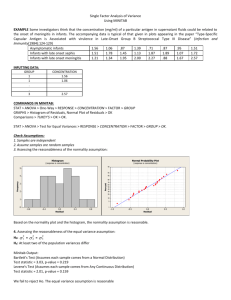
Unit 1 Descriptive Statistics & Basic Probability
advertisement

2/5/2016
Math 131
Table of Contents
Math 131 Notes
Math 131 Notes .............................................................................................................................................. 1
Unit 1 Descriptive Statistics & Basic Probability ....................................................................................... 1
Chapter 1: Introduction ....................................................................................................................... 1
Section 1.1: Overview of Statistics (p 2) .................................................................................... 1
Section 1.2: Data Classification (p 8) ......................................................................................... 1
Section 1.3 Experimental Design (p 15) ..................................................................................... 1
Generating random numbers in Minitab ............................................................................. 2
Sorting numbers in Minitab (Manual p 11) ........................................................................ 2
Using Minitab to select a random sample from a dataset stored in columns ...................... 2
Generating a Sequential set of numbers in Minitab and then selecting randomly from them
(Manual p 8) ....................................................................................................................... 2
Chapter 2: Descriptive Statistics ......................................................................................................... 2
Section 2.1 Frequency Distributions and their Graphs (p 32) ..................................................... 2
Constructing a Histogram in Minitab (Manual p 37) .......................................................... 3
Construction a Frequency Polygon in Minitab (Manual p 51) ........................................... 4
Constructing an Ogive in Minitab (Manual p 54) ............................................................... 4
Section 2.2 More Graphs and Displays (p 46) ............................................................................ 5
Constructing a stem-and-leaf chart in Minitab (Manual p 45) ............................................ 6
Constructing a Pie Chart in Minitab(Manual p 25)............................................................. 7
Constructing a Pareto (Bar) Chart in Minitab (Manual p 15) ............................................. 9
Section 2.3 Measures of Central Tendency (p 57) .....................................................................10
Finding Measures of Central Tendency in Minitab (Manual p 67)....................................11
Using Minitab to Obtain Frequency of Individual Variables .............................................11
Section 2.4 Measures of Variation (p 70) ..................................................................................11
Finding Measures of Variation in Minitab .........................................................................12
Section 2.5 Measures of Position (p 87) ....................................................................................12
Finding Quartiles in Minitab (Manual p 88) ......................................................................13
Constructing a Boxplot in Minitab (Manual p 90) .............................................................15
Using Minitab to Compute z-scores (Manual p 86) ...........................................................16
Chapter 3 Probability (p 109) ............................................................................................................16
Section 3.1 Basic Concepts of Probability .................................................................................16
Unit 2 Probability & Probability Distributions ..........................................................................................18
Section 3.2 Conditional Probability and the Multiplication Rule (p 121) .................................18
Section 3.3 The Addition Rule ..................................................................................................18
Simulating the Birthday Problem in Minitab .....................................................................19
Section 3.4 Counting Principles (p 140) ....................................................................................19
Chapter 4 Discrete Probability Distributions (p 161) ........................................................................21
Section 4.1 Probability Distributions (p 162) ............................................................................21
Section 4.2 Binomial Distributions (p 174) ...............................................................................22
Constructing a binomial Distribution using Minitab (Manual p 128) ................................25
Chapter 5 Normal Probability Distributions (p 205) .........................................................................26
Section 5.1 Introduction to Normal Distributions (p 206) .........................................................26
Section 5.2 The Standard Normal Distribution (p 214) .............................................................26
Section 5.3 Normal Distributions: Finding Probabilities ...........................................................26
Using Minitab to find the probability that a normally distributed random variable is less
than a specified value (Manual p 157) ...............................................................................28
Using Minitab to find the probability that a normally distributed random variable is
between two specified values (Manual p 159) ...................................................................28
Section 5.4 Normal Distributions: Finding Values (p 229) .......................................................28
Section 5.5 The Central Limit Theorem (p 238) ........................................................................29
1
2/5/2016
Math 131
Table of Contents
Section 5.6 Normal Approximations to Binomial Distributions (p 251) ...................................30
Unit 3 Inferential Statistics ........................................................................................................................32
Chapter 6 Confidence Intervals (p 269) .............................................................................................32
Section 6.1 Confidence Intervals for the Mean (Large Samples) ..............................................32
Using Minitab to find the Confidence Interval with a Sample in a Column for a Normal
Distribution (Manual p 183) ..............................................................................................33
Using Minitab to find the Confidence Interval with Summarized Data for a Normal
Distribution ........................................................................................................................34
Determining Sample Size (p 276) ..............................................................................................34
Section 6.2 Confidence Intervals for the Mean (Small Samples) (p 284)..................................34
Summary of when the normal distribution or the t-distribution can be used (p 288) ................35
Using Minitab to find the Confidence Interval for a t-Distribution with the Sample in a
Column (Manual p 193).....................................................................................................35
Using Minitab to find the Confidence Interval with Summarized Data for a t-Distribution
...........................................................................................................................................36
Section 6.3 Confidence Intervals for Population Proportions (p 293) .......................................36
Chapter 7 Hypothesis Testing with One Sample ...............................................................................37
Section 7.1 Introduction to Hypothesis Testing (p 321) ............................................................37
Alternative Hypothesis ..................................................................................................................39
Area of Normal Curve ...................................................................................................................39
Section 7.2 Hypothesis Testing for the Mean (Large Samples) (p 334) ....................................39
Using Minitab for Hypothesis testing for the mean with summarized data from a large
sample ................................................................................................................................40
Section 7.3 Hypothesis Testing for the Mean (Small Samples) (p 350) ....................................41
Using Minitab to perform Hypothesis testing for the mean with summarized data when
the sample is small (Manual p 211) ...................................................................................41
Section 7.4 Hypothesis Testing for Proportions (p 360) ............................................................42
Using Minitab to perform Hypothesis testing for a proportion with summarized data
(Manual p 215) ..................................................................................................................42
Chapter 9 Correlation and Regression ...............................................................................................43
Section 9.1 Correlation (p 442) .................................................................................................43
Using Minitab to draw a scatter plot (Manual p 93) ..........................................................43
Using Minitab to find the Correlation Coefficient (Manual p 95) .....................................45
Using Minitab to determine whether the correlation coefficient is significant (Manual, p
95) ......................................................................................................................................46
Section 9.2 Linear Regression (p 458).......................................................................................46
Using Minitab to find the Least Squares Regression Equation (p 98) ...............................47
Using Minitab to find the Regression equation and a predicted value for the Old Faithful
Data (p 460) .......................................................................................................................48
Using Minitab to draw the least squares regression line on the scatter plot for the Old
Faithful Data ......................................................................................................................49
Chapter 10 Chi-Square Tests and the F-Distribution (p 493) ............................................................49
Section 10.1 Goodness of Fit .....................................................................................................49
Using Minitab to perform the Chi-Square Goodness-of-Fit Test (Manual p 237) .............50
Chi-Square with M&M’s ...........................................................................................................51
Section 10.2 Independence (p 504)............................................................................................52
Using Minitab to perform the Chi-Square Independence Test (Manual p 242) .................54
2
2/5/2016
Math 131
Unit 1
Unit 1 Descriptive Statistics & Basic Probability
Chapter 1: Introduction
Section 1.1: Overview of Statistics (p 2)
Data consists of information coming from observations, counts, measurements, or responses. The
singular of data is datum. (p 2)
Statistics is the science of collection, organizing, analyzing and interpreting data in order to make
decisions. (p 3)
A population is a collection of all outcomes, responses, measurements, or counts that are of
interest. (p 3)
A sample is a subset of a population characteristic (p 3)
A parameter is a numerical description of a population (p 4)
A statistic is a numerical description of a sample characteristic (p 4)
Descriptive Statistics is the branch of statistics that involves the organization, summarization, and
display of data. (p 5)
Inferential statistics is the branch of statistics that involves using a sample to draw conclusions
about a population. A basic tool in the study of inferential statistics is probability (p 5).
Section 1.2: Data Classification (p 8)
Qualitative data consist of attributes, labels, or nonnumerical entries. (p 8)
Quantitative data consist of numerical entries or counts.
Nominal level of measurement: qualitative (p 9)
Ordinal level of measurement: qualitative or quantitative, can be ordered, but differences are not
meaningful
Interval level of measurement: quantitative, can be ordered, differences are meaningful, no
inherent zero (e.g. 0 degrees) (p 10)
Ratio level of measurement: quantitative, can be ordered, differences are meaningful, inherent
zero (e.g. 0 dollars)
Section 1.3 Experimental Design (p 15)
Guidelines for designing a statistical study (p 15)
1. Identify the variable(s) of interest (the focus) and the population of study.
2. Develop a detailed plan for collecting data. If you use a sample, make sure it is representative.
3. Collect the data
4. Describe the data using descriptive techniques.
5. Interpret the data and make decisions about the population using inferential statistics.
6. Identify any possible errors.
Data can be collected as follows (p 15-16)
Census: A count or measure of the entire population
Sampling: A count or measure of part of the population
Simulation: Using a mathematical or physical model
Experiment: A treatment is applied to part of a population and responses are observed. A second
part of the population is often used as a control group and given no treatment or a placebo
Sampling techniques: (p 17-19)
Random sample: Select the sample randomly from the entire population
Stratified sample: break population into subsets called strata (e.g. ethnicity) and take random
samples from each strata.
1
2/5/2016
Math 131
Unit 1
Cluster sample: break population into groups called clusters (e.g. zip codes) then randomly select
clusters and select all the members of the each cluster.
Systematic sample: Assign a number to each member of the population, randomly pick a number,
then start with that number and choose at the same interval from it.
A convenience sample is not reliable!
Generating random numbers in Minitab
Calc->Random Data->Integer, Generate Enter number of random numbers (e.g. sample size), Store in
column(s), C1, Minimum of: 1, Maximum of Population Size
Note, this way of generating random numbers can give repeats. Also, this method is not described in the
Minitab Manual. An easy way to eliminate repeats is to sort the numbers so that the repeats appear
sequentially, then delete the repeats.
Sorting numbers in Minitab (Manual p 11)
To sort data: Data->Sort, Select the column to sort, choose By Column (usually the same as the one to
sort) choose where to Store sorted data in (usually original column)
Using Minitab to select a random sample from a dataset stored in columns
Calc->Random Data->Sample from columns. Sample sample size (e.g. 40) from column(s). Select the
columns the data are stored in (e.g. C1 C2 C3). Store samples in (Usually just overwrite the original
columns, e.g. C1 C2 C3). Click OK
Note that the default way of sampling from columns in Minitab is without replacement. The dialog box
allows you to choose Sample with replacement, but we usually do not what this.
Generating a Sequential set of numbers in Minitab and then selecting randomly from
them (Manual p 8)
To generate a sequential number for each member of the population and store in C1
Calc->Make Patterned Data->Simple Set of Numbers. Choose Store patterned data in C1. From the
first value 1 To last value Population Size In steps of 1. Click OK.
To select numbers randomly from these numbers
Calc->Random Data->Sample from columns, Sample number of rows from column(s) C1, Store
samples in C2. Click OK.
Chapter 2: Descriptive Statistics
Section 2.1 Frequency Distributions and their Graphs (p 32)
A frequency distribution is a table that shows classes or intervals of data entries with a count of the
number of entries in each class. The frequency, f, of a class is the number of data entries in the class.
Midpoint of a class = (Lower limit + upper limit)/2
Relative frequency = class count/sample size
Cumulative frequency = (sum of frequencies for class and all previous)
Guidelines for Constructing a Frequency Distribution form a Data Set (p 32)
Decide the number of classes. To detect patterns, this should be between 5 and 20
Find the width of each class by dividing the range by the number of classes and rounding up
Find the class limits. The minimum entry can be the lower limit. To find the remaining lower limits add the
width to the lower limit of the preceding class
Make a tally mark for each data entry in the fow of the appropriate class
Count the tallies for the frequency in each class
2
2/5/2016
Math 131
Unit 1
The following are techniques for representing quantitative data:
A frequency histogram is a bar graph that represents the frequency distribution of the data set.
A frequency polygon is a line graph that represents the frequency distribution of the data set.
A relative frequency histogram is similar to a frequency histogram except that it plots relative
frequencies (i.e. portion or percent of data that falls in each class) (p 34).
A ogive is a cumulative frequency graph (i.e. the frequency of succeeding classes are added up) (p
39)
A Stem-and-Leaf –Plot is a plot in which each number is represented as a stem (e.g. leftmost
digits) and a leaf (eg. the rightmost digit) (p 46)
Using the Internet Usage data on p 33 for one example, we will create some of these graphs. First we will
sort the data using Minitab.
Place the Usage data in column C1 of a new Worksheet then sort the data to make it easier to find
frequencies in each class.
Data -> Sort -> Sort column C1 by Column C1. Choose Store sorted data in original column.
InterUse
7,7,11,17,17,18,19,20,21,22,23,28,29,29,30,30,31,31,33,34,36,37,39,39,39,40,41,41,42,44,44,46
50,51,53,54,54,56,56,56,59,62,67,69,72,73,77,78,80,88
Divide the range by the number of classes:
88 7 81
11.57 . Rounding up give a class width of 12
7
7
This gives boundaries of 7,19, 31, 43, 55, 67, 79, 91
NOTE: We will have the classes running from 7 to 19, etc where the upper bound is exclusive, ie it does
not include 19
Class
Freq
Rel freq
Cum freq
Cum rel freq
7 -19
6
0.12
6
0.12
19 - 31
10
0.20
16
0.32
31 -43
13
0.26
29
0.58
43 - 55
8
0.16
37
0.74
55 - 67
5
0.10
42
0.84
67 - 79
6
0.12
48
0.96
79 - 91
2
0.04
50
1.00
We can now use the Freq or the Rel freq column to construct our histogram. We can label the x-axis with
either the class boundaries 7, 19, 31, 43, 55, 67, 79, 91 or the class midpoints, 13, 25, 37, 49, 61, 73, 85.
