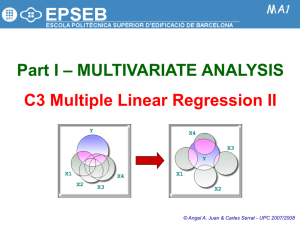
An Introduction to Multivariate Modeling Techniques
advertisement

Model Building Training Max Kuhn Kjell Johnson Global Nonclinical Statistics 1 Overview • Typical data scenarios – Examples we’ll be using • General approaches to model building • Data pre-processing • Regression-type models • Classification-type models • Other considerations 2 Typical Data R e sponse A (continuous) 1 -24.0 2 4.4 3 34.9 4 -55.5 5 -54.0 6 -64.7 7 13.7 8 -25.3 9 51.9 -8.3 10 ID R e sponse B A1 . . . (ca te gorica l) Active -29.8 . . . Active 4.8 . . . Active 75.3 . . . Inactive 33.1 . . . Inactive 118.1 . . . Inactive 1.3 . . . Active 97.9 . . . Inactive 24.7 . . . Active -13.5 . . . Inactive -3.5 . . . A92 B1 . . . B347 . . . K1 . . . K32 71.4 115.6 56.4 131.3 104.4 124.6 62.4 -27.3 35.6 -0.1 3 4 0 0 1 4 4 2 1 0 ... ... ... ... ... ... ... ... ... ... 0 0 12 0 5 1 6 0 3 4 • Response may be continuous or categorical • Predictors may be – continuous, count, and/or binary – dense or sparse – observed and/or calculated 3 ... ... ... ... ... ... ... ... ... ... 0 0 0 0 0 0 0 0 1 0 ... ... ... ... ... ... ... ... ... ... 1 0 0 0 0 0 0 0 1 0 Predictive Models • What is a “predictive model”? A model whose primary purpose is for prediction (as opposed to inference) • We would like to know why the model works, as well as the relationship between predictors and the outcome, but these are secondary • Examples: blood-glucose monitoring, spam detection, computational chemistry, etc. 4 What Are They Not Good For? • They are not a substitute for subject specific knowledge Science: Hard (yikes) Models: Easy (let’s do these instead!) • To make a good model that predicts well on future samples, you need to know a lot about – Your predictors and how they relate to each other – The mechanism that generated the data (sampling, technology etc) 5 What Are They Not Good For? • An example: An oncologist collects some data from a small clinical trial and wants a model that would use gene expression data to predict therapeutic response (beneficial or not) in 4 types of cancer There were about 54K predictors and data was collected on ~20 subjects • If there is a lot of knowledge of how the therapy works (pathways etc), some effort must be put into using that information to help build the model 6 The Big Picture “In the end, [predictive modeling] is not a substitute for intuition, but a compliment” Ian Ayres, in Supercrunchers 7 References • “Statistical Modeling: The Two Cultures” by Leo Breiman (Statistical Science, Vol 16, #3 (2001), 199-231) • The Elements of Statistical Learning by Hastie, Tibshirani and Friedman • Regression Modeling Strategies by Harrell • Supercrunchers by Ayres 8 Regression Methods • Multiple linear regression • Partial least squares • Neural networks • Multivariate adaptive regression splines • Support vector machines • Regression trees • Ensembles of trees: – Bagging, boosting, and random forests 9 Classification Methods • Discriminant analysis framework – Linear, quadratic, regularized, flexible, and partial least squares discriminant analysis • Modern classification methods – Classification trees – Ensembles of trees • Boosting and random forests – Neural networks – Support vector machines – k-nearest neighbors – Naive Bayes 10 Interesting Models We Don’t Have Time For • L1 Penalty methods – The lasso, the elasticnet, nearest shrunken centroids • Other Boosted Models – linear models, generalized additive models, etc • Other Models: – Conditional inference trees, C4.5, C5, Cubist, other tree models – Learned vector quantization – Self-organizing maps – Active learning techniques 11 Example Data Sets 12 Boston Housing Data • This is a classic benchmark data set for regression. It includes housing data for 506 census tracts of Boston from the 1970 census. • crim: per capita crime rate • • Indus: proportion of non-retail business acres per town dis: weighted distances to five Boston employment centers • rad: index of accessibility to radial highways • tax: full-value property-tax rate • ptratio: pupil-teacher ratio by town • b: proportion of minorities • Medv: median value homes (outcome) • • nox: nitric oxides concentration • rm: average number of rooms per dwelling • 13 chas: Charles River dummy variable (= 1 if tract bounds river; 0 otherwise) Age: proportion of owneroccupied units built prior to 1940 Toy Classification Example • A simulated data set will be used to demonstrate classification models – two predictors with a correlation coefficient of 0.5 were simulated – two classes were simulated (“active” and “inactive”) • A probability model was used to assign a probability of being active to each sample – the 25%, 50% and 75% probability lines are shown on the right 14 Toy Classification Example • The classes were randomly