Reengineering French structural business statistics
advertisement

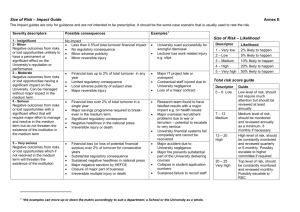
Reengineering French structural business statistics: redesign of the annual survey Olivier HAAG Insee : business statistics directorate 18, bd Adolphe Pinard 75675 Paris cedex 14 France olivier.haag@insee.fr keywords: breakdown of turnover, legal restructuring, merging of data, companies recall The Insee has conducted an important program since September 2004 (Depoutot R., 2010) in order to reduce the number of questions in the Annual Survey on Businesses, to improve its internal productivity, to increase timeliness of the derived statistics and to introduce new statistical units (companies derived from profiling or companies which participate to legal restructuring). This paper will focus on: - The survey content The organisation on the survey staff in order to reach sufficient quality level The specific treatment of enterprise's legal restructuring (merging for example) which has been implemented The merging of the survey data and the available tax and employment data 1. Presentation and aims of the survey The ESA (Enquête Structurelle Annuelle, ie. Insee Annual Survey on Businesses) has been strongly lightened (Insee, 2009). Excepted for turnover, the survey does not include any of the questions already existing in other administrative or fiscal source. This survey enables specially to publish the level and growth rate of aggregates for the different characteristics, and to determine the main activity of inquired businesses for the statistical register. In the manufacturing industry it is integrated with the Prodcom Survey. This survey is the most important survey of businesses carried out in six of the main production sectors1. It comprises two parts for each sector: - A core section which includes in particular the breakdown of turnover by different activity at a very detailed level (much more detailed than NAF2 classes in Distributive trade and Services), questions on employment and legal restructuring - A sectoral part of the questionnaire relating to the characteristics of the companies that are specific to a given sector: sales area for companies in the trade sector, spending of fuel for companies in the transport sectors, etc… The statistical burden on companies, which has been bearing on the preparation of the French response to the SBS regulation, is derived almost exclusively from the response to this survey. All companies above a certain size threshold3 are surveyed (about 83 000 companies of which 30 000 1 Industry, excluding the agri-food industry, the agri-food industry, transport, construction, trade and services. NB. Banks and insurance companies are not included in this survey. 2 The NAF is the French equivalent of the NACE 3 Which can vary from sector to sector. This threshold ranges from 20 to 50 employees 1 for the manufacturing industry); conversely a sample of those below the threshold are surveyed (about 79 000 companies among 2 500 000). For the first time and to facilitate the using of administrative data, we have asked the firms to provide us its turnover based on the accounting period relying on at least 6 months of the reference year. For example, for 2008 as reference year, if the company closes its accounting exercises on March 31st, it was asked to answer to the ESA's questionnaire for the accounting exercises which closed on March 31st of 2009. However, a consequent issue is that, as we sent the questionnaire in January, some companies that close their accounts afterwards do not want to answer since their accounts are not validated. 1.1. The breakdown of turnover The breakdown of turnover by different activities of the company which made it possible to ascertain its different branches4 has two main statistical uses. It enables to: - compile the sector-branch transition matrix of the national accounts comply the Prodcom regulation for the manufacturing industry calculate the main activity (MA) of the company using an algorithm. Determining the main activity was therefore based on the company's response to this survey and note merely on its declaration. In order to facilitate the answer of the companies, the questionnaires are customised by the print of the activities that the company used the year before and by the activities which are the most used by the companies with the same MA. 1.2. Common questions for all sectors The questionnaire contains only questions not already existing in tax or customs or social declarations. The aim of the survey is also to complete the statistical information. That’s why, for the employment for example, the questionnaire contains questions about the - agency's employment - non-salaried employee but the questionnaire does not contain any information about - the number of salaried employees (included in the social declarations) the salary (present in the tax declarations) etc. The core questions for all the sectors can also be divided into three main topics - employment professional incomes (questions about subcontracting for example) legal restructuring. This part is quite important for the definition of new statistical unit which are necessary to establish growth rate of aggregates (see §3 of this document). The companies have to answer questions about their partners in the legal restructuring o o o o o 4 the name of the partner his statistical ID the date of the legal restructuring the type of legal restructuring (merging, split etc.) the amount of the transaction called homogeneous production unit in the UE classification of statistical unit 2 1.3. Specifics questions for each sector A section of the questionnaire is specific to each activity sector. The principle is the same than for the common questions: the survey questionnaire cannot contain information already existing in tax or social declarations. 