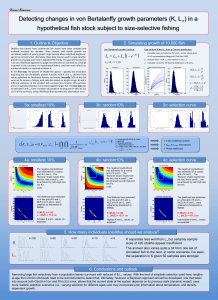
A Modified SLM Scheme With Low Complexity for PAPR Reduction
advertisement

2011 Summer Training Course ESTIMATION THEORY Chapter 7 Maximum Likelihood Estimation Wireless Information Transmission System Lab. Institute of Communications Engineering National Sun Yat-sen University Outline ◊ Why use MLE? ◊ How to find the MLE? ◊ Properties of MLE ◊ Numerical Determination of the MLE 2 Introduction ◊ We now investigate an alternative to the MVU estimator, which is desirable in situations where the MVU estimator does not exist or cannot be found even if it does exist. ◊ This estimator, which is based on the maximum likelihood principle, is overwhelmingly the most popular approach to obtaining practical estimator. ◊ It has the distinct advantage of being a turn-the-crank procedure, allowing it to be implemented for complicated estimation problems. 3 ◊ In general, the MLE has the asymptotic properties of being unbiased, achieving the CRLB, and having a Gaussian PDF. 4 Why use MLE? ◊ Example 7.1 - DC Level White Gaussian Noise ◊ Consider the observed data set ◊ where A is an unknown level , which is assumed to be positive (A > 0) , and is WGN with unknown variance A ( ). The PDF is : p x; A 1 2 A N 2 2 1 N 1 exp x n A . 2 A n 0 5 (7.1) ◊ Taking the derivative of the log-likelihood function, we have: ln p x; A N 1 N 1 1 x n A 2 A 2 A A n 0 2A ? N 1 x n A 2 n 0 I A Aˆ A . ◊ We can still determine the CRLB for this problem to find that: var ˆ ◊ 1 2 ln p x; E 2 var Aˆ A2 . 1 N A 2 (7.2) We next try to find the MVU estimator by resorting to the theory of sufficient statistics. 6 ◊ ◊ ◊ Sufficient statistics p x; g T x , h x Theorem 5.1(p.104) Theorem 5.2(p.109) ◊ If is an unbiased estimator of and is a sufficient statistic for then is I. A valid estimator for ( not dependent on ) II. Unbiased III. Of lesser or equal variance than that of , for all . Additionally, if the sufficient statistic is complete, then is the MVU estimator. In essence, a statistic is complete if there is only one function of the statistic that is unbiased Cont. ◊ First approach: Use Theorem 5.1 ◊ Two steps: ◊ First step: Find g T x , h x ˆ = g(T) is an unbiased ◊ Second step:Find function g so that A estimator of A ◊ First step: ◊ Attempting to factor (7.1) into the form of (5.3),we note that ◊ so that the 2 1 N 1 1 N 1 2 x n A x n 2 Nx NA A n 0 A n 0 1 N 1 x n0 x n PDF factor as N p x; A 1 2 A N 2 1 1 N 1 2 exp x n NA exp Nx h x 2 A n 0 N 1 2 g x n , A n 0 ◊ Based on the Neyman-Fisher factorization theorem a single sufficient statistic for A is . ◊ Second step: ◊ Assuming that is a complete sufficient statistic . To do so we need to find a function g such that N 1 2 E g x n A n 0 for all A 0 since N 1 2 E x n NE x 2 n n 0 N var x n E 2 x n N A A2 ◊ It is not obvious how to choose g . ◊ ◊ ◊ Second approach:Use Theorem 5.2 Example:Let Aˆ x 0 , then the MVU estimator would take the form N 1 2 E x 0 x n n 0 ◊ N 1 It would be to determine the conditional expectation E Aˆ n0 x2 n where Aˆ is any unbiased estimator. Unfortunately , the evaluation of the conditional expectation appears to be a formidable task. ◊ Example 7.2 - DC level in White Gaussian Noise ◊ We propose the following estimator: N 1 1 1 1 2 Aˆ x n . 