assigned based on the probability • The training data had 250 compounds (plot on right) – the test set also contained 250 compounds • With two predictors, the class boundaries can be shown for each model – this can be a significant aid in understanding how the models work – …but we acknowledge how unrealistic this situation is 15 Model Building Training General Strategies 16 Objective To construct a model of predictors that can be used to predict a response Data Model Prediction 17 Model Building Steps • Common steps during model building are: – estimating model parameters (i.e. training models) – determining the values of tuning parameters that cannot be directly calculated from the data – calculating the performance of the final model that will generalize to new data • The modeler has a finite amount of data, which they must "spend" to accomplish these steps – How do we “spend” the data to find an optimal model? 18 “Spending” Data • We typically “spend” data on training and test data sets – Training Set: these data are used to estimate model parameters and to pick the values of the complexity parameter(s) for the model. – Test Set (aka validation set): these data can be used to get an independent assessment of model efficacy. They should not be used during model training. • The more data we spend, the better estimates we’ll get (provided the data is accurate). Given a fixed amount of data, – too much spent in training won’t allow us to get a good assessment of predictive performance. We may find a model that fits the training data very well, but is not generalizable (overfitting) – too much spent in testing won’t allow us to get a good assessment of model parameters 19 Methods for Creating a Test Set • How should we split the data into a training and test set? • Often, there will be a scientific rational for the split and in other cases, the splits can be made empirically. • Several empirical splitting options: – completely random – stratified random – maximum dissimilarity in predictor space 20 Creating a Test Set: Completely Random Splits • A completely random (CR) split randomly partitions the data into a training and test set • For large data sets, a CR split has very low bias towards any characteristic (predictor or response) • For classification problems, a CR split is appropriate for data that is balanced in the response • However, a CR split is not appropriate for unbalanced data – A CR split may select too few observations (and perhaps none) of the less frequent class into one of the splits. 21 Creating a Test Set: Stratified Random Splits • A stratified random split makes a random split within stratification groups – in classification, the classes are used as strata – in regression, groups based on the quantiles of the response are used as strata • Stratification attempts to preserve the distribution of the outcome between the training and test sets – A SR split is more appropriate for unbalanced data 22 Over-Fitting • Over-fitting occurs when a model has extremely good prediction for the training data but predicts poorly when – the data are slightly perturbed – new data (i.e. test data) are used • Complex regression and classification models assume that there are patterns in the data. – Without some control many models can find very intricate relationships between the predictor and the response – These patterns may not be valid for the entire population. 23 Over-Fitting Example • The plots below show classification boundaries for two models built on the same data Predictor B Predictor B – one of them is over-fit Predictor A 24 Predictor A Over-Fitting in Regression • Historically, we evaluate the quality of a regression model by it’s mean squared error. • Suppose that are prediction function is parameterized by some vector 25 Over-Fitting in Regression • MSE can be decomposed into three terms: – irreducible noise – squared bias of the estimator from it’s expected value – the variance of the estimator • The bias and variance are inversely related – as one increases, the other decreases – different rates of change 26 Over-Fitting in Regression • When the model under-fits, the bias is generally high and the variance is low • Over-fitting is typically characterized by high variance, low bias estimators • In many cases, small increases in bias result in large decreases in variance 27 Over-Fitting in Regression • Generally, controlling the MSE yields a good trade-off between over- and under-fitting – a similar statement can be made about classification models, although the metrics are different (i.e. not MSE) • How can we accurately estimate the MSE from the training data? – the naïve MSE from the training data can be a very poor estimate • Resampling can help estimate these metrics 28 How Do We Estimate Over-Fitting? • Some models have