Note the first class midpoint = (7 + 19)/2 = 13, and the rest can be obtained by adding 12. The histograms
are similar to those of the text on page 36 except that the boundaries 6.5, 18.5, 30.5, etc and the midpoints
are 12.5, 24.5, 36.5 etc.
Constructing a Histogram in Minitab (Manual p 37)
Graph->Histogram Select Simple from the Histogram Dialog Box, Click OK, Select the Column in the
Simple Histogram Dialog Box, Click on Scale and under the tab Y-scale Type, choose either Frequency
or Percent, click Labels and under the Data Labels tab, click use y-value labels, click OK, OK.
(Minitab includes a default title, but you can click on Labels in the Simple Histogram Dialog Box to enter
your own title)
The histogram should be modified to include our breakpoints and bins. Place the cursor near the X-axis so
that the screen tip says X-scale and then Right click and choose Edit X Scale. Under the Binning tab
choose Cutpoint and under Interval Definition set number of intervals to 7. (Note that Minitab chooses 9
as the default for this data, but we set to 7 as specified in the text).
The following is the frequency histogram plotted by Minitab for the Internet Usage data on p 33.
3
2/5/2016
Math 131
Unit 1
Histogram of InterUse
12
12
10
Frequency
10
8
7
7
6
6
4
4
4
2
0
7.00000000
1.8571E+01
3.0143E+01
4.1714E+01
5.3286E+01
InterUse
6.4857E+01
7.6429E+01
8.8000E+01
Note that Minitab uses the exact value of 81/7 to find the class boundaries.
Construction a Frequency Polygon in Minitab (Manual p 51)
Graph -> Histogram -> Simple, choose the column. To make a polygon instead of a histogram, click on
the Data view button. On the Data Display tab, remove check mark from Bars and place check mark on
Symbols. Under the Smoother Tab, choose Lowess for Smoother, make the Degree of smoothing 0 and
the Number of steps 1. Then click OK twice.
The polygon should be modified to include our breakpoints and bins. Right click on the X-axis and choose
Edit X Scale. Under the Binning tab choose Cutpoint and under Interval Definition set number of
intervals to 7.
The results for the Internet Usage Data on p 33 are:
Histogram of InterUse
12
12
10
Frequency
10
8
7
7
6
6
4
4
4
2
0
7.00000000
1.8571E+01
3.0143E+01
4.1714E+01
5.3286E+01
InterUse
6.4857E+01
7.6429E+01
8.8000E+01
Constructing an Ogive in Minitab (Manual p 54)
We will construct an Ogive with the data on internet usage presented in the text on p 33. We will make the
classes go from 7 to 19 exclusive, etc, instead of 6.5 to 18.5 etc as the book does to make it a little easier.
4
2/5/2016
Math 131
Unit 1
Minitab doesn’t have an automatic ogive function. All it can do is plot the class limits and the cumulative
frequencies. So the procedure is to do all the calculations ourselves, enter them in Minitab and tell Minitab
to plot them.
To use Minitab to plot the Ogive, in a new worksheet make the Upper Class Boundaries column C1 and the
Cum rel freq column C2. Then proceed as follows:
Then select Graph -> Scatterplot -> With Connect Line. Select C2 for the Y-variable and C1 for the Xvariable. Click on the Data View button and be sure that both Symbols and Connect line are selected. By
choosing both Symbol and Connect line, Minitab will connect the dots at each data point on the graph.
Click on Labels and title the ogive ‘Ogive of Internet Usage in Minutes’. To label the points click the Data
labels tab and choose use y-value labels. Click OK After the graph is created, it should be edited to show
each upper class limits. Right-click on the X-axis of the graph and select Edit X scale. Enter the Position
of ticks as 19: 91/12. This tells Minitab that the tick marks should go from 19 to 91 in steps of 12. (We
could have made it 7: 91/12 but this would indicate that 7
The results are:
Ogive of Internet Usage in Minutes
1.0
0.96
1.00
0.84
Cum Rel Freq
0.8
0.74
0.58
0.6
0.4
0.32
0.2
0.0
0.12
0.00
7
19
31
43
55
Class Boundaries
67
79
91
Section 2.2 More Graphs and Displays (p 46)
Section 2.1 discussed traditional ways to display quantitative data. A stem-and-leaf plot is a newer way. In
a stem-and-leaf plot, each number is separated into a stem (e.g. the leftmost digits) and a leaf (e.g. the
rightmost digit). Two advantages of the stem-and-leaf plot are that it provides an easy way to sort the data
and the graph contains the original data.
The following table shows the stem leaf plot for the first row of data on page 46 in the text. The leaf is the
last digit of each number and the stem is the first two digits:
Stem
10
11
Leaf
5
64
5
2/5/2016
12
13
14
15
Math 131
Unit 1
96
0
45
59
The stem-and-leaf plot can also have two entries for each stem, one for leaves from 0 to 4 and the other for
leaves from 5 to 9. (p 47) This increases the refinement of the graph.
Constructing a stem-and-leaf chart in Minitab (Manual p 45)
Graph->Stem-and-Leaf->Select the Column, click OK
Minitab presents an ordered stem-and-leaf plot. The results are presented as follows:
First, the number of items and the Leaf Unit is given. The Leaf Unit is explained below.
Then the stem-and-leaf-plot is presented:
The first column is the cumulative number of data points in the row starting at the first row and
going to the row below the median. The first column for the row containing the median has the
number of points in that row. Starting in the last row the first column is the cumulative number of
data points going down to the row above the median.
The second column is the stem. There may be several rows for a stem, the first for lower valued
leaves, etc. The stem value is multiplied by 10 times the Leaf Unit.
The third column contains the leaf values. The leaf values may be actual values or they may be
truncated. The leaf values are multiplied by the Leaf Unit, so that if the Leaf Unit is 1, the leaf
values represent actual values (e.g. if the Leaf Stem is 1, a stem value of 3 and a leaf value of 7
indicates an actual value of 37).
For example the following data
100, 120, 140, 145, 179, 190, 200
The results are:
Stem-and-leaf of C1
Leaf Unit = 10
1
2
(2)
3
2
1
1
1
1
1
1
2
N
= 7
In this example the Leaf Unit is 10, so that the leafs
are multiplied by 10 and the stems are multiplied by
100. E.g. 120 = 100*1 + 10*2 (the second row).
0
2
44
7
9
0
The median is 142.5 so the row representing 140
and 145 is the median row, indicated by the
parenthesis.
The numbers 145 and 179 are truncated, e.g. 179 is
represented by 100*1 + 10*7 = 170.
Another example:
145, 179, 190, 200, 350, 380, 400, 555, 700, 900
Stem-and-leaf of C1
Leaf Unit = 10
3
4
(2)
4
3
2
1
2
3
4
5
6
N
= 10
Note that stem values 6 and 8 have no leaves ,
indicating that there are no such values.
479
0
58
0
5
6
2/5/2016
2
1
1
7
8
9
Math 131
Unit 1
0
0
Another example:
900, 1234, 1468, 5432, 5789, 7777, 8500, 9765
is presented as follows:
Stem-and-leaf of C1 N = 8
Leaf Unit = 1000
3
3
(2)
3
2
0
0
0
0
0
011
55
7
89
The first value, 900, is represented by the
first 0 in the leaf column. Since the stem is 0
the first value is 0*1000 = 0. The second
value, 1234, is represented by the first 1 in
the leaf column. So the second value is
1*1000 = 1000. The 0 in the Stem column
indicates that it does not change the value of
the data point
Two common techniques for graphing qualitative data are pie charts and pareto (bar) charts.
A pie chart is a convenient way of showing qualitative data. A pie chart is a circle with slices proportional
to the relative frequency of each category.
Constructing a Pie Chart in Minitab(Manual p 25)
Method 1: Used when we have a categorical variable specified in each row of a column, e.g.
Grades
A
A
A
B
B
C
To graph the frequency of a categorical variable (note Manual does not describe this technique):
Graph->Pie Chart Choose Chart Raw Data, Click on Labels choose the Slice Labels tab and click
Category name (you can also click Frequency and/or Percent) (You can also click on the Titles/Footnotes
tab and enter a different title from the Minitab default), click OK, OK
The results are:
7
2/5/2016
Math 131
Unit 1
Pie Chart of Grades
Category
A
B
C
C
1, 16.7%
A
3, 50.0%
B
2, 33.3%
To graph variable based on another categorical variable: (Manual p 25)
Eg for the following data from p 50 of the text:
Causes of Shrinkage
Employee Theft
Shoplifting
Administrative Error
Vendor Fraud
$million
15.6
14.7
7.8
2.9
Graph->Pie Chart, click on Choose values from a table, Choose the Categorical variable (C1 Causes of
Shrinkage) and the Summary variable (C2 $million), Click on Labels choose the Slice Labels tab and
click Category name (you can also click Frequency and/or Percent), click OK OK
The results are
8
2/5/2016
Math 131
Unit 1
Pie Chart of $million vs Causes of Shrinkage
Category
Employ ee Theft
Shoplifting
Administrativ e Error
Vendor Fraud
Vendor Fraud
2.9, 7.1%
Administrativ e Error
7.8, 19.0%
Employ ee Theft
15.6, 38.0%
Shoplifting
14.7, 35.9%
A pareto chart (or bar chart?) is another way of showing qualitative data. A pareto chart is a graph in
which the categories are plotted horizontally and the frequencies are plotted vertically.
Constructing a Pareto (Bar) Chart in Minitab (Manual p 15)
We will use the Grades example for the first technique.
To graph the frequency of a categorical variable:
Graph->Bar Chart, for Bars represent choose Counts of unique values, choose Simple Table, choose
variable to graph (C1 Grades), click OK
Chart of Grades
3.0
2.5
Count
2.0
1.5
1.0
0.5
0.0
A
B
Grades
C
Next we want to choose a graph variable based on a categorical variable. (Manual p 17) We will use the
same example as we used for the Pie Chart (“Causes of Inventory Shrinkage” form the text, p 50).
9
2/5/2016
Math 131
Unit 1
Graph->Bar Chart, for Bars represent choose Values from a table, choose Simple Table click OK,
choose the Graph Variable ($million) and the Categorical Variable (Causes of Shrinkage), To place the
values above the bars, click Labels, choose the Data Labels tab and choose Use y-value labels, click OK,
OK
Chart of $million vs Causes of Shrinkage
15.6
16
14.7
14
12
$million
10
7.8
8
6
4
2.9
2
0
Employee Theft
Shoplifting
Administrative Error
Causes of Shrinkage
Vendor Fraud
Section 2.3 Measures of Central Tendency (p 57)
Population Mean:
x
. The population mean is called the expected value:
N
N
E ( X ) xi p( xi ) . If each element has the same probability of being selected, p( xi )
i 1
x
n
Sample Mean: x
Median: Middle element
Mode: The entry that occurs the greatest number of times, if there is one.
The weighted mean is the mean of a dataset whose entries have varying weights:
x w
w
Usually w 1, so that x x w .
x
For example, for this course the final grade = 0.2*lab + 0.2*test1 + 0.3*test2 + 0.3*test3.
An estimate of the mean can be obtained from the frequency distribution as follows:
x
( x f )
n
where x is the midpoint and f is the frequency of a class. (p 62)
Example 8 on page 62 estimates the mean for Internet Usage this way and finds it to be 41.8.
The following are the general shapes that distributions can take on:
10
1
N
2/5/2016
Math 131
Unit 1
Symmetric: Histogram has approximately mirror images on both sides of a vertical line in the
middle: mean, median and mode are about the same.
Uniform: Histogram is flat: mean and median are about the same.
Skewed left: Mean is less that median and mode.
Skewed right: Mean is more than the median and mode.
Finding Measures of Central Tendency in Minitab (Manual p 67)
Using exercise 19 p 65 (EX2_3-19.MTP) as an example
Minitab: Stat->Basic Statistics->Display Descriptive Statistics->(Choose the Column)-> Click on
Statistics…->choose the stats from the Dialog box (Note there is no Mode choice although Minitab can
help find the mode as discussed below) click OK OK
Results for: EX2_3-19.MTP
Descriptive Statistics: Points per game
Variable
Points per game
Mean
97.000
Median
97.200
The results for the mean and median are the same as those presented in the answers on p A50.
Using Minitab to Obtain Frequency of Individual Variables
To determine the frequency of individual variables in Minitab click Stat -> Tables -> Tally Individual
Variables, check Counts, and click OK.
The value with the highest frequency is the mode.
The results in the Session window show that 94.8, 95.4, 97.2 and 103.1 appear twice, while the other scores appear
only once, so these are the mode. This agrees with the answer on p A50.
Section 2.4 Measures of Variation (p 70)
Range = Max entry – Min entry
Deviation of an entry x: x –
Population variance:
2
( x ) 2
. Note
N
N
Var ( X ) E[( x ) 2 ( xi ) 2 p( xi ) . If each element has an equal chance of being
i 1
selected, p ( xi )
1
.