2 N n 0 4 ◊ (7.6) This estimator is biased since 1 ˆ E A E 2 1 N 1 x n 4 n0 1 1 E 2 N 1 2 x n n0 4 N 1 2 N 1 1 1 A A2 2 4 A. ◊ As ,we have by the law of large number 1 N 1 2 2 2 x n E x n A A N n 0 and therefore from (7.6) Aˆ A ◊ ◊ To find the mean and variance of Aˆ as we use the statistical linearization argument described in section 3.6 . Section 3.6 is a estimator of DC level ( ) ◊ ◊ It might be supposed that is efficient for . Let .If we linearize about A , we have the approximation dg A g x g A x A . dA Then ,the estimator is unbiased. E g x g A A2 Also, the estimator achieves the CRLB dg A var g x var x dA 2 2 A 2 N 4 A2 2 N 2 1 N 2 x n n 0 N 1 2 is an estimator of A A . ◊ The ◊ Let g be that function , so that Aˆ g u where u 1 N 2 x n , n 0 N 1 and therefore, N 1 1 1 1 2 Aˆ x n . 2 N n 0 4 1 1 g u u . 2 4 ◊ Linearizing about u0 E u A A2 ,we have dg u g u g u0 |u u u u0 du or 0 N 1 1 2 2 Aˆ A x n A A A 12 N n0 1 2 (7.7) ◊ It now follows that the asymptotic mean is E Aˆ A so that Aˆ is asymptotically unbiased . Additionally , the asymptotic variance becomes , from (7.7) 2 N 1 1 1 2 2 var Aˆ var x n N 1 A n 0 2 ◊ 1 4 N A 12 2 var x 2 n . But var x 2 n can be shown to be 4 A3 2 A2 (prove is in next page), so that 1 var Aˆ N A 12 A2 N A 12 1 4A A 2 2 4 2 (asymptotically efficient) by p.574: If x N 0, x2 , then the moments of x are 1 3 k Ex k 1 x2 0 k2 k even k odd EX 7.1: x[n] A w[n] n 0,1,..., N -1 w ~ N (0, A). 4 E x 4 n E A w E A4 4 A3 w 6 A2 w2 4 Aw3 w4 A4 0 6 A2 A 0 3 A 2 var x 2 n E x 4 n E 2 x 2 n A4 6 A3 3 A2 and E x 2 n var x n E 2 x 2 n A A2 var x 2 n A4 6 A3 3 A2 A A2 2 A4 6 A3 3 A2 A4 2 A3 A2 4 A3 2 A2 # ◊ Summarizing our result : a. The proposed estimator given by (7.6) is asymptotically unbiased and asymptotically achieves the CRLB .Hence , it is asymptotically efficient. b. Furthermore , by the central limit theorem the random variable is Gaussian as . Because Aˆ is a linear function of this Gaussian random variable for large data records , it too will have a Gaussian PDF. (ex: , , y is Gaussian.) 7.4 How to find the MLE? ◊ The MLE for a scalar parameter is defined to be the value of that maximizes for x is fixed, i.e. , the value that maximizes the likelihood function. ◊ Since will also be a function of x ,the maximization produces a that is a function of x. ◊ Example 7.3 - DC Level in white Gaussian Noise ◊ where ◊ is WGN with unknown variance A. To actually find the MLE for this problem we first write the PDF from (7.1) as p x; A ◊ 1 2 A N 2 2 1 N 1 exp x n A 2 A n 0 Differentiating the log-likelihood function , we have ln p x; A 2 N 1 N 1 1 N 1 x n A 2 x n A A 2 A A n 0 2 A n 0 ◊ Setting it equal to zero produces ◊ We choose the solution to correspond to the permissible range of A or A>0. ◊ Not only does the maximum likelihood procedure yield an estimator that is asymptotically efficient , it also sometimes yields an efficient estimator for finite data records. ◊ Example 7.4 - DC Level in white Gaussian Noise ◊ For the received