specific “knobs” to control over-fitting – neighborhood size in nearest neighbor models is an example – the number if splits in a tree model • Often, poor choices for these parameters can result in over-fitting • Resampling the training compounds allows us to know when we are making poor choices for the values of these parameters 29 How Do We Estimate Over-Fitting? • Resampling only affects the training data – the test set is not used in this procedure • Resampling methods try to “embed variation” in the data to approximate the model’s performance on future compounds • Common resampling methods: – K-fold cross validation – Leave group out cross validation – Bootstrapping 30 K-fold Cross Validation • Here, we randomly split the data into K blocks of roughly equal size • We leave out the first block of data and fit a model. • This model is used to predict the held-out block • We continue this process until we’ve predicted all K hold-out blocks • The final performance is based on the hold-out predictions 31 K-fold Cross Validation • The schematic below shows the process for K = 3 groups. – K is usually taken to be 5 or 10 – leave one out cross-validation has each sample as a block 32 Leave Group Out Cross Validation • A random proportion of data (say 80%) are used to train a model • The remainder is used to predict performance • This process is repeated many times and the average performance is used 33 Bootstrapping • Bootstrapping takes a random sample with replacement – the random sample is the same size as the original data set – compounds may be selected more than once – each compound has a 63.2% change of showing up at least once • Some samples won’t be selected – these samples will be used to predict performance • The process is repeated multiple times (say 30) 34 The Bootstrap • With bootstrapping, the number of heldout samples is random • Some models, such as random forest, use bootstrapping within the modeling process to reduce over-fitting 35 Training Models with Tuning Parameters • A single training/test split is often not enough for models with tuning parameters • We must use resampling techniques to get good estimates of model performance over multiple values of these parameters • We pick the complexity parameter(s) with the best performance and re-fit the model using all of the data 36 Simulated Data Example • Let’s fit a nearest neighbors model to the simulated classification data. • The optimal number of neighbors must be chosen • If we use leave group out cross-validation and set aside 20%, we will fit models to a random 200 samples and predict 50 samples – 30 iterations were used • We’ll train over 11 odd values for the number of neighbors – we also have a 250 point test set 37 Toy Data Example • The plot on the right shows the classification accuracy for each value of the tuning parameter – The grey points are the 30 resampled estimates – The black line shows the average accuracy – The blue line is the 250 sample test set • It looks like 7 or more neighbors is optimal with an estimated accuracy of 86% 38 Toy Data Example • What if we didn’t resample and used the whole data set? • The plot on the right shows the accuracy across the tuning parameters • This would pick a model that over-fits and has optimistic performance 39 Model Building Training Data Pre-Processing 40 Why Pre-Process? • In order to get effective and stable results, many models require certain assumptions about the data – this is model dependent • We will list each model’s pre-processing requirements at the end • In general, pre-processing rarely hurts model performance, but could make model interpretation more difficult 41 Common Pre-Processing Steps • For most models, we apply three pre-processing procedures: – Removal of predictors with variance close to zero – Elimination of highly correlated predictors – Centering and scaling of each predictor 42 Zero Variance Predictors • Most models require that each predictor have at least two unique values • Why? – A predictor with only one unique value has a variance of zero and contains no information about the response. • It is generally a good idea to remove them. 43 “Near Zero Variance” Predictors • Additionally, if the distributions of the predictors are very sparse, – this can have a drastic effect on the stability of the model solution – zero variance descriptors could be induced during resampling • But what does a “near zero variance” predictor look like? 44 “Near Zero Variance” Predictor • There are two conditions for an “NZV” predictor – a low number of possible values, and – a high imbalance in the frequency of the values • For example, a low number of possible values could occur by using fingerprints as predictors – only two possible values can occur (0 or 1) • But what if there are 999 zero values in the