N
Population standard deviation:
Sample variance:
s2
2
( x x ) 2
n 1
Sample Standard deviation: s s
Why do we divide by n – 1 and not by n when we define the sample variance? The reason is that for
2
2
random samples from an infinite population, this makes s and unbiased estimator of
2 , i.e.
E (s 2 ) 2 .
This is proven in Freund (p 216). Freund notes, however, that s is not an unbiased of the standard deviation.
2
Also, for a finite population as defined in Freund on p 182, s is not an unbiased estimator of the variance.
11
2/5/2016
Math 131
Unit 1
Finding Measures of Variation in Minitab
Using the Try it Yourself Example on p 74 (TIY2_4-5.MTP)
Stat->Basic Statistics->Display Descriptive Statistics->(Choose the Column)-> Click on Statistics…>choose the stats from the Dialog box. Click OK OK
The results are as follows:
Descriptive Statistics: Rental rates
Variable
Rental rates
N
20
N*
0
Mean
37.888
StDev
3.979
These results are the same as those given in the Try it Yourself appendix on p A32.
Empirical Rule (p 76): For data with a symmetric bell-shaped distribution, about 68% of data lies within 1
standard deviation of the mean, about 95% lies within 2 standard deviations of the mean, and about 99.7%
lies within 3 standard deviations of the mean.
Chebychev’s Theorem (p 77): The portion of any data set lying within k standard deviations (k > 1) of the
mean is at least 1
1
k2
Mathematically this is: P (| X | k )
1
k2
For example, 75% of data lies within 2 standard deviations of the mean.
Sample standard deviation. In a sample of grouped data which has much repeated data (such as number of
children per household presented in the example on p 78), the formula for the standard deviation can be
simplified as follows:
( x x ) 2 f
n 1
s
Also as in the case with the mean (p 62) this formula can be used as an approximation with x being the
midpoint and f the frequency of each class.
Section 2.5 Measures of Position (p 87)
DEFINITIONS (p 87)
Fractiles are data values that divide an ordered set into equal parts.
The median is a fractile because about one half the data lies below it and one half above.
Quartiles divide the set into four parts. About one quarter of the data falls on or below the first
quartile (Q1 ) , half below the second quartile (the median) and three fourths below the third
quartile (Q3 ) .
Deciles divide the data into ten parts
Percentiles divide the data into 100 parts, e.g. 90% of the data falls below the 90 th percentile.
To find the fractiles, first order the data, then count the number of elements. For example, sorting the data
in example 1 on page 87 (CPR Test Scores) and bolding the first, second and third quartiles gives:
5 7 9 10 11 13 14 15 16 17 18 18 20 21 37.
12
2/5/2016
Math 131
Unit 1
Just as with the median, Q1 and Q3 may fall between two actual items. In our example we choose 10 for Q 1
because 4/15 = .27 of the data are less than or equal to it.
Finding Quartiles in Minitab (Manual p 88)
Using Example 2, p 88 (TIY2_5-2.MTP )as an example
Stat->Basic Statistics->Display Descriptive Statistics->Choose column C1->Statistics…->choose First
quartile, Median and third Quartile. Click OK
The results are as follows:
Results for: TIY2_5-2.MTP
Descriptive Statistics: Tuition Costs
Variable
Tuition Costs
Q1
17.00
Median
23.00
Q3
28.50
This is the same as the answer on page A33.
DEFINITION (p 89) The Interquartile Range:
IQR Q3 Q1
Note that Minitab also displays the IQR in the same way we displayed the other statistics.
The IQR for the data from example 1 is 18 – 10 = 8 (example 3 p 89).
A Box-and-Whisker Plot (or simply of Boxplot) is a line from the minimum entry, a box from
Q1 to
Q3 and a line from Q3 to the maximum entry. It gives a representation of how much of the data is in the
middle.
GUIDELINES (p 90)
1. Find the five-number summary, Min, Q1, M, Q3, Max
2. Construct the horizontal scale that spans the range of the data
3. Plot the five numbers on the horizontal scale.
4. Draw a box above the horizontal scale from Q1, to Q3 and draw a vertical line in the box at M.
5. Draw whiskers from the box to Min and Max.
Example 4 on p 90 gives the Box-and-Whisker Plot of the data in example 1. The numbers are 5, 10, 15,18,
37.
5 6 7 8 9 10111213141516171819202122232425262728293031323334343637
If a whisker or box is short, this indicates that the data is concentrated in this range. This boxplot for our
example indicates that one quarter of the data is concentrated between 15 and 18 (the third quartile). This is
confirmed by the following histogram:
13
2/5/2016
Math 131
Unit 1
Histogram of CPR Scores
5
Frequency
4
3
2
1
0
5
10
15
20
25
CPR Scores
30
35
40
Comparing Boxplot and Histogram for Internet Usage
Histogram
Histogram of InterUse
12
12
10
Frequency
10
8
7
7
6
6
4
4
4
2
0
7.00000000
1.8571E+01
3.0143E+01
4.1714E+01
5.3286E+01
InterUse
6.4857E+01
7.6429E+01
8.8000E+01
Boxplot
Boxplot of InterUse
0
10
20
30
40
50
InterUse
60
70
80
90
Notice that where the Histogram has the highest bar (between 30 and 40) is where the boxplot has the
narrowest box. This is because many sample points are crowded in this region: enough to constitute a
quartile. Note also that if the left whisker and the left box are narrow, the data is skewed to the left, and if
the right box and right whisker are narrow, the data is skewed to the right.
14
2/5/2016
Math 131
Unit 1
Constructing a Boxplot in Minitab (Manual p 90)
Minitab is demonstrated with exercise 33, page 96 (EX2_5-33.MTP).
Method 1 (This is given as the second method on Manual p 93, but it seems more obvious to me)
Click on Graph->Boxplot and select Simple boxplot. Click on OK. Select C1 for the Graph variable. To
view a horizontal boxplot (rather than a vertical one) click on Scale and select Transpose value and
category scales. Click on OK twice.
The result is shown below. Note that the meaning of the whisker in Minitab seems to differ from what is
stated in the book. In the book the whisker extends to the smallest and largest element, whereas in Minitab
there is a concept of an outlier, which is a sample value that is much larger or smaller than the rest. So, if
there is not an outlier, the whisker extends to the largest and smallest item as defined in the book. But if
there is an outlier, it is indicated with an asterisk and the whisker does not extend it. The answer to EX2_533.MTP is shown on page A52 of the book and the whisker extends to the largest age (82). In the Minitab
results below, the whisker does not extend to this age and it is presented with an asterisk.
Boxplot of Ages of Executives
20
30
40
50
60
Ages of Executives
70
80
Minitab result of exercise 33 page 96 (EX2_5-33.MTP)
Method 2 (Note, this does not give the option of constructing a horizontal boxplot)
Stat->Basic Statistics->Display Descriptive Statistics. Select column and click on the Graphs Button,
select Boxplot of Data
DEFINITION (p 92) The standard score or z-score represents the number of standard deviations a given
value x falls from the mean μ. That is:
z
x
Example 6 on p 92 calculates the z-score for speeds on a stretch of highway where the mean is 56 mph and
the standard deviation is 4 mph. Someone traveling 47 miles per hour has the following z-score:
z
47 56
2.25
4
Chebyshev’s theorem tells us that at most only 25% of drivers drive further from the average of 56 mph
than this driver.
15
2/5/2016
Math 131
Unit 1
Someone driving 68 mph is 3 standard deviations above the mean. Chebyshev’s theorem tells us that at
most only 11.1% of drivers drive this far from the mean.
Using Minitab to Compute z-scores (Manual p 86)
Calc -> Standardize. Choose the Input column and the column to Store results in (usually an empty
column). Click on Subtract mean and divide by std. dev., click OK.
The results for each value in the input column are stored in the column you chose.
Chapter 3 Probability (p 109)
Section 3.1 Basic Concepts of Probability
DEFINITION (p 110) A probability experiment is an action, or trial, through which specific results
(counts, measurements or responses) are obtained. The result of a single trial in a probability experiment is
an outcome. The set of all possible outcomes of a probability experiment is the sample space. An event
consists of one or more outcomes and is a subset of the sample space.
Example 1 (p110) The experiment consists of tossing a coin then rolling a die. the sample space consists of
H
1
H1
2
H2
3
H3
T
4
H4
5
H5
6
H6
1
T1
2
T2
3
T3
4
T4
5
T5
6
T6
How many outcomes are there? Do you agree, disagree, or have no opinion, and what is your gender? (p
111)
An event that consists of a single outcome is called a simple event (p 111).
DEFINITION (p 112) Classical (or theoretical) is used when each outcome in a sample space is equally
likely to occur. The Classical probability of an event E is given by:
P( E )
Number of outcomes in E
Total number of outcomes in sample space
Example 3 (p 112) Roll a die: What is the sample space? {1,2,3,4,5,6}
Event A: rolling a 3, p = 1/6 = 0.157. Note this is a simple event.
Event C: rolling < 5, p =4/6 = 0.667. Note this is not a simple event.
DEFINITION (p 113) Empirical (or statistical) probability is based on observations obtained from
probability experiments. The empirical probability of an event E is the relative frequency of event E:
P( E )
Frequency of event E f
Total frequency
n
Example: Finding Empirical Probabilities (p 113). Each fish (Bluegill, Redgill, and Crappy) is equally
likely to get caught. You catch and release the following.
Fish Type
Bluegill
Redgill
Crappy
Number of times caught, f
13
17
10
f 40
Probability of catching a bluegill = 13/40 = 0.325
16
2/5/2016
Math 131
Unit 1
Law of Large Numbers (p 114): As an experiment is repeated over and over, the empirical probability of
the event approaches the theoretical (actual) probability of the event.
For example, the theoretical probability of getting a head on a fair toss of a coin is 0.5. If you toss the coin
10 times, there’s a good chance that you’ll get 4 or less or 6 or more heads, but if you toss it 1000 times,
there’s a small chance that you’ll get 400 or less or 600 or more heads.
See Example 5 on p 114 for an example about using frequency distributions to find probabilities.
A third type of probability is subjective probability, e.g. predicting a patient’s chances for full recovery
(p114)
An important property of probability is that the sum of the probabilities of all outcomes in the sample
space is 1. (p 116)
DEFINITION (p 116) The complement of Event E is the set of all outcomes in a sample space that are
not included in event E. The complement of event E is denoted by E’ and is read as “E prime”.
For example the sample space for rolling a die is {1,2,3,4,5,6}. If E is the event that the number is at least
5, the complement is the number is less than 5.
E = {5,6}, E’ = {1,2,3,4}
From the above it is clear that:
P( E ) P( E ) 1
We often use a Venn diagram to illustrate the relationship between a sample space, an event E and its
complement E’.
17
2/5/2016
Math 131
Unit 2
Unit 2 Probability & Probability Distributions
Section 3.2 Conditional Probability and the Multiplication Rule (p 121)
DEFINITION (p 121) A conditional probability is the probability of an event occurring, given that
another event has already occurred. The conditional probability of event B occurring, given that event A
has occurred, is denoted by P ( B | A) and is read as “probability of B , given A . (p 121)
DEFINITION (p 122) Two events are independent if the occurrence of one of the events does not affect
the probability of the occurrence of the other event. Two events A and B are independent if
P( B | A) P( B) or if P( A | B) P( A)
Events that are not independent are dependent.
Often it is important to determine whether two events are independent. To determine if A and B are
independent, calculate P (B) and P( B | A). If the values are equal, the events are independent. If
P(B) P ( B | A) , then A and B are independent events. (p 122)
Example (p 122): Select a King from a deck of cards (event K), not replacing it, and then select a Queen
(Event Q):
P( K )
4
4
, P(Q | K )
, so the events are dependent.
52
51
The Multiplication Rule for the probability that two events A and B will occur in sequence is
P( A and B) P( A) * P( B | A) .
If events A and B are independent, then the rule can be simplified to P( A and B) P( A) * P( B) .
This simplified rule can be extended for any number of independent events. (p 123)
Example (p 123). What is the probability of selecting a King then a Queen?
P( K ) P(Q | K )
4 4
16
0.006
52 51 2652
Another example (Hogg & Craig, p 59): A bowl contains eight chips, three red and five blue. Two chips are
drawn successively, at random and without replacement. What is the probalility that the firs is red and the
second is blue?
P(R) = 3/8, P(B|R) = 5/7, so P(R and B) = (3/8)*(5/7) = 15/56 = 0.268.
Section 3.3 The Addition Rule
Two events A and B are mutually exclusive if A and B cannot occur at the same time. (p 130)
The probability that events A or B will occur is:
P( A or B) P( A) P( B) P( A and B)
If events A and B are mutually exclusive, then the rule can be simplified to
P( A or B) P( A) P( B).
This simplified rule can be extended to any number of mutually exclusive events. (p 131)
Example (p 131) Select a card from a deck. What is the probability that it s either 4 or Ace.
4C 4H
4D 4S
AC AH
AD AS
18
2/5/2016
Math 131
Unit 2
P(4 or A) = P(4) + P(A) = 4/52 + 4/52 = 0.154.
My Example: What is the probability that it is a 4 or a Club?
4
Club
P(4or C lub) P(4) P(C lub) P(4 and C lub)
4 13 1 16
0.308
52 52 52 52
Example (p 131): Roll a die. What is the probability that it is < 3 or odd. Two-sixths + three-sixths – onesixth = four-sixths.