data where A is the unknown level to be estimated and WGN with known variance , the PDF is p x; A ◊ 1 2 2 N 2 is 2 1 N 1 exp 2 x n A 2 n0 Taking the derivative of the log-likelihood function produces ln p x; A 1 N 1 2 x n A A n 0 ◊ Which being set equal to zero yields the MLE N 1 1 Aˆ x n N n 0 ◊ This result is true in general . If an efficient estimator exists , the maximum likelihood procedure will produce it. proof: 因為efficient estimator 存在,所以 依照maximum likelihood procedure , 令 得 7.5 Properties of the MLE ◊ The example discussed in Section 7.3 led to an estimator that for large data records was unbiased , achieved the CRLB ,and had a Gaussian PDF ,the MLE was distributed as ˆ N , I 1 a (7.8) ◊ Invariance property (MLE for transformed parameters). ◊ Of course , in practice it is seldom known in advance how large N must be in order for (7.8) to hold. ◊ An analytical expression for the PDF of the MLE is usually impossible to derive. As an alternative means of assessing performance, a computer simulation is usually required. ◊ Example 7.5 - DC Level in white Gaussian Noise ◊ A computer simulation was performed to determine how large the data record had to be for the asymptotic results to apply. ◊ In principle the exact PDF of would be extremely tedious. (see (7.6)) could be found but N 1 1 1 1 2 ˆA x n 2 N n 0 4 (7.6) ◊ Using the Monte Carlo method ,M=1000 realizations of were generated for various data record lengths. The mean and variance were estimated by ◊ Instead of the CRLB of (7.2),we tabulate ◊ 2 A N var Aˆ A 12 ◊ 2 A var Aˆ . N A 12 (7.2) For a value of A equal to 1 the results are shown in Table 7.1. ◊ To check this the number of realizations was increased to M=5000 for a data record length of N=20.This resulted in the mean and normalized variance shown in parentheses. ◊ Next , the PDF of was determined using a Monte Carlo Computer simulation .This was done for data record lengths of N=5 and N=20 (M=5000). Theorem 7.1 ◊ Theorem 7.1 (Asymptotic Properties of the MLE) If the PDF p(x; θ) of the data x satisfies some “regularity” conditions, then the MLE of the unknown parameter θ is asymptotically distributed (for large data records) according to ˆ N , I 1 a where I(θ) is the Fisher information evaluated at the true value of the unknown parameter. 2 ln p x; I E 2 ◊ Regularity condition: 2 ln p x; E 0 2 for all ◊ From the asymptotic distribution, the MLE is seen to be asymptotically unbiased and asymptotically attains the CRLB. ◊ It is therefore asymptotically efficient, and hence asymptotically optimal. 7.5 Properties of the MLE Cont. ◊ Example 7.6 – MLE of the Sinusoidal Phase ◊ We wish to estimate the phase of a sinusoid embedded in noise or x n A cos 2 f0n wn n 0,1, , N 1 where w[n] is WGN with variance σ2 and the amplitude A and frequency f0 are assumed to be known. ◊ We saw in Chapter 5 that no single sufficient statistic exists for this problem. ◊ The sufficient statistics were N 1 T1 x x n cos 2 f 0 n n 0 N 1 T2 x x n sin 2 f 0 n . n 0 p x; 1 2 2 N 2 1 N 1 2 exp 2 A cos 2 2 f 0 n 2 AT1 x cos 2 AT2 x sin 2 n 0 g T1 x ,T2 x , 1 exp 2 2 2 x n n0 N 1 h x ◊ The MLE is found by maximizing p(x; ) or p x; 1 2 2 N 2 2 1 N 1 exp 2 x n A cos 2 f 0 n 2 n0 or, equivalently, by minimizing N 1 J x n A cos 2 f 0 n . 