data and a single value of 1? – this is a highly unbalanced case and could be trouble 45 NZV Example • In computational chemistry we created predictors based on structural characteristics of compounds. # 11-Member Rings • As an example, the descriptor “nR11” is the number of 11member rings • The table to the right is the distribution of nR11 from a training set – the distinct value percentage is 5/535 = 0.0093 – the frequency ratio is 501/23 = 21.8 46 Value Frequency 0 501 1 4 2 23 3 5 4 2 Detecting NZVs • Two criteria for detecting NZVs are the – Discrete value percentage • Defined as the number of unique values divided by the number of observations • Rule-of-thumb: discrete value percentage < 20% could indicate a problem – Frequency ratio • Defined as the frequency of the most common value divided by the frequency of the second most common value • Rule-of-thumb: > 19 could indicate a problem • If both criteria are violated, then eliminate the predictor 47 Highly Correlated Predictors • Some models can be negatively affected by highly correlated predictors – certain calculations (e.g. matrix inversion) can become severely unstable • How can we detect these predictors? – Variance inflation factor (VIF) in linear regression or, alternatively 1. Compute the correlation matrix of the predictors 2. Predictors with (absolute) pair-wise correlations above a threshold can be flagged for removal 3. Rule-of-thumb threshold: 0.85 48 Highly Correlated Predictors and Resampling • Recall that resampling slightly perturbs the training data set to increase variation • If a model is adversely affected by high correlations between predictors, the resampling performance estimates can be poor in comparison to the test set – In this case, resampling does a better job at predicting how the model works on future samples 49 Centering and Scaling • Standardizing the predictors can greatly improve the stability of model calculations. • More importantly, there are several models (e.g. partial least squares) that implicitly assume that all of the predictors are on the same scale • Apart from the loss of the original units, there is no real downside of centering and scaling 50 Model Building Training Regression-type Models 51 Setting Variables Pred. 1 Obs 1 3.231 Obs 2 5.249 Obs 3 7.534 ... Obs n 6.878 Pred. 2 99.30 63.78 84.53 77.21 ... Pred. p 20104 30128 10021 Response 8.322 5.995 7.756 50249 3.490 Response is continuous 52 Objective To construct a model of predictors that can be used to predict a response Data Model Prediction 53 Regression Methods • Multiple linear regression • Partial least squares • Neural networks • Multivariate adaptive regression splines • Support vector machines • Regression trees • Ensembles of trees: – Bagging, boosting, and random forests • Each of these methods seek to find a relationship between the predictors and response that minimizes error between the observed and predicted response 54 Additive Models In the beginning there were linear models: EY 0 1 X1 p X p And Nelder and Wedderburn (1972) said, “Let there be Generalized Linear Models”: gEY 0 1 X1 p X p and link functions appeared. And Hastie and Tibshirani (1990) said, “Let there be Generalized Additive Models”: EY f 0 f1 X1 f p X p 55 and scatterplot smoothers and backfitting algorithms appeared. Families of Additive Models GLM - Flexibility Recursive Partitioning (Trees) PLS Bagging Boosting + Multivariate Adaptive Regression Splines* Random Forests GAM * Additivity depends on model parameters 56 Neural Nets Support Vector Machines* Assessing Model Performance 57 Assessing Model Performance • How well does a regression model perform? Answering this question depends on how we want to use the model. Possible goals are: – To understand the relationship between the predictor and the response. – To use the model to predict future observations’ response. • In either case, we can use several of different measures to evaluate model performance. We will focus on two: – Coefficient of determination (R2) – Root mean square error (RMSE) • However, the set of data that we use to evaluate performance will change depending on our purpose. 