TIY 2 (p 132): Probability of Face Card or Heart: 12/52 + 13/52 – 3/52 = 22/52.
Exercise 19 (p 137) In a sample of 1000 people, 120 are left handed. If two unrelated people are selected at
random from the sample find the probability of the following:
1.
2.
3.
4.
120 119
0.014294
1000 999
120 880
P( LR)
0.105706
1000 999
880 120
P( RL )
0.105706
1000 999
880 879
P( RR )
0.774294
1000 999
P ( LL)
Bullet 1 answers part A (both are left handed). Part B (at least one is left handed) can be answered as
follows: Its Bullet 1 + Bullet 2 + Bullet 3 = 0.225706. Its also 1 – Bullet 4 = 0.225706. Part C (neither is
left handed) is answered by Bullet 4. Part D: C (neither is left handed) is complementary with B (at least
one is left handed)
Simulating the Birthday Problem in Minitab
Calc->Random Data->Integer, Generate 24 rows of data, Store in column(s) C1, Minimum value 1,
Maximum value 365 OK
Then Stat->Tables->Tally Individual Variables, select column C1 and check Counts, OK
Note whether any value appears more than once.
Section 3.4 Counting Principles (p 140)
The Fundamental Counting Principle: If one event can occur in m ways and a second event can occur in
n ways, the number of ways the two events can occur in sequence is m n . This rule can be extended for
any number of events occurring in sequence. (p 140)
Example 1 (p 140)
19
2/5/2016
Math 131
Manufacturer
Car size
Color
Unit 2
Ford, GM, Chrysler
small, medium
White, Red, Black, Green
Number of ways of selecting one Manufacturer, one size and one color are: 3*2*4 = 24.
A permutation (p 141) is an ordered arrangement of objects. The number of different permutations of
n distinct objects is n factorial, which is written as n! and equals n*(n-1)*(n-2)…1.
For example How many possible batting orders are possible with the starting 9 players. The first player can
be chosen 9 ways, the second 8, the third 7 etc. So the number of ways is 9! = 362,880. (p 142)
The number of permutations of n objects taken r at a time is: (p 142)
n
Pr n(n 1)( n 2)...( n r 1)
n!
(n r )!
For example how many ways can we select the batting order of the first three players who will start the
game: We are choosing 3 players out of 9, so the number is:
9
P3 9 * 8 * 7 504
Note: Distinguishable Permutations (p 143) are not covered
Suppose the above question was: How many ways can we select the first three players who will start the
game? I.E. order does not matter, so that selection A, B, C is the same as players C, B, A. The selection of r
objects from n where order does not matter is called a combination. We can see that
9
C3 9 P3 / 3! 504 / 6 84
In General n C r n Pr
/ r!
This leads to the following DEFINITION: A combination (p 144) is a selection of r objects from a group
of n objects without regard to order is and is denoted by
n
Cr
n!
(n r )! r!
Note that this is called the combination of n things taken r at a time and is often denoted by
n
.
r
How many poker hands are there?
52
2598960
5
Example 9 (p 146): What is the probability of a diamond flush?
13
5 1287 0.0004951
52 2598960
5
The denominator is the number of ways of selecting 5 objects from 52, i.e. the number of poker hands. The
numerator is the number of ways of selecting 5 objects from 13 (the number of diamonds).
20
2/5/2016
Math 131
Unit 2
My example: What is the probability of a Flush: There are four ways of obtaining a flush so the probability
is
4 1287
5148
0.0019807
2598960 2598960
Note: Wikipedia ( http://en.wikipedia.org/wiki/Poker_probability) states the following about the probability
of a Flush -- The flush contains any five of the thirteen ranks, all of which belong to one of the four suits,
minus the 40 straight flushes. Thus, the total number of flushes is:
Thus the probability is 0.0019654. So although a straight flush is a flush, Wikipedia excludes it from the
probability of a flush because it has its own category with 40 combinations.
Section 3.4 Exercise 9 The access code for a car’s security system consists of four digits. The firs digit
cannot be zero and the last digit must be odd. How many different codes are available? 9*10*10*5 = 4500.
Chapter 4 Discrete Probability Distributions (p 161)
Section 4.1 Probability Distributions (p 162)
DEFINITIONS (p 162)
A random variable X represents a numerical value associated with each outcome of a probability
experiment.
A random variable is discrete if it has a finite or countable number of possible outcomes that can
be listed.
A random variable is continuous if it has an uncountable number of possible outcomes,
represented by an interval on the number line.
The number of calls a salesperson makes in one day is an example of a discrete random variable, while the
time in hours he spends making calls in one day is an example of a continuous random variable. (p 162).
A discrete probability distribution lists each possible value the random variable can assume, together
with its probability. A probability distribution must satisfy the following conditions (p 163):
The probability of each value of the discrete random variable is between 0 and 1: 0 P( x) 1
The sum of all the probabilities is 1:
P(x) 1
Guidelines for constructing a discrete probability distribution: (p164)
1. Make a frequency distribution for the possible outcomes
2. Find the sum of the frequencies
3. Find the probability of each possible outcome by dividing its frequency by the sum of the
frequencies.
4. Check that each probability is between 0 and 1 and that the sum is 1.
Example (p 164) Individuals are rated on a score of 1 to 5 for passive-aggressive traits, where 1 is
extremely passive and 5 is extremely aggressive.
Score, X
1
Frequency, f
24
P(X)
0.16
21
2/5/2016
Math 131
2
3
4
5
Total
33
42
30
21
150
Unit 2
0.22
0.28
0.2
0.14
1.00
The mean (also called the expected value) of a discrete random variable is given by (p 166):
ExpectedValue E( x) xP( x)
Note that each value of x is multiplied by its corresponding probability and the products are added.
Example (p 166) Find the mean for passive-aggressive traits above:
X
1
2
3
4
5
P(X)
0.16
0.22
0.28
0.2
0.14
XP(X)
1*0.16 = 0.16
2*0.22 = 0.44
3*0.28 = 0.84
4*0.20 = 0.80
5*0.14 = 0.70
P ( X ) 1
XP( X ) 2.94
The variance of a discrete random variable is the expected value of
2 E( x ) 2 ( x ) 2 P( x)
(x )2 :
The standard deviation is
2
Example (p 167) Find the Variance and Standard Deviation of the passive-aggressive measure in the above
example
X
P(X)
x
(x )2
P( x)( x ) 2
1
2
3
4
5
X
0.16
0.22
0.28
0.2
0.14
-1.94
-0.94
0.06
1.06
2.06
3.764
0.884
0.004
1.124
4.244
0.602
0.194
0.001
0.225
0.594
P ( X ) 1
P( x)( x ) 2 1.616
So,
Var ( x) 2 1.616
1.616 1.27.
Section 4.2 Binomial Distributions (p 174)
A binomial experiment is a probability experiment that satisfies the following conditions:
22
2/5/2016
1.
2.
3.
4.
Math 131
Unit 2
The experiment is repeated for a fixed number of trials where each trial is independent of the other
trials.
There are only two possible outcomes of interest for each trial. The outcomes can be classified as a
success (S) or as a failure (F).
The probability of a success P(S) is the same for each trial.
The random variable x counts the number of successful trials.
Notation for Binomial Experiments
Symbol
Description
n
The number of times the trial is repeated
The probability of success in a single trial
p P (S )
q P (F )
x
The probability of failure in a single trial ( q 1 p )
The random variable represents a count of the number of successes in n trials: x =
0,1,2,3,…,n
Suppose we have 9 trials. If we let 0 mean failure and 1 mean success, the probability of getting the results:
3
6
0 0 1 0 1 1 0 0 0 is p q . (See Mood and Graybill p 66.) This is a specific way of getting 3 successes: on
the third fifth and sixth tries. Each try can be viewed as a box, and the number of ways we can place 3 1’s
in 9 boxes is the same as the number of ways we can choose the first 3 players from 9 on a baseball team.
9
. In general the probability of a specific arrangement of x 1’s and n-x 0’s is p x q n x and there
3
n
are arrangements. This leads to the following formula for the binomial distribution.
x
This is
In a binomial experiment, the probability of exactly x successes in n trials is:
n
n!
p x q n x p x q n x , x 0,1,2,..., n
(n x)! x!
x
This is often referred to as b( x; n, p ) .
P( x) n C x p x q n x
We can also see how this formula is derived from a simple example: Suppose we perform have 3 trials. The
possible results are:
Probability of sample point
Sample Points
Value of x
So,
SSS
p3
3
SSF
2
p q
2
SFS
p2q
2
SFF
pq
2
1
FSS
p2q
2
FSF
pq 2
1
FFS
pq
2
1
FFF
q3
0
3
3
3
3
P(0) q 3 , P(1) pq 2 , P(2) p 2 q, P(3) p 3
0
1
2
3
23
2/5/2016
Math 131
Unit 2
Appendix B, Table 2 gives, for the binomial distribution, the probabilities of x successes in n trials, for
values of n = 2-16,20 for x = 0 to n, for various probabilities of success.
Population Parameters of a Binomial Distribution (p 182)
np
2 npq
npq
The following are derivations of the mean for n = 1 and 2. (Mendenhall p 123)
1
E ( x) xp( x) 0q 1 p p
n 1
x 0
2
E ( x) xp( x) 0q 2 1 2 pq 2 p 2 2 p(q p) 2 p
n2
x 0
The following is a derivation of the variance for n = 1. (Mendenhall p 123)
1
2 E ( x ) 2 ( x ) 2 p( x) (0 p) 2 q (1 p) 2 p p 2 q q 2 p pq(q p) pq.
x 0
Example (p 184 Exercise 11): 54 percent of men consider themselves basketball fans. You randomly select
10 men and ask each of he considers himself a basketball fan. Find the probabilities that the number who
are fans is:
Exactly eight
At least eight
Less than eight
10
0.54 8 0.46 2 0.069
8
10
10
0.069 0.54 9 0.461 0.5410 0.46 0 0.089
9
10
1 0.089 0.911
Example: What is the probability of getting 3 kings in five draws of the card without replacement. This is
NOT the binomial distribution because the draws are not independent. The probability is described by the
hypergeometric distribution. This is discussed briefly in exercise 16 on p 194. The hypergeometric
distribution is defined as follows
a b
x n x
h( x; n, a, b)
where a is the number of “success” elements, b is the number of “failure”
a b
n
elements, n is the sample size and x is the number of successes.
So getting 3 kings in five draws without replacement is
24
2/5/2016
Math 131
Unit 2
4 48
3 2
94
h(3;5,4,48)
0.002
54145
52
5
When the sample size n is small compared with the population size, a + b, we sometimes use the binomial
distribution to approximate the hypergeometric distribution. For example, suppose we know that we have a
room with 100 people and we know that 60 support candidate A. If we select 10 people, what is the
probability that 5 support candidate A?
60 40
5 5
h(5;10,60,40) 0.208
100
10
Since n = 10 is small compared to a + b = 100, we can approximate with the binomial distribution:
10
b(5;10,0.6) (0.6) 5 (0.4) 5 0.201
5
Constructing a binomial Distribution using Minitab (Manual p 128)
Using Minitab to find a binomial distribution (i.e. the probability of x successes in n trials) (Using Try it
Yourself Section 4.2 p 177 as an example): Enter the x values (the number of successes that you want the
probabilities for, usually 0,1,…,n (0,1,2,3,4,5,6,7 in this example) in C1. Calc -> Probability
Distributions -> Binomial->Select Probability and enter n (7 in this example) for the Number of Trials,
the p (.34 in this example) for the Probability of Success and the Input Column (C1). Click OK
The results are as follows:
Probability Density Function
Binomial with n = 7 and p = 0.34
x
0
1
2
3
4
5
6
7
P( X = x )
0.054552
0.196716
0.304016
0.261024
0.134467
0.041563
0.007137
0.000525
This agrees with the answer given on p A35.
Using Minitab to find a particular value of a binomial distribution (Using Example 5 Section 4.5 p 179 as
an example): Calc -> Probability Distributions -> Binomial -> Select Probability, and enter the Number
of Trials, the Probability of Success and enter the particular value in the Input Constant.
The results are as follows:
Probability Density Function
25
2/5/2016
Math 131
Unit 2
Binomial with n = 250 and p = 0.71
x
178
P( X = x )
0.0555120
This agrees with the answer given on p A35.
Chapter 5 Normal Probability Distributions (p 205)
Section 5.1 Introduction to Normal Distributions (p 206)
GUIDELINES (p 206) A normal distribution is a continuous probability distribution for a random
variable x. The graph of a normal distribution is called the normal curve. A normal distribution has the
following properties.
1. The mean, median and mode are equal
2. The normal curve is bell shaped and is symmetric about the mean
3. The total area under the normal curve is equal to one
4. The normal curve approaches, but never touches, the x-axis as it extends farther and farther away
from the mean
5. Between and (in the center of the curve) the graph curves downward. The graph
curves upward to the left of and to the right of . The points at which the curve
changes from curving upward to curving downward are called inflection points.
The graph of the normal distribution (the density function) is given by the following equation (p 206):
y
1
2
e ( x )
2
/ 2 2
The normal distribution follows the empirical rule, which states that
1. About 68% of the area lies between and
2.
2 and 2
About 99.7% of the area lies between 3 and 3
About 95% of the area lies between
3.
(p 209)
Section 5.2 The Standard Normal Distribution (p 214)
The standard normal distribution is a normal distribution with a mean of 0 and a standard deviation of 1.
