Quantization Noise is 1
advertisement

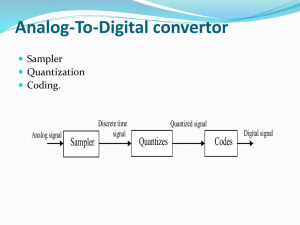
Waveform SpeechCoding Algorithms: An Overview Outline Introduction Concepts Quantization PCM DPCM ADPCM Standards & Applications G711 G726 Performance Comparison & Examples Summary & Conclusion Technical Presentation Page 2 Introduction Motivation What is Speech Coding ? It is the procedure of representing a digitized speech signal as efficiently as possible, while maintaining a reasonable level of speech quality. Why would we want to do that ? To Answer this, let’s have a look at the Structure of the Coding System Our Guy Technical Presentation Page 3 Introduction Motivation Filtering & Sampling (1) Technical Presentation Page 4 Introduction Motivation Filtering & Sampling (2) Technical Presentation Page 5 Introduction Motivation Filtering & Sampling (3) Technical Presentation Page 6 Introduction Motivation Filtering & Sampling (4) Most of the speech contents lies in between 300 – 3400 Hz According to Nyquist theorem Fs >= 2 fm (to avoid aliasing) A value of 8kHz is selected (8 >= 2*3.4). For good quality16 bits are used to represent each sample. Bit-rate = 8kHz *16 bits = 128 kbps Input Rate The Input rate could even be more, for example in Skype: 16 kHz sampling frequency is used in skype and so resulting to an input rate of 192 kBit/s. But, this is a waste of bandwidth that could rather be used by other services and applications. Source Coding (Speech Coding in this Context) [1] Technical Presentation Page 7 Introduction Motivation Desirable Properties of a Speech Coder Low Bit-Rate: By using a lower bit-rate, a smaller bandwidth for transmission is needed , leaving room for other services and applications . High Speech Quality: Speech quality is the rival of “low bit-rate”. It is important for the decoded speech quality to be acceptable for the target application. Low Coding Delays: The process of speech coding introduce extra delay, this might affect application that have real time requirements. [1] Technical Presentation Page 8 Introduction Speech Coding Categories What are the different Categories of speech coding ? Speech coding is divided into three different categories: Waveform Codecs (PCM, DM, APCM, DPCM, ADPCM) Vocoders (LPC, Homo-morphic, …etc ) Hybrid codecs (CELP, SELP, RELP, APC, SBC, … etc) [2] Technical Presentation Page 9 Concepts Quantization What Is Quantization ? Quantization is the process of transforming the sample amplitude of a message into a discrete amplitude from a finite set of possible amplitudes. [3] Each sampled value is approximated with a quantized pulse, the approximation will result in an error no larger than q/2 in the positive direction or –q/2 in the negative direction. Technical Presentation Page 10 Concepts Quantization Understanding Quantization To understand quantization a bit more let’s have a look at the following Example: Technical Presentation Page 11 Concepts Quantization Classification Of Quantization Process The Quantization process is classified as follows: Uniform Quantization: The representation levels are equally spaced (Uniformly spaced) Midtread type Midrise type Non-Uniform Quantization: The representation levels have variable spacing from one another . [4] But why do we need such classification ?! Technical Presentation Page 12 Concepts Quantization Human Speech – Excursion & Recap (1) Speech can broken into two different categories: Voiced (zzzzz) Un-Voiced (sssss) Naturally occurring speech signals are composed of a combination of the above categories, take the word “Goat” for example: [4] Goat contains two voiced signals followed by a partial closure of the vocal tract and then an Un-voiced signal. Those occurs at 3400-3900, 3900-5400, and 6300-6900, respectively. Technical Presentation Page 13 Concepts Quantization - why do we need such classification ?! (1) Human Speech – Excursion & Recap (2) It should be noted that: The peak-to-peak amplitude of voiced signals is approximately ten times that of un-voiced signal. Un-voiced signals contain more information, and thus higher entropy than voiced signals. The telephone system must provide higher resolution for lower amplitude signals Probability of occurrence Statistics of Speech Signals : Amplitude of speech signals Technical Presentation Page 14 [3] [6] Concepts Quantization - why do we need such classification ?! - (2) Quantization Noise The Quantization process is lossy (errorneous). An error defined as the difference between