1.4. The consequences on data collection Since the former annual survey system was partly decentralised according to the main sectors covered (Agri-food Industry, Manufacturing and energy, Construction, Distributive Trade, Transport, Services) the data collection of this new survey is concentrated on two statistical teams. The six teams of administrators of the previous survey have been replaced by a single team from within Insee, to which a project management role has been delegated (the ministerial statistical services will continue to be the contracting authority in their sector, but will delegate to Insee responsibility for developing the global information system). In the industrial sector, matters are a little more complex because the annual statistics also include the response to the Prodcom regulation. This survey is still managed by the statistical service of the Ministry for Industry. Because of the specific questions of each sector, and the fact that the questionnaire's customizing, the Insee's staff has to control about 200 types of different questionnaires. Since a clerk cannot know each type of questionnaire, the survey staff is organized by sector, and have to execute many distinct tasks. Therefore, the first year was largely dedicated to the training of the staff, and did not permit to achieve the level of productivity required by the hierarchy. 2. The tasks of the survey staff to improve the quality of the answers The new system for the production of structural business statistics goes along with several methodological changes compared to the former one, in particular with regard to data editing. Indeed, the new data editing process puts great emphasis on selective editing, with the double objective to improve statistical quality and to reduce manual control burden. The new implemented selective editing method relies mainly on local scores, and as usual, the most delicate point is to tune thresholds allowing to determine which units have to be checked manually, and which units can be edited in an automatic way. 2.1. The principles of the selective editing used Data editing in the new system for the production of structural business statistics is based on a two-step process, which combines automatic micro-editing and selective editing. Here, the macroediting process takes place secondly, after automatic corrections have been applied to the microdata. In the first step, raw data are automatically controlled at a micro-level, by a set of classical micro-edits: for each variable, the individual plausibility of the record is checked, as well as its coherence with regard to the rest of the questionnaire. Therefore, the micro-editing process answers a double purpose: − to prepare the data for the selective editing process. Indeed, many problems occur when selective editing is directly applied to raw data: non-response phenomenon prevents from computing relevant aggregates, as well as scores of concerned units. Moreover, the presence of very large errors in raw data may disrupt the selective editing process, by bending some aggregates. The micro-editing process, by ensuring detection and imputation for very atypical records as well as non-response, permits to make up for this problem; − to quantify the quality of each record thanks to quality indicators, which will be used as diagnosis help by the survey clerks, during the manual control step of units pointed out by selective editing. 3 The second step consists thus of a selective editing process, which constitutes the cornerstone of data editing in the new system. It rests on two kinds of methods (Gros E., 2009): on the one hand, “drop-out” methods, using score functions measuring the impact of each unit on a given ratio, and on the other hand “diff” methods, using score functions measuring the weighted difference between the raw value of a variable given on the questionnaire and an expected value of this variable. Each method is applied on micro-edited data, and concerns respondents as well as partial respondents. Total non-respondents are not checked by selective editing and are subject to a specific follow-up procedure. 2.2. The follow up to complete answers Before the control of the answer as detailed above, the clerks have to follow up some companies to: - - obtain the answer for a list of very important companies. The very important size and economic burden of this company does not permit us to impute their answer. In the 2008 survey, among the 1500 companies whose answer was considered as compulsory, answer was of obtained for more than 1450. Three hundred had had to be recalled. complete the answer of the companies. The principal variable concerned was the breakdown of the turnover. As mentioned previously, this variable is one of the most important variables of the system, especially since the sector-based statistics will use it. Enterprises are asked to fill the lines concerning the turnover coming from the wholesale of predefined activities but may also fill a line giving the possibility of filling the turnover of an activity which is not in the predefined list. In this case, the enterprise gives the amount of turnover relative to this activity, and writes on the questionnaire the “name” of the activity. If the amount of turnover exceeds a threshold the clerks have to find the corresponding code (of the French nomenclature NAF), otherwise the corresponding code will be inferred by the statistical office. This issue was underrated for the first survey campaign, during which the clerks have treated more than 23 000 businesses. A mass processing has been set up for the first year in order to treat more quickly about 15 000 answers without any recall. Nevertheless, the survey staff had to recall more than 1000 companies to find a corresponding code. For the next year, the number of manual processing will be reduced by using the SICORE software, the Insee's software for automatic coding updated for our survey. - - confirm the breakdown of turnover when it leads to a change of their principal activity code (APE code) compared to the value of the register. This year, about 15 000 businesses were controlled for this item and generated about 2000 phone calls. complete the part of the questionnaire which concerned the legal restructuring. Clerks has to obtain all the partner’s information we need. This information will be sent to the statistic register which constitutes new statistical units (see on §3) For this job, the clerks can consult legal source or recall the companies. About 6000 companies were checked for this work and clerks recalled about 1000 companies. 