The z-score of any normal distribution has the standard normal distribution. As noted in section 2.5 the zscore is:
z
x
The density function for the standard normal distribution is:
y
ex
2
/2
2
Section 5.3 Normal Distributions: Finding Probabilities
26
2/5/2016
Math 131
Unit 2
To find the probability for any normal curve, convert the x values to their z-scores, and then find the
probability for the standard normal distribution.
For example, suppose x has a normal distribution with
x < 2, we convert it to the z-score:
z
x
2.4 and 0.5. To find the probability that
2 2.4
0.8
0 .5
Now we can use the standard normal table to find P( z 0.8) 0.2119.
We noted above that the normal distribution follows the empirical rule. Let’s see precisely what the
probabilities are that X lies within the following standard deviations of the mean.
one st dev
two st devs
three st devs
P(z < 1) = 0.8413, P(z < -1) = 0.1587
P(z < 2) = 0.9772, P(z < -2) = 0.0228
P(z < 3) = 0.9987, P(z < -3) = 0.0013
P(-1 < z < 1) = 0.8413 - 0.1587 = 0.6826
P(-2 < z < 2) = 0.9772 – 0.0228 = 0.9544
P(-3 < z < 3) = 0.9987 – 0.0013 = 0.9974
Since the normal curve is symmetric, the above calculations could be simplified. For example, Since P(z <
-1) = 0.1587, P(z > 1) = 0.1587. So P(-1 < z < 1) = 1 - 2*0.1578 = 0.6826. The following graph shows the
standard normal curve and highlights the area between –1 and 1.
What is the probability of being between 1 and 2 standard deviations from the mean?
P(-2 < z < 2) – P(-1 < z < 1) = 0.9544 - 0.6826 = 0.2718. Since the graph is symmetric, the probability of
being between 1 and 2 standard deviations above the mean equals the probability of being between 1 and 2
standard deviations below the mean: P(1 < z < 2) = 0.1359 and P(-2 < z < -1) = 0.1359.
Comparing with Chebychev’s Theorm
Within this distance from the mean
2
3
Chebychev
Normal
68%
95%
99.7%
75%
89%
Example 2 (p 223) A shopper spends mean 45 minutes and standard deviation 12 minutes in a super
market, and the time is normally distributed. This example finds the probabilities that a shopper will be in
the store between 24 and 54 minutes, and also more than 39 minutes.
27
2/5/2016
Math 131
Unit 2
Using Minitab to find the probability that a normally distributed random variable is less
than a specified value (Manual p 157)
Calc->Probability Distributions->Normal->Select Cumulative probability. Enter the Mean and
Standard deviation , then enter the value that up in the Input Constant.
Using Minitab to find the probability that a normally distributed random variable is
between two specified values (Manual p 159)
Using Try it Yourself Section 5.3 p 223 as an example.
Find the probability that it is less than the smaller value and the probability that it is less than the larger
value. Then subtract the former from the later.
Cumulative Distribution Function
Normal with mean = 45 and standard deviation = 12
x
33
P( X <= x )
0.158655
Cumulative Distribution Function
Normal with mean = 45 and standard deviation = 12
x
60
P( X <= x )
0.894350
Subtracting, 0.8944 – 0.1587 = 0.7357. This agrees with the answer given on p A36.
Section 5.4 Normal Distributions: Finding Values (p 229)
We can find the z-score that corresponds to a particular area or percentile by looking it up in the standard
normal table.
Example 1 (p 229) What is the z-score that correspond to a cumulative area of 0.3632? Looking up 0.3632
in the Standard Normal Table shows that the z-score is –0.35. Similarly the z-score corresponding to a
probability of 0.8925 is 1.24.
To find the x-value that corresponds to a particular area or percentile, look up the z-score in the standard
normal table, then use the equation
x z
to convert the z-score to the x-value.
For example (from example 4, p 232), suppose a normal distribution has a mean of 75 and a standard
deviation of 6.5, and we want the x-value corresponding to the 95th percentile. From the standard normal
table we find that the z-score corresponding to .95 is about 1.645. Therefore
x z 75 1.645 * 6.5 85.69.
Example 5, p 233. Mean cholesterol is 211 and standard deviation is 39.2. What is the highest level a man
can have and still be in the lowest 1%?
Looking up 1% in the Standard Normal Table gives z = -2.33. So
x z 211 (2.33)(39.2) 119.66
28
2/5/2016
Math 131
Unit 2
Section 5.5 The Central Limit Theorem (p 238)
The following explanation is from Freund (p 176).
Suppose we draw a random sample of size n: x1 , x 2 ,...x n are the values assumed by the random variables
X 1 , X 2 ,... X n which are independent and have the same distribution. The mean of the sample is the value
X 1 X 2 ... X n
n
The mean (also known as the expected value of X ) is denoted by E (X ) and also by x .
assumed by the random variable
The variance of
X is denoted by Var(X ) and also by x .
2
It can be shown that
x
and
x
2
2
n
So that the standard deviation of
x
X is
n
x
Note that
is called the standard error of the mean.
The fact that the standard error of the mean decreases as n increases is a very important result: It says that,
whatever the population distribution (provided that it has a finite variance) the distribution of the sample
mean becomes more and more concentrated near the population mean as the sample size increases (Mood
and Graybill, p 146).
Note, the book states this in the following way (p 238):
DEFINITION (p 238) A sampling distribution is a probability distribution of a sample statistic that is
formed when samples of size n are repeatedly taken from a population. If the sample statistic is the sample
mean, then the distribution is the sampling distribution of sample means. The mean of sample i is denoted
by x i
The mean of the sample means is (p 238):
x
and the standard deviation of the sample means is (p 238):
x
n
This is also called the standard error of the mean.
30 ), x will be
( x ) , and standard deviation (standard error of
The central limit theorem states that for any population when n is large (book says
approximately normally distributed with mean
the mean)
( x
n ) , and the approximation becomes better as n increases. (p 240).
If the original population is normally distributed, the sampling distribution of sample means is normally
distributed for any sample size n.
29
2/5/2016
Math 131
Unit 2
Example 2 (p 241) Phone bills for residents of Cincinnati have mean $64 and standard deviation $9.
Random samples of size 36 are drawn and the mean of each sample is determined. Find the mean and the
standard error of the mean for the sampling distribution.
x 64
9
x
1.5
n
36
From the Central Limit Theorem, since n > 20 the sample mean has a normal distribution with mean 64 and
standard deviation 1.5.
Example 6 (p 245) Credit card balances are normally distributed with mean $2870 and standard deviation
$900. What is the probability that a randomly selected credit card holder has balance less than $2500?
x
2500 2870
0.41,
900
P( x 2500) P( z 0.41) 0.3409
z
What is the probability that a random sample of 25 credit card holders has mean balance less than $2500?
z
x x
x
/ n
2500 2870
2.06
900 / 25
P( x 2500) P( z 2.06) 0.0197
x
Section 5.6 Normal Approximations to Binomial Distributions (p 251)
The Central Limit Theorem can be restated to apply to the sum of sample measurements as follows:
x is normally distributed with mean = n and standard deviation = n as n becomes large.
Given that
E (X ) and Var ( X )
2
n
, this is easy to show:
E (X ) E (nX ) nE ( X ) n
Var (X ) Var (nX ) n 2Var ( X ) n 2
Applying this version of the Central Limit Theorem to the binomial distribution gives the following:
If np 5 and nq 5 the binomial random variable is approximately normally distributed with
mean
np
and standard deviation
npq
To see why this result is valid look at the graphs of various binomial distributions on p 251.
Note that the mean and standard deviation of the normal distribution is the same as the mean and standard
deviation of the binomial distribution.
The following table explains how to use the normal approximation to the binomial distribution.
Using the Normal Distribution to Approximate Binomial Probabilities
Procedure
Equations
Example (p 254)
Verify that the binomial
Specify n, p and q
p .37, q .63, n 15
30
2/5/2016
Math 131
distribution applies
Unit 2
Want probability that the number
of successes, x 8
Determine whether you can use
the normal distribution to
approximate x, the binomial
variable.
Find the mean and standard
deviation for the distribution
Is np 5 ?
Apply the appropriate continuity
correction.
Subtract 0.5 to the left boundary,
if there is one and add 0.5 to the
right boundary if there is one.
Find the corresponding z-score(s).
z
Find the probability
Use the Standard Normal Table.
Is nq 5 ?
If both are true, you can proceed.
np
npq
x
np 15 .37 5.55
nq 15 .63 9.45
5.55
1.87
7 0.5 7.5
7.5 5.55
1.04
1.87
P( z 1.04) 0.8508
z
Example 4 (p 255) In the U.S, 29% of people believe that passenger trips to the moon will occur in their
lifetime. You randomly select 50 people. What is the probability that at least 50 will say they believe it?
np 200 * 0.29 58, nq 200 * 0.71 142 , so the binomial is approximately normal with
np 58, npq 200 * 0.29 * 0.71 6.42
Using the correction for continuity, we want P(X>=49.5).
z (49.5 58) / 6.42 1.32
P( x 49.5) P( z 1.32) 1 P( z 1.32) 1 0.0934 0.9066 .
31
2/5/2016
Math 131
Unit 3
Unit 3 Inferential Statistics
Chapter 6 Confidence Intervals (p 269)
Section 6.1 Confidence Intervals for the Mean (Large Samples)
A point estimate is a single value estimate for a population parameter. The most unbiased
estimate of the population mean is the sample mean x .
An interval estimate is an interval, or range of values, used to estimate a population parameter.
The level of confidence c is the probability that the interval estimate contains the population
parameter.
Since we can hardly expect that point estimates based on samples always hit the parameters they are
supposed to estimate exactly, it is often desirable to give an interval rather than a single number. We can
then assert with a certain probability (or degree of confidence) that such an interval contains the parameter
it is intended to estimate. (Freund p 214)
For large samples, the Central Limit Theorem applies. From the CLT, when n 30 , the sampling
distribution of the sample mean x is normal. The level of confidence c is the area under the standard
normal curve between the critical values,
z c and z c . For example, if c = 95%, then 2.5% is less than
z c and 2.5% is greater than z c . Looking up the z-score in table A16, we see that z .95 1.96 and .
z.95 1.96 .
The distance between the point estimate and the actual parameter value is called the error of estimate.
When estimating
the error of estimate is the distance x .
Given a level of confidence c, the maximum error of estimate (sometimes called the margin of error or
error tolerance) E is the greatest possible distance between the point estimate and the value of the
parameter it is estimating.
E z c x z c
n
When n 30, the sample standard deviation
s can be used in place of .
In example 1 and example 2 on pages 270 – 272, there are 54 samples and the sample mean and sample
standard deviation are:
x
s
x
12.4
n
( x x ) 2
5.0
n 1
Substituting
E zc
n
zc
s
n
1.96
5.0
54
1.3
32
2/5/2016
Math 131
Unit 3
So we are 95% sure that the maximum error of estimate for the population mean is about 1.3.
The c-confidence interval for the population mean is x E x E
In the above example the 95% left endpoint (often called the lower confidence limit or LCL) of the
confidence interval is 12.4 – 1.3 = 11.1 and the right endpoint (often called the upper confidence limit or
UCL) is 12.4 + 1.3 = 13.7. So the 95% confidence interval is 11.1 13.7.
The confidence interval is often denoted in the following ways
xE
( x E, x E ) ( x z c
n
, x zc
n
)
Summary for finding confidence interval for population mean (p 273)
What to do
Find the sample statistics
n and x
Equations
Specify if known. Otherwise, if
n 30 , find the sample standard
deviation, s
Find the critical value
n
s 5.0
( x x ) 2
n 1
s
the right of
Find the maximum error of the
estimate E. Note this is the
critical value times the standard
error of the mean.
Find the left and right endpoints
and form the confidence interval
CI ( x z c
n 54, x 12.4
Use the Standard Normal Table to
find the value z c such that the area to
z c that
corresponds to the given level of
confidence
In summary,
Example (from above)
x
x
n
z c (1 c) 2 .
E z c x z c
n
zc
s
n
E 1.3
n
Left endpoint (LCL): x E
Right endpoint (UCL): x E
Interval: x E x E
, x zc
z.95 1.96
(11.1,13.7)
)
Example 5, p 275 Take a sample of size 20 from a Normal distribution with standard deviation = 1.5. The
sample mean is 22.9. What is the 90% CI?
Looking in Table 4 p A16 (Standard Normal Distribution)
CI ( x z c
(22.9 1.645
, x zc
n
1.5
20
n
z.05 1.645
)=
, 22.9 1.645
1.5
20
) (22.9 0.55, 22.9 0.55) (22.35, 23.45)
Using Minitab to find the Confidence Interval with a Sample in a Column for a Normal
Distribution (Manual p 183)
Enter data in column 1 (For example enter the 54 data points on page 270). (Note Manual generates 20
random samples from a Normal Distribution instead.) Then determine the standard deviation: Stat->Basic
33
2/5/2016
Math 131
Unit 3
Statistics->Display Descriptive Statistics (Click Statistics to be sure the standard deviation is included)>Click OK and note the standard deviation (In this example it is 5.015)
.
Stat->Basic Statistics->1-Sample Z…->Choose Column C1 and Enter the standard deviation from the
first step (In this example it is 5.015) ->Click Options then choose not equal for the Alternative and enter
the Confidence level (95% in the example), Click OK then Click OK again. If the data from the example
on p 270 is entered, the confidence interval is given as (11.0883, 13.7635).