2 n 0 ◊ Differentiating with respect to produces N 1 J 2 x n A cos 2 f 0 n A sin 2 f 0 n n 0 ◊ Setting it equal to zero yields x n sin 2 f n ˆ A sin 2 f n ˆ cos 2 f n ˆ . N 1 N 1 0 n 0 ◊ 0 n 0 0 But the right-hand side may be approximated since N 1 1 N 1 1 sin 2 f 0 n ˆ cos 2 f 0 n ˆ sin 4 f 0 n 2ˆ 0 N n 0 2 N n 0 for f0 not near 0 or 1/2. (P.33) sin 2 2sin cos ◊ Thus, the left-hand side when divided by N and set equal to zero will produce an approximate MLE, which satisfies sin(1 2 ) sin 1 cos2 cos1 sin 2 x n sin 2 f n ˆ 0. N 1 0 n 0 N 1 N 1 n 0 n 0 x n sin 2 f 0 n cos ˆ x n cos 2 f 0 n sin ˆ N 1 x n sin 2 f n ˆ arctan Nn 01 0 x n cos 2 f n n 0 0 . ◊ According to Theorem 7.1, the asymptotic PDF of the phase estimator is a ˆ N , I 1 . ◊ From Example 3.4 NA2 I 2 2 so that the asymptotic variance is var ˆ where A2 2 2 is 1 N A2 2 2 the SNR. 1 N ◊ To determine the data record length for the asymptotic mean and variance to apply we performed a computer simulation using A = 1, f0 = 0.08, = π/4, σ2 = 0.05. var<CRLB!! Maybe bias. ◊ We fixed the data record length N = 80 and varied the SNR. ◊ In Figure 7.4 we have plotted 10 log10 var ˆ . 1 ˆ 10log10 var 10log10 N 10log10 N 10log10 . ◊ The large error estimates are said to be outliers and cause the threshold effect. ◊ Nonlinear estimators nearly always exhibit this effect. ◊ In summary, the asymptotic PDF of the MLE is valid for large enough data records. ◊ For signal in noise problems the CRLB may be attained even for short data records if the SNR is high enough. ◊ To see why this is so the phase estimator can be written as example 7.6 N 1 ˆ arctan A cos 2 f n w n sin 2 f n n 0 N 1 0 0 A cos 2 f n w n cos 2 f n n 0 0 N 1 NA sin w n sin 2 f 0 n 2 n0 arctan N 1 NA cos w n cos 2 f 0 n 2 n 0 0 1 N sin 2 f n ˆ cos 2 f n ˆ N 1 0 n 0 1 2N 0 sin 4 f n 2ˆ 0 N 1 n 0 0 2 N 1 sin w n sin 2 f 0 n NA n 0 ˆ arctan . N 1 2 cos w n cos 2 f 0 n NA n 0 ◊ If the data record is large and/or the sinusoidal power is large, the noise terms is small. It is this condition, the estimation error will be small, that allows the MLE to attain its asymptotic distribution. ◊ In some cases the asymptotic distribution does not hold, no matter how large the data record and/or the SNR becomes. ◊ Example 7.7 – DC Level in Non-independent NonGaussian Noise ◊ Consider the observations ◊ ◊ ◊ The PDF is symmetric about w[n] =0 and has a maximum at w[n] = 0. Furthermore, we assume all the noise samples are equal or w[0]=w[1]=…=w[N-1]. In estimate A, we need to consider only a single observation (x[0]=A+w[0]) since all observation are identical. The MLE of A is the value that maximizes pw0 x 0 -A because px0 x 0 ; A pw0 x 0 A , we can get Aˆ x 0. This estimator has the mean E Aˆ E x 0 A . ◊ The variance of Aˆ is the same as the variance of x[0] or of w[0]. ˆ var A u 2 pw0 u du ◊ The CRLB (problem 3.2) dp u w 0 ˆ var A du p u w 0 ◊ 2 1 the two are not in general equal. (see Problem 7.16) So in this sample, the estimator error does not decrease