58 Which Set of Data to Use to Evaluate Performance? • If we are only interested in understanding the underlying relationship between the predictor and the response, then we can compute R2 and RMSE on the data for which the model was built (i.e the training data). – However, these values will be overly optimistic of the model’s ability to predict future observations. • If we are interested in understanding the model’s ability to predict future observations, then we need to compute R2 and RMSE on data for which the model was not built (i.e. a test set or cross-validation set). – For a held-out set of data, R2 is commonly referred to as Q2 and RMSE is commonly referred to as root mean squared prediction error (RMSPE) 59 Root Mean Squared Error (RMSE) and Root Mean Squared Prediction Error (RMSPE) • RMSE measures the average deviation of an observation to the best-fit plane SSE RMSE n p 1 • RMSPE measures the average deviation of an observation to its predicted value for the test or crossvalidation set n* RMSPE 2 ˆ y y i i i 1 n * n* = the number of observations in the test or cross-validation set 60 Computing Q2 • Process: – Partition the data into • a training and testing set, or • blocks to be used for training and testing – Build the model on the training data and predict the testing data • Q2 = R2 of the relationship between the observed and predicted values for the testing data. 61 Multiple Linear Regression: A Quick Review 62 Multiple Linear Regression Variables Pred. 1 Obs 1 3.231 Obs 2 5.249 Obs 3 7.534 ... Obs n 6.878 Pred. 2 99.30 63.78 84.53 77.21 ... Pred. p 20104 30128 10021 Response 8.322 5.995 7.756 50249 3.490 Objective: Find the plane through the data that minimizes the sum-of-squares error. 63 The Best Plane • To find the best plane, we solve: min Y X 2 – where Ynx1, Xnx(p+1) and β(p+1)x1 • The best β is: ˆ0 ˆ1 1 T T X X X Y ˆ p 64 Aside: A Bit More About (XTX) • (XTX) is a critical matrix for many statistical modeling techniques • A few fun facts… – (XTX) is proportional to the covariance matrix, S – S contains the variances and covariances of all predictors – Techniques that depend on (XTX) also require that it is invertible 65 Assumptions: Diagnostic Plots 66 When Does Regression Fail? • When a plane does not capture the structure in the data • When the variance/covariance matrix is overdetermined – Recall, the plane that minimizes SSE is: 1 T T ˆ X X X Y – To find the best plane, we must compute the inverse of the variance/covariance matrix – The variance/covariance matrix is not always invertible. Two common conditions that cause it to be uninvertible are: • Two or more of the predictors are correlated (multicollinearity) • There are more predictors than observations 67 A (Trivial) Example of Multicollinearity Suppose that we have one observation (3,5), and we wish to find the ‘best’ line for the data. In this example, the number of observations (1) is less than the number of parameters (2: slope and intercept). When the number of parameters is greater than the number of observations, we can find an infinite number of ‘best’ solutions. Solution 1 7 6 Solution 2 5 Y 4 Solution 3 3 2 In the presence of multicollinearity, the best solution will be unstable. 1 0 0 1 2 3 4 5 X 68 6 7 8 9 10 Boston Housing Data • Let’s use a linear regression model to predict the median house price in Boston. • Process: – Split the data into a training set (n = 337) and testing set (n = 169) – For the training set, use the bootstrap to determine the RMSPE and Q2 – For the test data determine RMSPE and Q2 • If the underlying model is stable, the values of RMSPE and Q2 should be similar between the bootstrap and testing data 69 Results Training Data (bootstrap) Linear Reg Test Data RMSE Q2 RMSE R2 5.23 0.691 4.53 0.742 • The results are fairly similar, at least within the variation of resampling • One reason you may see differences: multicollinearity – Multicollinearity in the predictors can produce somewhat unstable solutions for each resample – When the data are slightly changed, the model can drastically change • The test set is a single, static set of data for verification – The bootstrap estimate of performance may be better with collinearity 70 Partial Least Squares Regression 71 Solutions for Overdetermined Covariance Matrices • Variable reduction – Try to accomplish this through the pre-processing steps • Partial least squares (PLS) • Other methods – Apply a generalized inverse – Ridge regression: Adjusts the variance/covariance matrix so that we can find a unique inverse. – Principal component regression (PCR) • not recommended—but it’s a good way to understand PLS 72 Understanding Partial Least Squares: Principal Components Analysis • PCA seeks to find linear combinations of the original variables that summarize the maximum amount of variability in the original data – These linear combinations are often called principal components or scores. – A principal direction is a vector that points in the direction of maximum variance. 