X )2
Std (Y Yˆ P ) ˆ 2 (1 N
)
N
2
(X i X )
i 1
Constructing a confidence interval for Y
will now follow the familiar guiding lines
we have shown in detail above. Note that many econometric textbooks prefer to call
this interval prediction for Y . Let us assume that we wish to construct a prediction
interval with confidence coefficient (1 ) . Then we start by the relation
12
(3.4.10)
Y Yˆ P
P tc / 2
tc / 2 1
P
Std (Y Yˆ )
Following the recipe described in section 3.2 we find the following interval limits
for Y
(3.4.11)
Yˆ
P
tc / 2 Stdˆ (Y Yˆ P ), Yˆ P tc / 2 Stdˆ (Y Yˆ P )
Interpreting this interval we could say something like that we said above: ”A
100(1 )% prediction interval for Y computed from an observed sample is given
by the lower and upper bounds Lˆ and Uˆ appearing in (3.4.11). Observe that there is
an important difference between the interval constructed in section (3.2) and the one
we have produced here. In section (3.2) the interval is meant to cover the unknown
non-random slope parameter 1 . In this section the interval is meant to cover the
unknown but random variable Y .
13