the input signal M and the output signal V. This error E is called the Quantization Noise. Consider the simple example: M = (3.117, 4.56, 2.31, 7.82, 1) V = (3,3,2,7,2) E = M – V = (0.117 ,1.561, 0.31, 0.89, 1) How do we calculate the noise power ? Consider an input m of continuous amplitude of the range (-M_max, M_max) Assume a uniform Quantizer, how do we get the Quantization Noise Power 1 Technical Presentation Page 15 Concepts Quantization - why do we need such classification ?! - (3) Comparison – Uniform Vs. Non-Uniform Usage Speech signals doesn’t require high quantization resolution for high amplitudes (50% Vs. 15%). wasteful to use uniform quantizer ? The goal is decrease the SQNR, more levels for low amplitudes, less levels for high ones. Maybe use a Non-uniform quantizer ? [3] Technical Presentation Page 16 Concepts Quantization More About Non-Uniform Quantizers (Companding) Uniform quantizer = use more levels when you need it. The human ear follows a logarithmic process in which high amplitude sound doesn’t require the same resolution as low amplitude sounds. One way to achieve non-uniform quantization is to use what is called as “Companding” Companding = “Compression + Expanding” Compressor Function Uniform Quantization Expander Function (-1) Technical Presentation Page 17 Concepts Quantization What is the purpose of a Compander ? The purpose of a compander is to equalize the histogram of speech signals so that the reconstruction levels tend to be equally used. [6] There are two famous companding techniques that Follow the Encoding law A-Law Companding µ-Law Companding Technical Presentation Page 18 [6] 2 Concepts Quantization A-Law Encoding µ-Law Encoding [3] Technical Presentation Page 19 Concepts Quantization Companding Approximation Logarithmic functions are slow to compute, why not approximate ? 3 bits, 8 segments ( chords ) to approximate P is the sign bit of the output S’s are the segment code Q’s are the quantization codes [3] Technical Presentation Page 20 Concepts Quantization Companding Approximation – Algorithm Encoding Add a bias of 33 to the absolute value of the input sample Determine the bit position of the most significant among bits 5 to 12 of the input Subtract 5 from that position, and this is the Segment code Finally, the 4 bit quantization code is set to 4 bits after the bit position of the most significant among bits 5 to 12 Decoding Multiply the quantization code by 2 and add 33 the bias to the result Multiply to the result by 2 raised to the power of the segment code Decrement the result by the bias Use P – bit to determine the sign of the result Example ?! [3] Technical Presentation Page 21 Concepts Quantization µ-Law Encoding - Example Example Input - 656 P S2 S1 S3 Q3 Q4 Q5 Q6 1 1 0 0 0 1 0 1 Sample is negative so bit P becomes 1 Add 33 to the absolute value to bias high input values (due to wrapping) The result after adding is 689 = 0001-0101-10001 The most-significant 1 bit in position 5 to 12 is at position 9 Subtracting 5 from the position values yields 4 The segment code Finally the 4 bits after the last position are inserted as the quantization code Technical Presentation Page 22 Concepts Quantization µ-Law Decoding - Example Example Input - 656 P S2 S1 S3 Q3 Q4 Q5 Q6 1 1 0 0 0 1 0 1 The quantization code is 101 = 5, so 5*2 +33 =43 The segment code is 100 = 4 , so 43* 2^4 = 688. Decrement the Bias 688 -33 =655 But P is 1 so the final result is -655 Quantization Noise is 1 (Very small) Technical Presentation Page 23 Concepts Quantization µ-Law Encoding Approximately linear for smaller values & Logarithmic for high input values The practically used values for µ is 255 Used for speech signals Used for PCM telephone systems in US, Canada and Japan A-Law Encoding Linear segments for low level inputs & a logarithmic segment for high level inputs The practically used values for A is 100 Used for PCM telephone system in Europe Technical Presentation Page 24 Concepts Pulse Code Modulation (PCM) PCM Description Sampling results in PAM PCM uniformly quantizes PAM The result of PCM are PCM words Each PCM word is l= Log2 (L) bits [3] Technical Presentation Page 25 Concepts Differential Pulse Code Modulation (DPCM) DPCM Description Signals that are sampled at a high rate have high correlation. The difference between those samples will not be large Instead of quantizing each sample, why not quantize the difference ? This will result in a quantizer with much less number of bits [7] This