Using Minitab to find the Confidence Interval with Summarized Data for a Normal
Distribution
Stat->Basic Statistics->1-Sample Z…->Choose Summarized Data, enter the Sample size (e.g. 100), the
Mean (e.g. 50) and the Standard deviation (e.g. 5). Click Options and enter the Confidence level (e.g.
95.0 and choose not equal for Alternative. Click OK, OK
The results are presented in the session window as follows:
One-Sample Z
The assumed standard deviation = 5
N
100
Mean
50.0000
SE Mean
0.5000
95% CI
(49.0200, 50.9800)
Determining Sample Size (p 276)
How large a sample size (n) is needed to guarantee a certain level of confidence for a given maximum error
of estimate (E)? This can be derived from the formula for E above
E zc
n
Solving for n gives:
z
n c
E
If
2
is unknown, s can be used as an estimate if there is a preliminary sample size of at least 30.
Example 6, p 276 We want to estimate the mean number of sentences in a magazine ad. How many ads must be in the
sample if you want to be 95% confident that the sample mean is within one sentence of the population mean?
From Example 2, p 272, s = 5.0, so
z
1.96 5.0
n c
96.04 . So you need a sample of size 97.
1
E
2
2
Section 6.2 Confidence Intervals for the Mean (Small Samples) (p 284)
When the sample size is small (less than 30), the sample standard deviation s is not good enough to assume
that the Central Limit Theorem applies. However when the random variable x is drawn from an
approximately normal distribution, the distribution of the following random variable t is known and is
called the t-distribution.
34
2/5/2016
t
Math 131
Unit 3
x
s
n
The t-distribution is bell shaped and symmetric about the mean.
The t-distribution is a family of curves, each determined by a parameter called the degrees of
freedom (d.f.) where d . f . n 1 (n is the sample size)
The total area under the t-curve is 1.
The mean, median, and mode of the t-distribution are equal to zero.
As the degrees of freedom increase, the t-distribution approaches the standard normal distribution
Constructing confidence interval using the t-distribution is similar to constructing it for the normal
distribution as the following table indicates
Procedure
Identify the sample statistics
Equations
n, x ,
and s
Identify the degrees of freedom, the
level of confidence c, and the critical
value t c
Estimate the maximum error of
estimate E
Find the confidence interval
x
( x x )
, s
n
n 1
d. f . n 1
t c is found in Table 5
x
Appendix B
E tc
s
n
( x E, x E )
2
Example 2 p 286
n 16 , x 162 ,
s 10
c .95
d . f . n 1 15
t c 2.131
10
E 2.131
5.3275
16
(156.6725,167.3275)
Summary of when the normal distribution or the t-distribution can be used (p 288)
If n 30 , the normal distribution can be used, and s can be used to estimate .
If n 30 and the population is normally or approximately normally distributed, use the normal
distribution if is known, otherwise use the t-distribution.
If n 30 and the population is not approximately normally distributed, a CI cannot be
constructed.
Using Minitab to find the Confidence Interval for a t-Distribution with the Sample in a
Column (Manual p 193)
We will use the data in Ex6_2-23.mtp (Chapter 6, p 291) Sports Cars: Miles per Gallon to illustrate the
method.
First verify the data is approximately normal. To draw a normal probability plot, click on Graph ->
Probability Plot and select the Single plot. Click on OK. Select C1 for the Graph variable. Click on OK
and the probability plot will be displayed. Notice that all the data points are contained within the
confidence bands of the plot.
Next check for outliers using a boxplot. Click on Graph->Boxplot and select Simple boxplot. Click on
OK. Select C1 for the Graph variable. To view a horizontal boxplot (rather than a vertical one) click on
Scale and select Transpose value and category scales. Click on OK twice. There are no outliers shown in
the boxplot, so you may now proceed with the confidence interval.
35
2/5/2016
Math 131
Unit 3
Since n = 25 and the population standard deviation is unknown, you should construct a t-interval for this
problem. Click on Stat -> Basic Statistics -> 1-Sample t. Select Samples in Columns and enter C1. Next
select Options and enter 95.0% for the Confidence Level and select ‘not equal’ for the Alternative. Click
on OK twice and the interval will be displayed in the Session Window as follows:
One-Sample T: Miles per gallon
Variable
Miles per gallon
N
25
Mean
24.0000
StDev
3.0000
SE Mean
0.6000
95% CI
(22.7617, 25.2383)
Note that the 95% Confidence Interval is (22.7617, 25.2383).
Using Minitab to find the Confidence Interval with Summarized Data for a t-Distribution
Stat->Basic Statistics->1-Sample t…->Choose Summarized Data, enter the Sample size (e.g. 10), the
Mean (e.g. 50) and the Standard deviation (e.g. 5). Click Options and enter the Confidence level (e.g.
95.0 and choose not equal for Alternative. Click OK, OK
The results are presented in the session window as follows:
One-Sample T
N
Mean
StDev
SE Mean
95% CI
10 50.0000 5.0000 1.5811 (46.4232, 53.5768)
Section 6.3 Confidence Intervals for Population Proportions (p 293)
The for p, the population proportion of success is given by the proportion of successes in a sample and is
denoted by
pˆ
x
n
where n is the sample size and x is the number of successes in the sample. The point estimate for the
ˆ . The symbols p̂ and q̂ are read as “p hat” and “q hat”. Note this is
number of failures is qˆ 1 p
derived from the equation in section 5.5 where the mean of
X was obtained.
The mean and standard deviation of the estimate p̂ are:
pˆ p
pˆ
pq
n
This is the standard error of the mean (section 5.5) when the random variable
X i only can take on the
value 0 or 1.
Relate this to the sample mean of a random variable that has a binomial distribution:
x
p ,
n
np
x 1
E ( p) E E ( x )
p,
n
n n
2
1
1
pq
x
Var ( p) Var 2 Var ( x ) 2 npq
n
n
n
n
The following table explains how to construct a confidence interval for the population proportion.
36
2/5/2016
Math 131
Unit 3
Constructing a Confidence Interval for the Population Proportion (p 294)
Procedure
Equations
Examples 1, 2 (p 293, 295)
Identify the sample statistics.
n is the number of trials and x is n 1024 , x 287
the number of successes
Find the point estimate p̂ .
287
x
pˆ qˆ
pˆ
0.28
pˆ , s pˆ
Also find the estimate of the
1027
n
n
standard deviation (the standare
error of the mean): s pˆ
Verify that the sampling
distribution of p̂ can be
approximated by the normal
distribution
Find the critical value
z c that
corresponds to the given level of
confidence c.
Find the maximum error of the
estimate E. This is the critical
value times the standard error of
the mean.
Find the left and right endpoints
of the confidence interval
npˆ 5
nqˆ 5
npˆ 1024 0.28 287
nqˆ 1024 0.72 737
Use the Standard Normal Table
to find the value z c such that the
z.95 1.96
area to the right of
z c (1 c) 2
E zc
pˆ qˆ
n
E 1.96
( pˆ E , pˆ E )
0.28 0.72
0.028
1024
(0.28 0.028, 0.28 0.028) =
(0.252, 0.308)
Finding the minimum sample size is done by substituting in the formula that was derived above:
z
z
n c pq c Note that pq is the estimate of the standard deviation of the proportion.
E
E
2
2
Example 4 p 297. We want to estimate the proportion of voters who support our candidate with 95%
confidence that we are within 3% of the actual proportion. Since there is no preliminary estimate for p we
use 0.5. Substituting into the above equation we gives:
2
1.96
n 0.5 * 0.5
1067.11
0.03
Rounding up, we need at least 1068 registered voters to be included in the sample.
Chapter 7 Hypothesis Testing with One Sample
Section 7.1 Introduction to Hypothesis Testing (p 321)
H 0 is a statistical hypothesis that contains a statement of equality, such as , , or .
The alternative hypothesis H a is the complement of the null hypothesis. It is a statement that must be true
A null hypothesis
if
H 0 is false and it contains a statement of inequality such as , , or .
37
2/5/2016
Math 131
Unit 3
A Type I error occurs if the null hypothesis is rejected when it is actually true.
A Type II error occurs if the null hypothesis is not rejected when it is actually false.
Example 1 (p 322) and Try it Yourself (p 322)
A university claims that the proportion of students
who graduate in four years is 82%
A water faucet manufacturer claims that the mean
flow rate of a faucet is less than 2.5 gpm
A cereal company claims that the mean weight of
the contents of its 20-ounce size cereal boxes is
more than 20 oz
An automobile battery manufacturer claims that the
mean live of a certain battery type is 74 months
A television manufacturer claims that the variance
of the life of a certain type of TV is <= 3.5
A radio station claims that its proportion of the local
listening audience is greater than 39%
H0: p = 0.82 (Claim)
Ha: p <> 0.82
H0: p >= 2.5 gpm
Ha: p < 2.5 gpm (Claim)
H0: mean <= 20 oz
Ha: mean > 20 oz (Claim)
H0: mean = 74 (Claim)
Ha: mean <> 74
H0: variance <= 3.5 (Claim)
Ha: variance > 3.5
H0: p <= 0.39
Ha: p > 0.39 (Claim)
DEFINITION (p 325) In a hypothesis test, the level of significance is your maximum allowable probability
of making a Type I error. It is denoted by . Three commonly used levels of significance are
0.10, 0.05, 0.01 . Note that making small means that we want a very small chance that we will
reject a null hypothesis that is true.
The probability of a type II error is denoted by .
The following table summarizes this:
Do not reject
Reject
H0
H 0 True
H a True
Correct decision
Type II Error (Probability = )
Type I error (Probability =
H0
)
Correct decision
The statistic that is compared to the parameter in the null hypothesis is called the test statistic.
The following table shows the relationships between population parameters and their corresponding test
statistics, sampling distributions, and standardized test statistics. (p 325)
Population Parameter
Test statistic
x
p
p̂
Sampling Distribution
If n 30 , Normal
If n 30 , Student t
Normal
Standardized test
statistic
z
t
z
DEFINITION: Assuming the null hypothesis is true, a P-value (or probability value) of a hypothesis is the
probability of obtaining a sample statistic with a value as extreme or more extreme than the one determined
from the sample data. (p 325)
If the alternative hypothesis
a left-tailed test, i.e. P is the area of the standard normal curve to the left of z.
If the alternative hypothesis H a contains the greater-than inequality symbol (>), the hypothesis
H a contains the less-than inequality symbol (<), the hypothesis test is
test is a right-tailed test.,i.e. P is the area of the standard normal curve to the right of z.
38
2/5/2016
Math 131
Unit 3
H a contains the not-equal-to symbol ( ), the hypothesis test is two1
tailed test. In a two-tailed test, each tail has an area of P .
2
If the alternative hypothesis
P-value: probability
of getting as or more
extreme result than
sample statistic
α: max
allowable
probability of
rejecting true
null
hypothesis
za
z standardized test
critical value.
called z0 (p 339)
Example of a left-tailed test: Reject if
statistic
z z Or equivalently, reject if P . In the figure above,
z z a ( P ) , so do not reject the null hypothesis.
Page 326 has a DEFINITION that shows the P area corresponding to each alternative hypothesis:
Alternative Hypothesis
<
>
<>
Area of Normal Curve
P is in left tail
P is in right tail
Half of P is in each tail
Example 3 p 327 shows the P-areas for the cases discussed in Example 1.
Section 7.2 Hypothesis Testing for the Mean (Large Samples) (p 334)
Remember the P-value is the probability of getting a result as extreme as you obtained and the level of
significance α is the maximum allowable probability of making a Type I error (rejecting the null hypothesis
when it is actually true). The decision rule based on the P-Value is: compare the P-value to . , then (p
334)
If P , then reject H 0
If
P , then fail to reject H 0
An equivalent way of deciding whether to accept or reject the Null Hypothesis is to determine whether the
standardized test statistic falls within a range of values called the rejection region of the sampling
distribution (p 339).
We will discuss both methods at the same time to show their equivalence This is why the discussion on p
339 is inserted here.
39
2/5/2016
Math 131
Unit 3
DEFINITION (p 339) A rejection region (or critical region) of the sampling distribution is the range of
values for which the null hypothesis is not probable. If a test statistic falls in this region, the null hypothesis
is rejected. A critical value, zo, separates the rejection region from the nonrejection region.
Using P-values for a z-Test for Mean μ (p 336). Also using the Critical Value Method (p 441)
Procedure
Equations
Example 4 p 337
State the claim mathematically and
Claim: Delivery time is < 30 min
State H 0 and H a
verbally. Identify the null and
H 0 : 30
alternative hypotheses
H a : 30
Specify the level of significance
Determine the standardized test
statistic. Note that this is the sample
mean minus the hypothesized mean
over the standard error of the mean.
Note, this alternative means we
use a left tailed test.
Identify
0.01
x is the test statistic
z is the standardized test
statistic
z
x
s
or if
n
n 30 use
n 36 , x 28.5, s 3.5
28.5 30
z
2.57
3.5 36
Note that x
is the
n
standard error of the mean and is
approximated by
3 .5
Find the area that corresponds to z.
O, using the Critical Value Method
described on p 34, determine the
critical value z0.
Find the P-value
Left-tailed test, P = area in left tail
Right-tailed test, P = area in right
tail
two-tailed test, P = 2(area in tail)
Make a decision to reject or fail to
reject the null hypothesis
Use table 4 in Appendix B, the
Standard Normal Distribution
Reject
H 0 if P-value ,
Otherwise do not reject.
Or using the Critical Value
Method, determine if z is in the
rejection region.