2.3. The follow up to control answers Also, for a given characteristic of interest and a given level of validation, the joint use of two local “drop-out” and a local “diff” score allows to organize controls into a hierarchy. However, since units – i.e. questionnaires – need to be treated on a “unit by unit” basis, and not item by item, the results of the local scores are synthesized into a global priority indicator, according to a threestep procedure: 4 − firstly, for each variable and each local score, two thresholds, a “high” threshold and a “medium” threshold, permit to divide the whole set of units into three groups: very influential units, moderately influential units and non influential units; − then, the status of each variable is defined as the “maximum status” of the different local scores relating to this variable. So, the status S(Xi) of a given variable Xi is defined as I if the unit is very influential for at least one local score, at S if the unit is only moderately influential for at least one local score, and at O otherwise; − lastly, the global priority indicator is defined as where A represents the importance attached to the “very influential” status compared with the “moderately influential” status, and Ki represents the importance of each variable. Eventually, the whole set of units is divided into four roughly equal sized groups, according to the value of their global priority indicator: priority units if GPI>α, important units if α≥GPI>β, secondary units if β≥GPI≥γ and units which may be edited in an automatic way if γ≥GPI4. Priority units are checked manually first, then important units and last secondary units, according to available time and means. This mechanism permits to manage the amount of work during the campaign, and thus to respect practical constraints while ensuring a good level of quality for statistics. For the first campaign, only the turnover and its breakdown were controlled this way. Because of delays, the survey staff was not able to validate the other characteristics of the questionnaire. To the selective editing, the level of the aggregation was the first three position of the APE. Therefore, if the score exceeded a threshold of 1% of the total of his sector (companies with the same first three positions on their APE), the answer of the companies had to be controlled. About 8000 companies were controlled by survey staff and it generated about 1500 phone calls. 3. The particular processing of the companies which take part in a legal restructuring 3.1. Example Let us take the example of a merging because it's the most frequently legal restructuring in France. N-1 400 K€ N Company 4 APE : sector B market 100 K€ 1 500 K€ Company 14 APE : Sector A market Company 1 : 1000 K€ APE sector A Figure 1: example of merging 5 In this example, the legal restructuring concerns 3 companies. This restructuring is also composed from two couples of companies: - the company 4 (called the grantor) which yields his fixed tangible assets to the company 14 (called the grantee) the company 1 which yields his fixed tangible assets to the company 14 (called the grantee) In the ESA’s questionnaire, company 14 has to give us the description of his two partners (the company 4 and 1). The data of this couple of companies are dumped to the statistical register (called CITRUS) which centralizes all the information about the legal restructuring. The main goal of this register is to create new statistical unit (called envelope) from the couple of companies that it received from different statistical sources. 3.2. Definition of the restructuring envelope The definition of the envelope bordering5 is managed by CITRUS. The restructuring envelope includes the companies which participate to the restructuring for the current year and the year before. In the previous example, the envelope contained companies 1 and 4 for the year N-1 and the company 1 for the year N. To constitute the envelop CITRUS has a principal rule. One company belongs to one and only one envelope for a given year. An envelope can also contain many companies, and some of them can be unrelated the one to the others. Company A can exchange tangible assets with B, and B with C: the envelope will contain companies A, B and C even if there is no link between A and C. The envelope is considered as a statistical unit of which main activity (MA) is calculated from the APE and the turnover of the constituting companies of the current year. The envelope has the same MA for both years (N-1 and N). We therefore avoid too strong sector evolutions. CITRUS calculates the main characteristics of the envelope (MA, size, aggregate coefficient6). 