as the data record length increase but remains the same. 7.6 MLE for Transformed Parameters Example 7.8 – Transformed DC Level in WGN ◊ ◊ ◊ Consider the data x n A wn n 0,1, , N 1 where w[n] is WGN with variance σ2. We wish to find the MLE of exp A The PDF is given as p x; A 1 2 2 N 2 2 1 N 1 exp 2 x n A 2 n0 A ◊ However, since α is a one-to-one transformation of A, we can equivalently parameterize the PDF as 1 pT x; ◊ ◊ 1 exp 2 2 x n ln n 0 N 1 2 2 Clearly, pT x; is the PDF of the data set 2 N 2 x n ln wn n 0,1, 0 , N 1 Setting the derivative of pT x; with respect to α equal to zero yields N 1 x n ln ˆ n 0 1 0 or ˆ exp x . ˆ ◊ But x is just the MLE of A, so that ˆ exp Aˆ exp ˆ . ◊ The MLE of the transformed parameter is found by substituting the MLE of the original parameter in to the transformation. ◊ This property of the MLE is termed the invariance property. ◊ Example 7.9 – Transformed DC Level in WGN ◊ ◊ ◊ Consider the transformation A2 for the data set in the previous example. Attempting to parameterize p(x;A) with respect to α, we find that since the transformation is not one-to-one. A If we choose A , then some of the possible PDFs will be missing. ◊ We actually require two sets of PDFs (7.23) 1 1 p x; exp x n A0 2 2 N 1 T1 2 pT2 x; N 2 1 2 1 exp 2 2 2 n 0 N 1 x n 2 to characterize all possible PDFs. ◊ 2 N 2 n 0 2 A0 It is possible to find the MLE of α as the value of α that yields the maximum of pT x; and pT x; or 2 1 ˆ arg max pT x; , pT x; 1 2 ◊ Alternatively, we can find the maximum in two steps as ◊ For a given value of , say 0 , determine whether pT x; or pT x; is large. For example, if 1 pT1 x;0 pT2 x;0 then denote the value of pT1 x;0 as pT x;0 . Repeat for all 0 to form pT x; . The MLE is given as the that maximizes pT x; over 2 ◊ 0. Construction of modified likelihood function ◊ ◊ The function pT x; can be thought of as a modified likelihood function, having been derived from the original likelihood function by transforming the value of A that yields the maximum value for a given . The MLE ˆ is: arg max p x; , p x; ˆ arg max p x; , p x; 0 0 arg max p x; A A Aˆ 2 x2 2 2 Theorem 7.2 ◊ Theorem 7.2 (Invariance Property of the MLE) ◊ The MLE of the parameter α= g (θ), where the PDF p(x;θ) is parameterized by θ, is given by ˆ g ˆ where ˆ is the MLE of θ. The MLE of ˆ is obtained by maximizing p(x;θ). ◊ If g is not a one-to-one function, then ˆ maximizes the modified likelihood function pT x; , defined as pT x; max p x; : g 7.6 MLE for Transformed Parameters Cont. ◊ Example 7.10 – Power of WGN in dB ◊ We observe N samples of WGN with variance σ2 whose power in dB is to be estimated. ◊ To do so we first find the MLE of σ2. Then, we use the invariance principle to find the power P in dB, which is defined as P 10log10 2 . ◊ The PDF is given by p x; 2 1 2 2 N 2 1 N 1 2 exp 2 x n 2 n 0 ◊ Differentiating the log-likelihood function produces ln p x; 2 2 ◊ N N 1 2 ln 2 ln 2 2 2 2 2 N 1 N 1 2 2 4 x n 2 2 n 0 2 x n n 0 N 1 Setting it equal to zero yields the MLE N 1 1 ˆ 2 x 2 n. N n 0 ◊ The MLE of the power in dB readily follows as Pˆ 10log10 ˆ 2 1 N 1 2 10log10 x n. N n 0 