36 .5833
Area corresponding to
z 2.57 is 0.0051
Or using the Critical Value
Method from Standard Normal
Table, z0 = zα = z.01 = -2.33
Since this is a left-tailed test, the
P-value is 0.0051.
The P-value < , so reject H 0
Or using the Critical Value
Method, z z 0 2.33
So, since the claim (that delivery time is less than 30 minutes) is the alternative, we have sufficient
evidence to conclude that the claim is valid.
Using Minitab for Hypothesis testing for the mean with summarized data from a large
sample
Minitab: Stat->Basic Statistics -> 1-sample z->In the Dialog box, there are two choices: Samples in
columns and Summarized data. Choosing the Summarized data of the above example, enter Sample size
= 36, Mean = 28.5, Standard deviation = 3.5 and Test mean = 30. Then choose Options… and enter
Confidence Level = .99 (This is 1 ) and Alternative: less than, then click OK OK. Result P = 0.005
Note the 99% Upper Bound is given to be 29.8570. What does this mean?
40
2/5/2016
Math 131
Unit 3
Section 7.3 Hypothesis Testing for the Mean (Small Samples) (p 350)
For samples of size less than 30 and when is unknown, if the population has a normal, or nearly normal,
distribution, the t-distribution is used to test for the mean .
Using the t-Test for a Mean when the sample is small (p 352)
Procedure
Equations
Example 4 p 353
State the claim mathematically
State H 0 and H a
H 0 : 16500
and verbally. Identify the null and
H a : 16500
alternative hypotheses
d. f n 1
n 14, x 15700, s 1250
0.05
d . f . 13
Table 5 (t-distribution) in
appendix B
The test is left-tailed. Since test is
left tailed and d . f 13 , the
Specify the level of significance
Identify the degrees of freedom
and sketch the sampling
distribution
Determine any critical values. If
test is left tailed, use One tail,
column with a negative sign. If
test is right tailed, use One tail,
column with a positive sign. If
test is two tailed, use Two tails,
column with a negative and
positive sign.
Determine the rejection regions.
Specify
Find the standardized test statistic
t
Make a decision to reject or fail
to reject the null hypothesis
critical value is
The rejection region is
x
x
t t0
x
s
n
If t is in the rejection region,
reject H 0 , Otherwise do not
reject
t 0 1.771
The rejection region is
t 1.771
15700 16500
t
2.39
1250 14
Since 2.39 1.771, reject
H0
H0
Interpret the decision in the
context of the original claim.
Reject claim that mean is at least
16500.
Using Minitab to perform Hypothesis testing for the mean with summarized data when
the sample is small (Manual p 211)
We are assuming the population is normally distributed
Click on Stat -> Basic Statistics -> 1 sample t. Choose Summarized data and enter 14 for the Sample
size and 15700 for the Mean and 1250 for the Standard deviation and 16500 for the Test mean. Click
Options and enter 95 for the Confidence level and ‘less than’ for the Alternative. Click OK twice. The
results displayed in the Session Window are:
One-Sample T
Test of mu = 16500 vs < 16500
N
14
Mean
15700.0
StDev
1250.0
SE Mean
334.1
95%
Upper
Bound
16291.6
T
-2.39
41
P
0.016
2/5/2016
Math 131
Unit 3
Since the t-value (-2.39) is less than the critical value (-1.771) we reject the null hypothesis.
Section 7.4 Hypothesis Testing for Proportions (p 360)
Hypothesis testing for proportions is similar to hypothesis testing for the mean (Section 7.2). Recall from
section 6.3 that the mean and the standard error of the mean for the proportion are:
pˆ
pˆ
x
n
pq
n
If np 5 and nq 5 , then the sampling distribution is normal and the following table summarizes the
procedure.
Using Critical Values for a z-Test for Proportion p (p 360)
Procedure
Equations
Example 1 p 361
Verify that we can use the normal
np 100(0.20) 20
Verify that np 5 and
approximation.
nq 5
State the claim mathematically and
verbally. Identify the null and
alternative hypotheses
Specify the level of significance
Sketch the sampling distribution.
Determine any critical values
State
nq 100(0.80) 80
H 0 and H a
Claim: Less than 20% are allergic.
H 0 : p 0.2
H a : p 0.2
0.01
Identify
Use Table 4 in Appendix B to
determine the critical value(s)
from the level of significance
z 0.01 2.33
Determine the rejection regions
This is based on the critical
value(s) and specifies the
values of the test statistic
z that cause the rejection of
the null hypothesis
z 2.33
Determine the standardized test
statistic. Note that this is the
sample proportion minus the
hypothesized proportion over the
standard error of the mean.
z
Make a decision to reject or fail to
reject the null hypothesis
If z is in the rejection region,
reject H 0 , otherwise do not
pˆ p
pq n
reject. (If P-value ,
n 100 , pˆ 0.15
0.15 0.2
z
1.25
(0.2)(0.8) / 100
(Note P value 0.1056)
z z 0.01 , so do not reject H 0
(The P-value > , so do not
reject H 0 )
reject H 0 ,
otherwise do not reject.)
Using Minitab to perform Hypothesis testing for a proportion with summarized data
(Manual p 215)
We will test the hypothesis given in the example above. We showed above that we could assume normality.
42
2/5/2016
Math 131
Unit 3
Click on Stat -> Basic Statistics -> 1-Proportion. The data is in a summarized form, so select
Summarized data. Enter 100 for the Number of trials and 15 for the Number of events. Click on
Options. Enter 99 (or .99) for the Confidence level, 0.20 for the Test Proportion and ‘less than’ for the
Alternative. Because the assumption of normality has been met, select Use test and interval based on
normal distribution, and then click on OK twice. The results are:
Test and CI for One Proportion
Test of p = 0.2 vs p < 0.2
Sample
1
X
15
N
100
Sample p
0.150000
99%
Upper
Bound
0.233067
Z-Value
-1.25
P-Value
0.106
Chapter 9 Correlation and Regression
Section 9.1 Correlation (p 442)
DEFINITION A correlation is a relationship between two variables. The data can be represented by the
ordered pairs (x, y) where x is the independent or explanatory, variable and y is the dependent, or
response, variable.
A scatter plot is a graph of the x,y points (first discussed in section 2.2).
To construct a scatter plot we plot the independent variable on the x axis and the dependent variable on the
y axis. As p 442 shows, there can be a negative linear correlation, a positive linear correlation, no
correlation or a nonlinear correlation.
Using Minitab to draw a scatter plot (Manual p 93)
Using exercise 13, p 454 (EX9_1-13.MTP)
Click on Graph -> Scatterplot -> Simple. Click OK. Enter C2 for the Y variable and C1 for the X
variable. (You can also click Labels and specify your own title to replace the default provided by Minitab)
Click OK
For exercise EX9_1-13.MTP, the plot is Test score vs. Hours study.
The results are:
43
2/5/2016
Math 131
Unit 3
Scatterplot of Test Score vs Hours study
100
90
Test Score
80
70
60
50
40
0
1
2
3
4
5
Hours study
6
7
8
9
Obtaining the scatter plot for the Old Faithful data in Example 3 p 444:
Click on Graph -> Scatterplot -> Simple. Click OK. Enter Time for the Y variable and Duration for the
X variable. (You can also click Labels and specify your own title to replace the default provided by
Minitab) Click OK
The results are:
Scatterplot of Time y vs Duration x
95
90
85
Time y
80
75
70
65
60
55
2.0
2.5
3.0
3.5
Duration x
4.0
4.5
5.0
The Correlation Coefficient is a measure of the strength and the direction of a linear relationship between
two variables. The symbol r represents the sample correlation coefficient. The formula for r is
r
nxy (x)(y )
nx (x) 2 ny 2 (y ) 2
2
(p 445)
where n is the number of pairs of data.
The population correlation coefficient is represented by
.
Note, Hogg and Craig (p 69) give the following equation population correlation coefficient:
44
2/5/2016
Math 131
E( X 1 )(Y 2 )
1 2
E ( XY ) 1 2
1 2
=
12
1 2
Unit 3
where
12 is the covariance of X and Y
(Freund p 300). The covariance is positive if there is a high probability that large values of X go with large
values of Y and small values of X go with small values of Y. If there is a high probability that large values
of X go with small values of Y and vice versa, the covariance is negative (Freund p 112).
Hogg and Craig ( p 339) give the following equation for the sample correlation coefficient:
n
R
i 1
( X i X )(Yi Y )
n
(X
i 1
i
X)
(p 339)
n
2
(Y
i 1
i
Y )
2
This equation can be manipulated to yield the equation given in the text on p 445.
The range of the correlation coefficients is –1 to 1. If x and y have a strong positive linear correlation, r is
close to 1. I x and y have a strong negative linear correlation, r is close to –1. If there is no linear
correlation or a weak linear correlation, r is close to 0. See some examples on p 445.
Note that Yi Y is positive when
X i X is negative and vice versa.
So using the Hogg and Craig formula we
see that the correlation is negative when
the slope is negative as in the graph at
the left.
Example 1 (p 443) gives eight points for advertising expenses and company sales.
Advertising expenses (thousands of $)
2.4
1.6
2.0
2.6
1.4
1.6
2.0
2.2
Company sales (thousands of $)
225
184
220
240
180
184
186
215
The correlation coefficient for these data is calculated on p 446.
Using Minitab to find the Correlation Coefficient (Manual p 95)
Again using exercise 13, p 454 (EX9_1-13.MTP)
Click on Stat -> Basic Statistics -> Correlation: Choose the columns C1 and C2 and click OK
The results are displayed in the Session Window as follows:
Correlations: Hours study, Test Score
Pearson correlation of Hours study and Test Score = 0.923
45
2/5/2016
Math 131
Unit 3
P-Value = 0.000
The Window shows that the correlation coefficient is 0.923. Note that Minitab gives the P-value of the
Correlation Coefficient. The P-value is the probability of getting as or more extreme result than the sample
statistic if there were no correlation.
Using Minitab to find the correlation coefficient for the Old Faithful (Example 5 p 447)
Click on Stat -> Basic Statistics -> Correlation: Choose the columns C1 (Duration) and C2 (Time) and
click OK
The results are displayed in the Session Window as follows:
Scatterplot of Time y vs Duration x
Correlations: Duration x, Time y
Pearson correlation of Duration x and Time y = 0.972
P-Value = 0.000
We can test whether there is enough evidence to determine whether population correlation coefficient
is significant at a specified level of significance . We use table 11 in Appendix B to find the critical
value for the specified . If |r| > critical value, we can conclude that the correlation is significant. (p 448)
Procedure
Determine the number of pairs of
data in the sample
Specify the level of significance
Find the critical value
Decide it the correlation is
significant.
Interpret the decision in the
context of the original claim.
Equations
Determine n
Examples 3 p 444 and 6 p 449.
n 35
0.05
Table 11 in Appendix B
If |r| > critical value, the
correlation is significant.
critical value = 0.334
r 0.970 0.334 . Therefore
the correlation is significant
There is a significant correlation
between the duration of Old
Faithful’s eruptions and the time
until the next eruption.
Using Minitab to determine whether the correlation coefficient is significant (Manual, p
95)
For the specified level of significance , if |r| > r then the P-value is < . In the Minitab example for
Hours Study and Test Score we see that the P-value is 0.000. This is less than 0.05. So there is a significant
correlation.
In the Old Faithful example, the P-value is also 0.000 so there is a significant correlation. (Looking at Table
11 in Appendix B, we see that for sample size 35 and α = 0.05, the critical value is 0.334, confirming that
the correlation is significant.
Correlation does not necessarily mean causation. More in-depth study is needed to determine among the
following possibilities (p 452):
1. x causes y e.g. Old Faithful: duration affects time until next eruption
2. y causes x e.g. Old Faithful: time since last eruption affects next duration of next eruption
3. Some other variable or variables affect both x and y.
4. Coincidence
Section 9.2 Linear Regression (p 458)
46
2/5/2016
Math 131
Unit 3
Residuals are the differences
between the observed and predicted
points
The regression line, also called a line of best fit, is the line for which the sum of squares of the residuals is
a minimum.
The equation of a regression line for an independent variable x and a dependent variable y is (p 459)
yˆ mx b
where ŷ is the predicted y-value for a given x-value. The slope m and y –intercept b are given by
nxy (x)(y )
y
x
m
and b y mx
2
2
n
n
nx ( x )
where y is the mean of the y-values in the data set and x is the mean of the x-values. The regression line
always passes through the point ( x , y ).
m
Using Minitab to find the Least Squares Regression Equation (p 98)
Again using exercise 13, p 454 (EX9_1-13.MTP)
Click Stat -> Regression -> Regression. Choose the Predictor (x variable) and Response (y variable).
Click on Results and Choose Regression equation, table of coefficients, s, R-squared, and basic
analysis of variance. Click OK.
The results shown in the Session Window begins with:
Regression Analysis: Test Score versus Hours study
The regression equation is
Test Score = 34.6 + 7.35 Hours study
The data window also contains a new column for the residuals, i.e. the differences between the observed
and predicted values.
We can also obtain the equation when we create a scatter plot. This is described below.
If you want to make a prediction of a y-value for a specific x-value, do the above and also click on Options
in the Regression dialog Box enter the x-value for Prediction intervals for new observations, and select Fits.
This is described below.
If we enter 5 as the x-value, the following is shown in the Sessions Window.