3.3. The use of the envelope for the survey A questionnaire is created for this envelope as follows: - The value of a characteristic X in year n of the envelope is obtained by adding the values of the companies constituting the envelope in N XN X N i ienv N - The value in N-1 is obtained by adding the values of the companies constituting the envelope in N-1 to which we remove the flow intra-envelope generated by the restructuring if it exists and it is known. When the flow intra-envelope is unknown, it is also possible to weight the sum of X values of the companies that compose the envelope N-1 by the coefficient called ‘aggregation coefficient’. By agreement, the flow intraenvelope is removed in N-1. So if this flow intra-envelope appears in N, it must be added in N-1, the flow intra-envelope is negative. If we know the flow intra-envelope X N 1 X ienv N 1 N 1 i F where F is the Flow intra-envelope. 5 6 List of companies in n and n-1 Aggregation coefficient= (turnovern /value addedn)/(turnovern-1/added valuen -1) 6 If we do not know the flow intra-envelope X N 1 K * X ienv N 1 N 1 i where K is the aggregate coefficient A characteristic is considered as additive if its value is independent of the legal restructuring in short terms (e.g. added value). The flow intra-envelope is null for this characteristic. A characteristic is considered as additive as non additive if the restructuring has an immediate impact without any apparent economic change (e.g. turnover): restructuring can indeed generate and increase or a decrease (called flow intra-envelope) of this variable. This flow intra-envelope is not associated to an economic reality by merely due to a change in juridical structure. In our example (Figure 1): - for the year N: the envelope’s turnover is the turnover of the company 14 which is the only company which belongs to the envelope for this year. The turnover value is 1500 K€ - For the year N-1: the envelope’s turnover is the sum of the turnover of the companies 1 and 4 minus the values of the flow intra-envelope. The turnover value is: 500 (turnover of 4) + 1000 (turnover of 1) – 100 (flow intra-envelope) = 1400 K€. In the figure 1, we can see the flow intra-envelope which is shown with the red arrow. 3.4. The clerk’s tasks for checking the envelopes characteristics The envelopes participate to the selective editing process but scores are only calculated for the temporal drop out. If the envelope has to be checked by the clerks, it reflects that its turnover evolution between N and N-1 is atypical. This is generally due to the flow intra-envelope, but there are no question about the flow intra-envelope in the survey. In this case, the clerk has to recall the bigger company of the envelope in order to obtain an estimation of the turnover flow intraenvelope, and if doable, an estimation of the breakdown of this flow intra-envelope by activities. 4. The rules to merge the survey data with the available tax and employment data 4.1. The definition of the frame of reference The French business register SIRENE is used to define the frame of reference of the system. Since all French legal units have to be registered within it (for example to obtain a loan from a bank). Since SIRENE is an inter-administrative register whose id-number’s has to be used by all administrations, this register offers an exhaustive coverage of the field of legal units. The universal use of the id-number makes the merging of different files easy. However, the register has not to be considered as a base to produce directly statistics. For example, the number of active enterprises for a given economic sector will not be obtained directly from SIRENE, because some units stopped their activity but did not yet notify it to the register. It will result from specific estimates using the different components of the system, especially the statistical survey. That's why a statistical register (called OCSANE) was specially built for the structural statistics production. This register contains all the companies which belong to the 7 structural statistical field7 and for whom we are waiting for information (tax, employment, surveys etc.). The business register has to be considered as the backbone of the system. It may happen that in some sources, some units are missing, or existing as two records (for example in case of multiple tax declarations for the same enterprise). It is by using the id-number of the register that these cases will be settled (Chami S. 2010). Employment data available Statistical Frame ESA's sample ESA's respondant ESA ' sampling frame Tax data available Figure 2: The definition of the different populations of statistical or administrative sources The OCSANE's population which is represented by the grey form. It represent the statistical frame of our system. The ESA's sampling frame (in purple color) which does not correspond exactly to the population of OCSANE, since some activities do not belong to the survey but are necessary for the national accounts (the sports activities for example). The ESA's sample (in pink) The ESA's respondents (in yellow). The total non-response correction in ESA will call on weighting methods and use Calibration techniques (Deville, Särndal, 1992) lead to adjust the weights taking into account calibration equations. These equations are defined using the classifying of every enterprise within the register and the tax turnover. The tax data available (in red). The total non-response correction will call on imputing methods. The employment data available (in blue).There is no treatment of the total non-response For each population, the level of information that we have at our disposal is different. For the ESA's respondents for example we have the tax, employment and survey data. For the other population we only have tax and / or employment data. 7 For example, the companies from the financial sector do not belong to the structural statistical field; therefore even if we obtain data from tax for these businesses they will not interest us. 8 4.2. The rules to merge data Thanks to the register we can merge all the data collected for a statistical ID. However, we have to check that the different data correspond to the same statistical unit