73 Principal Components Analysis • PCA is inherently an optimization problem, which is subject to two constraints 1. The principal directions have unit length 2. Either a.Successively derived scores are uncorrelated to previously derived scores, OR b.Successively derived directions are required to be orthogonal to previously derived directions • In the mathematical formulation, either constraint implies the other constraint 74 Principal Components Analysis 5 Direction 1 4 3 Score Predictor 2 2 1 0 -6 -5 -4 -3 -2 -1 0 -1 -2 -3 -4 Predictor 1 75 http://pfizerpedia/index.php/Image:PCAmovie.gif 1 2 3 4 5 Mathematically Speaking… • The optimization problem defined by PCA can be solved through the following formulation: aTX , arg max Var T a a a subject to constraints 2a. or b. • Facts… – the ith principal direction, ai, is the eigenvector corresponding to the ith largest eigenvalue of XTX. – the ith largest eigenvalue is the amount of variability summarized by the ith principal component. – a iT X are the ith scores 76 PCA Benefits and Drawbacks • Benefits – Dimension reduction • We can often summarize a large percentage of original variability with only a few directions – Uncorrelated scores • The new scores are not linearly related to each other • Drawbacks – PCA “chases” variability • PCA directions will be drawn to predictors with the most variability • Outliers may have significant influence on the directions and resulting scores. 77 Principal Component Regression Procedure: 1. Reduce dimension of predictors using PCA 2. Regress scores on response Notice: The procedure is sequential 78 Principal Component Regression Dimension reduction is independent of the objective Predictor Variables PCA PC Scores MLR Response Variable 79 First Principal Direction Scatter of Predictors 5.00 3.00 Predictor 2 PD1 1.00 -1.00 -3.00 -5.00 -5.00 -4.00 -3.00 -2.00 -1.00 0.00 Predictor 1 80 1.00 2.00 3.00 4.00 5.00 Relationship of First Direction with Response Scatter of First PCA Scores with Response 2.50 2.00 1.50 Response 1.00 0.50 0.00 -0.50 -1.00 -1.50 R2 = 0.001 -2.00 -6.00 81 -4.00 -2.00 0.00 2.00 First PCA Scores 4.00 6.00 8.00 PLS History • H. Wold (1966, 1975) • S. Wold and H. Martens (1983) • Stone and Brooks (1990) • Frank and Friedman (1991, 1993) • Hinkle and Rayens (1994) 82 Latent Variable Model Predictor1 1 Predictor2 Response1 Predictor3 Predictor4 Response2 Response3 2 Predictor5 Predictor6 Predictors Latent Variables Responses Note: PLS can handle multiple response variables 83 Comparison with Regression Predictor1 Predictor2 Predictor3 Predictor4 Predictor5 84 Response1 PLS Optimization (many predictors, one response) • PLS seeks to find linear combinations of the independent variables that summarize the maximum amount of co-variability with the response. – These linear combinations are often called PLS components or PLS scores. – A PLS direction is a vector that points in the direction of maximum co-variance. 85 PLS Optimization (many predictors, one response) • PLS is inherently an optimization problem, which is subject to two constraints 1. The PLS directions have unit length 2. Either a.Successively derived scores are uncorrelated to previously derived scores, OR b.Successively derived directions are orthogonal to previously derived directions • Unlike PCA, either constraint does NOT imply the other constraint • Constraint 2.a. is most commonly implemented 86 Mathematically Speaking… • The optimization problem defined by PLS can be solved through the following formulation: 2 T Cov a X, Y arg max , T a a a subject to constraints 2a. or b. • Facts… – the ith PLS direction, ai, is the eigenvector corresponding to the ith largest eigenvalue of ZTZ, where Z = XTy. – the ith largest eigenvalue is the amount of co-variability summarized by the ith PLS component. – a iT X are the ith scores 87 PLS is Simultaneous Dimension Reduction and Regression 2 T Cov a X, Y arg max a Ta a var a T X varY corr2 a T X, Y arg max T a a a var a T X corr2 a T X, Y varY arg max a Ta a varscorescorr2 scores,response varresponse arg max T a a a 88 PLS is Simultaneous Dimension Reduction and Regression max Var(scores) Corr2(response,scores) Dimension Reduction (PCA) 89 Regression PLS Benefits and Drawbacks • Benefit – Simultaneous dimension reduction and regression • Drawbacks – Similar to PCA, PLS “chases” co-variability • PLS directions will be drawn to independent variables with the most variability (although this will be tempered by the need to also be related to the response) • Outliers may have significant influence on the directions, resulting scores, and relationship with the response. Specifically, outliers can – make it appear that there is no relationship between the predictors and response when there truly is a relationship, or – make it appear that there is a relationship between the predictors and response when there truly is no relationship 90 Partial Least Squares Simultaneous dimension reduction and regression Predictor Variables PLS Response Variable 91 First PLS Direction Scatter of Predictors 5.00 First PLS Direction Predictor 2 3.00 1.00 -1.00 -3.00 -5.00 -5.00 -4.00 -3.00 -2.00 -1.00 0.00 Predictor 1 92 1.00 2.00 3.00 4.00 5.00 Relationship of First Direction with Response Scatter of First PLS Scores with Response 2.50 