Predicted Values for New Observations
New
Obs
1
Fit
71.37
SE Fit
2.16
95% CI
(66.60, 76.13)
95% PI
(53.76, 88.97)
Values of Predictors for New Observations
New
Obs
1
Hours
study
5.00
47
2/5/2016
Math 131
Unit 3
So the predicted value is 71.37. The result is also presented in the data window as the first element in a new
column labeled PFIT1. The result is 71.3653.
To draw the least squares regression line on the scatter plot, click Stat -> Regression -> Fitted line plot,
choose the Response (Y) and the Predictor (X), select Linear for the Type of Regression Model and
click OK.
The Fitted Line: Test Score versus Hours study regression line is presented with the scatter plot.
Using Minitab to find the Regression equation and a predicted value for the Old Faithful
Data (p 460)
Next we will determine the regression equation where x is the duration and y is the time until the next
eruption for Old Faithful. We will also predict the time when the duration is 5.1 minutes and draw the
regression equation on the scatter plot.
Click Stat -> Regression -> Regression. Choose the Predictor (duration) and Response (time). Click on
Results and Choose Regression equation, table of coefficients, s, R-squared, and basic analysis of
variance. Click OK then click on Options and enter the duration (5.1) for the Prediction intervals for the
new observations and select Fits, then click OK and OK again.
The results are:
Regression Analysis: Time versus Duration
The regression equation is
Time = 35.0 + 12.0 Duration
Predictor
Constant
Duration
Coef
34.983
11.9634
S = 3.21485
SE Coef
1.770
0.5080
R-Sq = 94.4%
T
19.76
23.55
P
0.000
0.000
R-Sq(adj) = 94.2%
Analysis of Variance
Source
Regression
Residual Error
Total
DF
1
33
34
SS
5732.8
341.1
6073.9
MS
5732.8
10.3
F
554.68
P
0.000
Predicted Values for New Observations
New
Obs
1
Fit
95.996
SE Fit
1.057
95% CI
(93.847, 98.146)
95% PI
(89.112, 102.881)
Values of Predictors for New Observations
New
Obs
1
Duration
5.10
48
2/5/2016
Math 131
Unit 3
The regression equation is
Time = 35.0 + 12.0 Duration
and the predicted value for the Duration of 5.10 is 95.996
Using Minitab to draw the least squares regression line on the scatter plot for the Old
Faithful Data
click Stat -> Regression -> Fitted line plot, choose the Response (Time) and the Predictor (Duration),
select Linear for the Type of Regression Model and click OK.
The Fitted Line: Test Score versus Hours study regression line is presented with the scatter plot.
The results are:
Fitted Line Plot
Time = 34.98 + 11.96 Duration
95
S
R-Sq
R-Sq(adj)
90
3.21485
94.4%
94.2%
85
Time
80
75
70
65
60
55
2.0
2.5
3.0
3.5
Duration
4.0
4.5
5.0
Chapter 10 Chi-Square Tests and the F-Distribution (p 493)
Section 10.1 Goodness of Fit
DEFINITION A chi-square goodness-of-fit test is used to test whether a frequency distribution fits an
expected distribution.
The test is used in a multinomial experiment to determine whether the number of results in each category
fits the null hypothesis:
H 0 : The distribution fits the proposed proportions
H 1 : The distribution differs from the claimed distribution.
To calculate the test statistic for the chi-square goodness-of-fit test, you can use observed frequencies and
expected frequencies.
DEFINITION The observed frequency O of a category is the frequency for the category observed in the
sample data.
The expected frequency E of a category is the calculated frequency for the category. Expected frequencies
are obtained assuming the specified (or hypothesized) distribution. The expected frequency for the ith
category is
Ei npi
where n is the number of trials (the sample size) and
p i is the assumed probability of the ith category.
49
2/5/2016
Math 131
Unit 3
The Chi-square Goodness of Fit Test: The sampling distribution for the goodness-of-fit test is a chi-square
distribution with k 1 degrees of freedom where k is the number of categories. The test statistic is
2
(O E ) 2
E
where O represents the observed frequency of each category and E represents the expected frequency of
each category. To use the chi-square goodness of fit test, the following must be true (p 496).
1. The observed frequencies must be obtained using a random sample.
2. The expected frequencies must be 5 .
Performing the Chi-Square Goodness-of-Fit Test (p 496)
Procedure
Equations
Example (p 497)
Identify the claim. State the null
State H 0 and H 1
H0 :
and alternative hypothesis.
Classical 4%
Country 36%
Gospel 11%
Oldies 2%
Pop 18%
Rock 29%
Specify the significance level
Specify
0.01
Determine the degrees of freedom d.f. = #categories - 1
d. f . 6 1 5
Find the critical value
2 : Obtain from Table 6
02.01 (d . f 5) 15.086
Appendix B
Identify the rejection region
2 2
Calculate the test statistic
2
2 15.086
(O E ) 2
E
Survey results, n = 500
Classical O= 8 E = .04*500 = 20
Country O = 210 E = .36*500 = 180
Gospel O = 7 E = .11*500 = 55
Oldies O = 10 E = .02*500 = 10
Pop O = 75 E = .18*500 = 90
Rock O= 125 E = .29*500 = 145
Substituting
Make the decision to reject or fail
to reject the null hypothesis
Reject if is in the
rejection region
Equivalently, we reject if the
P-value (the probability of
getting as extreme a value or
more extreme) is
2
Interpret the decision in the
context of the original claim
2 22.713
Since 22.713 > 15.086 we reject the
null hypothesis
Equivalently
P( X 22.713) 0.01 so reject the
null hypothesis. (Note Table 6 of
Appendix B doesn’t have a value less
than 0.005.)
Music preferences differ from the radio
station’s claim.
Using Minitab to perform the Chi-Square Goodness-of-Fit Test (Manual p 237)
The data from the example above (Example 2 p 497) will be used.
Enter Three columns: Music Type: Classical, etc, Observed: 8 etc, Distribution 0.04, etc. (Note the names
of the columns ‘Music Types’, ‘Observed’ and ‘Distribution’ are entered in the gray row at the top.)
50
2/5/2016
Math 131
Unit 3
Select Calc->Calculator, Store the results in C4, and calculate the Expression C3*500, click OK, Name
C4 ‘Expected’ since it now contains the expected frequencies
Music Type
Observed
Distribution
Expected
Classical
8
0.04
20
Country
210
0.36
180
Gospel
72
0.11
55
Oldies
10
0.02
10
Pop
75
0.18
90
Rock
125
0.29
145
Next calculate the chi-square statistic, (O-E)2/E as follows: Click Calc->Calculator. Store the results in
C5 and calculate the Expression (C2-C4)**2/C4. Click on OK and C5 should contain the calculated
values.
7.2000
5.0000
41.8909
0.0000
2.5000
2.7586
Next add up the values in C5 and the sum is the test statistic as follows: Click on Calc->Column Statistics.
Select Sum and enter C5 for the Input Variable. Click OK. The chi-square statistic is displayed in the
session window as follows:
Sum of C5
Sum of C5 = 22.7132
Next calculate the P-value: Click on Calc->Probability Distributions->Chi-square. Select Cumulative Probability
and enter 5 Degrees of Freedom Enter the value of the test statistic 22.7132 for the Input Constant. Click OK.
The following is displayed on the Session Window.
Cumulative Distribution Function
Chi-Square with 5 DF
x
22.7132
P( X <= x )
0.999617
P(X 22.7132) = 0.999617 So the P-value = 1 – 0.999617 = 0.000383. This is less that α = 0.01 so we reject the
null hypothesis.
Instead of calculating the P-value, we could have found the critical value from the Chi-Square table (Table 6 Appendix
B) for 5 degrees of freedom as we did above. The value is 15.086, and since our test statistic is 22.7132, we reject the
null hypothesis.
Chi-Square with M&M’s
H0: Brown: 13%, Yellow: 14%, Red: 13%, Orange: 20%, Green 16%, Blue 24%
Significance level: α = 0.05
Degrees of freedom: number of categories – 1 = 5
2 0.05 (d . f . 5) 11.071
2
Rejection Region: 11.071
Critical Value:
51
2/5/2016
Test Statistic:
Math 131
2
Unit 3
(O E ) 2
, where O is the actual number of M&M’s of each color in the bag and
E
E is the proportions specified under H0 times the total number.
Reject H0 if the test statistic is greater than the critical value (1.145)
Section 10.2 Independence (p 504)
This section describes the chi-square test for independence which tests whether two random variables are
independent of each other.
DEFINTION An r x c contingency table shows the observed frequencies for the two variables. The
observed frequencies are arranged in r rows and c columns. The intersection of a row and a column is
called a cell. (p 504).
The following is a contingency table for two variables A and B where f ij is the frequency that A equals Ai
and B equals Bj.
A1
A2
A3
A4
A
B1
f11
f12
f 13
f14
f 1.
B2
f 21
f 22
f 23
f 24
f 2.
B3
f 31
f 32
f 33
f 34
B
f .1
f .2
f .3
f .4
f 3.
f
If A and B are independent, we’d expect
( f i. )( f . j )
f f . j
f ij prob( A Ai ) * prob( B B j ) * f i. f
f
f f
( sum of row i ) ( sum of column j )
(p 504)
sample size
Example 1 (p 505) Determining the expected frequencies of CEO’s ages as a function of company size
under the assumption that age is independent of company size.
Small/midsize
Large
Total
Small/midsize
<= 39
42
5
47
40 - 49
69
18
87
50 - 59
108
85
193
60 - 69
60
120
180
>= 70
21
22
43
Total
300
250
550
<= 39
40 - 49
50 - 59
60 - 69
>= 70
300 * 47
550
25.64
300 * 87
550
47.45
300 * 193
550
105.27
300 * 180
550
98.18
300 * 43
550
23.45
Total
300
52
2/5/2016
Math 131
Unit 3
Large
250 * 47
550
21.36
250 * 87
550
39.55
250 * 193
550
87.73
250 * 180
550
81.82
250 * 43
550
19.55
250
Total
47
87
193
180
43
550
After finding the expected frequencies under the assumption that the variables are independent, you can test
whether they are independent using the chi-square independence test.
DEFINITION A chi-square independence test is used to test the independence of two random variables.
Using a chi-square test, you can determine whether the occurrence of one variable affects the probability of
occurrence of the other variable. (p 506)
To use the test,
1. The observed frequencies must be obtained from a random sample
2. Each expected frequency must be 5
The sampling distribution for the test is a chi-square distribution with
(r 1)(c 1)
degrees of freedom, where r and c are the number of rows and columns, respectively, of the contingency
table. The test statistic for the chi-square independence test is
2
(O E ) 2
E
where O represents the observed frequencies and E represents the expected frequencies.
To begin the test we state the null hypothesis that the variables are independent and the alternative
hypothesis that they are dependent.
Performing a Chi-Square Test for Independence (p 507)
Procedure
Equations
Example2 (p 507)
Identify the claim. State the null
H 0 : CEO’s ages are
State H 0 and H 1
and alternative hypotheses.
independent of company size
H 1 : CEO’s ages are dependent
on company size.
Specify the level of significance
Specify
0.01
Determine the degrees of freedom d . f . (r 1)(c 1)
d . f . (2 1)(5 1) 4
Find the critical value.
2 : Obtain from Table 6,
2 13.277
Appendix B
Identify the rejection region
2 2
Calculate the test statistic
2
Make a decision to reject or fail
to reject the null hypothesis
Reject if
2 13.277
(O E ) 2
E
2 is in the rejection
53
(O E ) 2
77.9
E
Note that O is in the table of
actual CEO’s ages above, and E
is in the table of Expected CEO’s
ages (if independent of size)
above
Since 77.9 > 13.277 we reject the
null hypothesis
2/5/2016
Math 131
Unit 3
region.
Equivalently, we reject if the Pvalue (the probability of getting
as extreme a value or more
extreme) is
Equivalently
P( X 77.0)
so reject the null hypothesis.
(Note Table 6 of Appendix B
doesn’t have a value less than
0.005.)
CEO’s ages and company size are
dependent.
Interpret the decision in the
context of the original claim
Using Minitab to perform the Chi-Square Independence Test (Manual p 242)
Enter the names of the columns Comp Size, 39 and under, 40-49 etc, enter the row names Small and Large
and enter the values in the rows as follows:
Comp Size
39 and under
40 - 49
50 - 59
60 - 69
70 and over
Small
42
69
108
60
21
Large
5
18
85
120
22
Click Stat->Tables->Chi-square Test. On the Chi-square Test dialog box, enter columns C2-C6 for the
Columns containing the table. (Note you can select several columns in the Windows way, i.e. with ShiftClick or Control Click) Click OK.
The results displayed in the Session Window are:
Chi-Square Test: 39 and under, 40 - 49, 50 - 59, 60 - 69, 70 and over
Expected counts are printed below observed counts
Chi-Square contributions are printed below expected counts
39 and
under
42
25.64
10.445
40 - 49
69
47.45
9.782
50 - 59
108
105.27
0.071
60 - 69
60
98.18
14.848
70
and
over
21
23.45
0.257
2
5
21.36
12.534
18
39.55
11.739
85
87.73
0.085
120
81.82
17.818
22
19.55
0.308
250
Total
47
87
193
180
43
550
1
Total
300
Chi-Sq = 77.887, DF = 4, P-Value = 0.000
The test statistic (77.887) is greater than the critical value obtained from Table 6, Appendix B (13.277) so
the null hypothesis is rejected. (Alternatively the P-Value (0.000) is less than the level of significance, α
(0.01) so the null hypothesis is rejected.)
54