7.7 Numerical Determination of the MLE ◊ A distinct advantage of the MLE is that we can always find it for a given data set numerically. ◊ The safest way to find the MLE is to grid search, as long as the spacing between search is small enough, we are guaranteed to find the MLE ◊ ◊ If, however, the range is not confirmed to a finite interval, then a grid search may not be computationally feasible. We use iterative maximization procedures : ◊ Newton-Raphson method The scoring approach The expectation-maximization algorithm These methods will produce the MLE if the initial guess is close to the true maximum. If not, convergence may not be attained, or only convergence to a local maximum. The Newton-Raphson method ◊ This is a nonlinear equation and can not be solved directly. ◊ Consider: ln p x; 0. ◊ ln p x; g Guess 0: dg g g 0 0 d 0 dg g g 0 0 d 0 k 1 k g k dg d . k ◊ Note that at convergence k 1 k , we get g k 0 , 1 2 ln p x; ln p x; k 1 k 2 k ◊ ◊ ◊ The iteration may not converge ,when the second derivation of the log-likelihood function is small. The correct term may fluctuate wildly. Even if the iteration converges, the point found may not be the global maximum but only a local maximum or even a local minimum. Generally, if the initial point is close to the global maximum, the iteration will converge to it. The Method of Scoring ◊ ◊ A second common iterative procedure is the method of scoring, it recognizes that : 2 ln p x; I k 2 Proof: k 2 2 ln p x; N 1 ln p x n ; 2 2 n 0 1 N N N 1 n 0 2 ln p x n ; 2 ln p x n ; NE 2 Ni 2 I By the law of large numbers. ◊ So we get ln p x; k 1 k I . 1 k ◊ Example 7.11 – Exponential in WGN x n r n wn ◊ , N 1 the parameter r , the exponential factor, is to be estimated. p x; r ◊ n 0,1, 1 2 2 N 2 1 N 1 n 2 exp 2 x n r 2 n0 so, we want to minimize: N 1 J r x n r n 0 ◊ . n 2 differentiating and setting it equal to: N 1 x n r nr n n 0 n 1 0. Cont. ◊ Applying the Newton-Raphson iteration method: ln p x; r 1 N 1 2 x n r n nr n1 r n 0 N 1 2 ln p x; r 1 N 1 n2 2 n2 2 n n 1 x n r n 2n 1 x n r 2 r n 0 n 0 1 N 1 n 2 2 nr n 1 x n 2n 1 r n n 0 ◊ so we get N 1 n n 1 x n r nr k k rk 1 rk N 1 n 0 n2 n nr n 1 x n 2 n 1 r k k n 0 1 ln p x; ln p x; k 1 k 2 k 2 . ◊ Applying the method of scoring : I 1 2 N 1 1 n r 2 2 n2 ( n 0 N 1 n2 n ) nr n 1 x n 2 n 1 r 2 n 0 so that N 1 rk 1 rk x n r nr n0 n k N 1 2 2 n2 n rk n 0 n 1 k . Computer Simulation ◊ Consider J r ◊ ◊ ◊ ◊ Using N = 50, r = 0.5, We apply the Newton-Raphson iteration by using several initial guesses. (0.8 , 0.2 , and 1.2) For 0.2 and 0.8 the iteration quickly converged to the true maximum. However, for r0 = 1.2 the convergence was much slower with 29 iterations. If the initial guess was less than 0.18 or greater than 1.2, the succeeding iterates exceeded 1 and keep increasing, the Newton-Raphson iteration fails to converge. Conclusion ◊ ◊ If PDF is known, MLE can be used. With MLE, the unknown parameter is estimated by: ˆ arg max p x; Find a , which maximum the probability. where x is the vector of observed data. (N samples) ◊ Asymptotically unbiased: lim E ˆ . N ◊ Asymptotically efficient: lim var ˆ CRLB. N