is a simple form where (First Order) More than one signal can be used in the prediction (N-Order) Problems with this approach ? Technical Presentation Page 26 [7] Concepts Differential Pulse Code Modulation (DPCM) DPCM Example [7] It is clear here from the table that the error adds up to produce an output signal which is completely different from the original one Technical Presentation Page 27 Concepts Differential Pulse Code Modulation (DPCM) DPCM Prediction Previously, input to predictor in the encoder was different than the one in the decoder. The difference between the predictor led to reconstruction error e(n) = x[n] – x’[n]. To solve this problem completely the same predictor that was used in the decoder will also be used in the decoder Channel Therefore the reconstruction error at the decoder output will be the same as the quantization error at the encoder. There will be no quantization accumulation. Technical Presentation Page 28 Concepts Adaptive Differential Pulse Code Modulation (ADPCM) ADPCM Description As can be inferred from the name, ADPCM combines PCM + DPCM and adds the ADPCM The “A” in ADPCM stands for “Adaptive” In DPCM, the difference between x[k] and x[k-1] is transmitted instead of x[k] To further reduce the number of bits per sample, ADPCM adapts the quantization levels to the characteristics of the analog signal . Original 32-Kbps ADPCM used 4 bits [9] Technical Presentation Page 29 Standards, Examples & Applications G711 G711 Description A Wave form codec that was Released in 1972 Formal name is Pulse Code Modulation (PCM) since it uses PCM in it’s encoding G711 achieves 64 kbps bit rate (8 kHz sampling frequency x 8 bits per sample) G711 defines two main compression algorithms A-Law (Used in North America & Japan) µ-Law (Used in Europe and the rest of the world) A and µ laws takes as an input 14-bit and 13-bit signed linear PCM samples and Compress them to 8-bit samples Applications Public Switching Telephone Network (PSTN) WiFi phones VoWLAN Wideband IP Telephony Audio & Video Conferencing H.320 & H.323 specifications Technical Presentation Page 30 Standards, Examples & Applications G726 G726 Description G726 makes a conversion of a 64 kbps A-law or µ-law PCM channel to and from a 40, 32, 24 or 16 kbps channel. The conversion is applied to raw PCM using the ADPCM Encoding Technique Different rates are achieved by adapting the number of quantization levels 4 - levels (2 bits and 16 kbps) 7 - levels (3 bits and 24 kbps) 15 - levels (4 bits and 32 kbps) 31 - levels (5 bits and 64 kbps) Includes G721 and G723 [12] Technical Presentation Page 31 Performance Comparison [1] Technical Presentation Page 32 Summary & Conclusion Summary We talked about quantization concepts in all it’s flavors We discussed about the category of waveform coding (PCM,DPCM and ADPCM) We presented the ITU Standards (G711 and G726) and mentioned some examples and applications Finally we did a comparison the most prominent speech codec's out there. Conclusion Speech coding Is an important concept that is required to efficiently use the existing bandwidth There exist many important metrics to keep in mind when doing speech coding. It is I important for a good speech coder to balance those metrics. The Most important ones are Data Rate Speech Quality Delay Waveform codec's, achieves the best speech quality as well as low delays. Vocoders achieves low data rate but at the cost of delays and speech quality Hybrid coders achieves acceptable speech quality and acceptable delay and data rate. Technical Presentation Page 33 References 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. Wai C. Chu Speech Coding Algorithms: Foundation & Evolution of Standardized Coders Speech Coding: http://www-mobile.ecs.soton.ac.uk/speech_codecs/ Sklar: Digital Communication Fundamentals And Applications. A-Law and mu-Law Companding Implementations Using the TMS320C54x Michael Langer: Data Compression – Introduction to lossy compression Signal Quantization and Compression Overview http://www.ee.ucla.edu/~dsplab/sqc/over.html Wajih Abu-Al-Saud: Ch. VI Sampling & Pulse Code Mod. Lecture 25 Yuli You: Audio Coding: Theory And Applications Tarmo Anttalainen: Introduction to telecommunication Networks Engineering Wikipedia G711: http://en.wikipedia.org/wiki/G.711 David Salomon: Data Communication the Complete Reference ITU CCIT Recommendation G.726 ADPCM Technical Presentation Page 34 Questions & Discussion Thank you!! Technical Presentation Page 35