and to the same reference's period. Between the three main sources of information for a company (survey data, tax data employment) there are common characteristics which permit to make this control and to merge all the information available for a company as the following figure 3 shown. The product process whose the goal is to merge the data is called REDI. … Turnover Goods sales Products sales Services sales … … … Turnover Goods sales Products sales Services sales …. Salary Staff size … Surveys' data8 Tax data Definitive turnover Definitive sales Definitive Salary Definitive Staff size … …. Salary Staff size … Employment data Final Data Figure 3 : common characteristics between the three main sources For the companies which answered to the survey (in yellow in the figure 2) we merge the 3 sources. For the other companies of the statistical referential (in grey and pink in the figure 2), we only merged the tax and employment data. The principle of the merging is as follows: - For each common characteristic, a major source is defined. Table 1: The definition of the major source for each common characteristic Common characteristic Condition major source Turnover We have a tax data for the company Tax We have no tax data for the company Survey9 Sales We have a answer in the survey for the year of Survey reference We have no answer in the survey for the year of Tax reference Salary We have a tax data for the company Tax 8 The sales (goods, services and products) are estimated in the survey by using the breakdown of turnover by activities. The goods sales are the sum of the turnover of the trade's activities, the services sales are the sum of the turnover of the service's activities 9 In this case, the turnover of the survey will be used to impute the tax data for the company 9 Staff Size - We have no tax data for the company Employment We have a employment data for the company Employment We have no employment data for the company Tax For each common characteristic, we calculate the difference between the two sources. Then we calculate a score which will permit us to determine the companies that the clerks are going to check. score X s1 X s 2 T(X p) X S 1 value of the characteristic X in the source 1 X value of the characteristic X in the source 2 S2 where T ( X p ) total of the characteristic X in the major source at the level of aggregation used for the control - If the score is below the threshold, the final value is the one from the major source - If the score is above the threshold, then it is a clerk which has to determine the good values. He has to determine linked characteristics too. For example, if he changes the goods sales, he has to check that the goods purchases stay consistent with the new values of the sales. Otherwise, he has to adjust the purchases. 4.3. The consequences on the other data As we havejust noticed, the common characteristics are often linked with other characteristics in the different sources (the purchase and the turnover for the tax data, the turnover and the values of the subcontracting in the surveys etc...). This is the reason why, when the final value of the common characteristics are defined by the process REDI, this value has to be reintroduced in the original sources (survey, tax and employment data). The characteristics from each source which are correlated with common characteristic are calculated again to conserve the consistency between the values within a source. Besides, in the surveys, the turnover is often used to process the partial nonresponse. So this process of automatic correction has to be rerun using the final values. Conclusion In order to reduce the statistic burden for the companies, the annual survey was lightened thanks to a systematic use of administration sources. Therefore, statistics obtained through the new system derive from different kinds of information : - some obtained directly from administrative sources ; - some using only the variables of the statistical survey ; - many of them will combine survey data and administrative data, especially for the sector-based estimations. The raw material to produce these statistics is a non rectangular table: some data are exhaustive (those coming from the administrative sources), other not (those coming from the statistical survey). In order to obtain the most exhaustive information for a company, we have to merge these different sources. Besides, a new estimator (Brion P. 2008) which combine administrative and survey data has been implemented to calculate the characteristics aggregate. 10 Finally although the data of the three main sources (survey, tax and employment data) can be separately controlled and validated, we can not spread the results of one source without the other sources. This is a new constraint but it enable to have single information of better quality. References: Brion Ph., “The future system of French structural business statistics: the role of the estimates”, UN/ECE Work Session on Statistical Data Editing, Vienna, 2008. Chami S., “Reengineering French structural business statistics: an extended use of administrative data”, work session of the Q2010 conference in Helsinki Depoutot R., “Reengineering French structural business statistics: an owerview”, work session of the Q2010 conference in Helsinki Deville J.-C., Särndal C.-E. (1992), “Calibration estimators in survey sampling”, Journal of the American Statistical Association, 87, pp. 376-382 Gros E., “Setting cut off scores for selective editing in structural business statistics : an automatic procedure using simulations study” , UN/ECE work session of the conference of European statistician, Neuchâtel 2009 Insee, “Redesigning French structural business statistics: how can the response burden on companies be lessened”, ECE/CES/209/35 Work Session on Statistical Data Editing, Geneva 2009 11