2.00 1.50 Response 1.00 0.50 0.00 -0.50 -1.00 -1.50 R2 = 0.93 -2.00 -2.00 -1.50 -1.00 -0.50 0.00 0.50 First PLS Scores 93 1.00 1.50 2.00 2.50 PLS in Practice • PLS seeks to find latent variables (LVs) that summarize variability and are highly predictive of the response. • How do we determine the number of LVs to compute? – Evaluate RMSPE (or Q2) • The optimal number of components is the number of components that minimizes RMSPE 94 PLS for the Boston housing data: Training the PLS Model • Since PLS can handle highly correlated variables, we fit the model using all 12 predictors • The model was trained with up to 6 components • RMSE drops noticeably from 1 to 2 components and some for 2 to 3 components. – Models with 3 or more components might be sufficient for these data 95 Training the PLS Model • Roughly the same profile is seen when the models are judged on R2 96 Boston Housing Results • Using the two component model, we can predict the test set • PLS training statistics are similar to those from linear regression • Both methods perform about the same in the test set Training Data (bootstrap) 97 Test Data RMSE Q2 RMSE R2 Linear Reg 5.23 0.691 4.53 0.742 PLS 5.25 0.689 4.56 0.739 PLS Model Fit – Test Set Results 98 PLS Optimization (2) (many predictors, many responses) • PLS seeks to find linear combinations of the independent variables and a linear combination of the dependent variables that summarize the maximum amount of co-variability between the combinations. – These linear combinations are often called PLS Xspace and Y-space components or PLS X-space and Y-space scores. – Likwise, X-space and Y-space PLS directions point in the direction of maximum co-variance between the spaces. 99 PLS Optimization (2) (many predictors, many responses) • PLS is inherently an optimization problem, which is subject to two constraints 1. The X-space and Y-space PLS directions have unit length 2. Either a.Successively derived scores in each space are uncorrelated to previously derived scores, OR b.Successively derived directions in each space are orthogonal to previously derived directions • Constraint 2.a. is most commonly implemented 100 Mathematically Speaking… • The optimization problem defined by PLS can be solved through the following formulation: 2 T T Cov a X, b Y arg max , T T a a b b a,b subject to constraints 2a. or b. T T 2 T T var a X var b Y corr a X, b Y arg max T T a a b b a,b 101 PLS is Simultaneous Dimension Reduction and Regression max Var(X-scores) Corr2(X-scores,Y-scores)Var(Y-scores) X-space Dimension Reduction (PCA) 102 Regression Y-space Dimension Reduction (PCA) Neural Networks 103 Neural Networks • Like PLS or PCR, these models create intermediary latent variables that are used to predict the outcome • Neural networks differ from PLS or PCR in a few ways – the objective function used to derive the new variables is different – The latent variables are created using flexible, highly nonlinear functions – The latent variables usually do not have any meaning 104 Network Structures • There are many types of neural network structures – we will concentrate on the single layer, feed-forward network One hidden layer of latent variables Predictor1 Hidden Unit 1 Predictor2 Hidden Unit 2 Predictor3 … Predictor4 Predictor5 105 Hidden Unit k Response1 From Predictors to Hidden Units • The transition from this sub-model to the hidden units is nonlinear – sigmoidal functions, such as the logistic function, are typically used 106 From Hidden Units to the Outcome • The hidden units are then used to predict the outcome using simple linear combinations • Clearly, the parameters are not identifiable and the hidden units have no real meaning (unlike PCA) 107 Training Networks • It is highly recommended that the predictors are centered and scaled prior to training • The number of hidden units is a tuning parameter • With many predictors and hidden units, the number of estimated parameters can become very large – with a large number of hidden units, these models can quickly start to overfit • Random starting values are typically used to initialize the parameter estimates 108 Weight Decay • This is a training technique that attempts to “shrink” the parameter estimates towards zero – large parameter estimates are penalized in the model training • This leads to smoother, less extreme models – the effect of weight decay is demonstrated for classification models 109 Boston Housing Data • The model seems to do well with fewer components (not typical) • For these data, larger amounts of weight decay is better for the model fit 110 Boston Housing Results • The final model used high value for weight decay and 1 hidden unit • This model seems to be an improvement compared to the others Training Data (bootstrap) 111 Test Data RMSE Q2 RMSE R2 Linear Reg 5.23 0.691 4.53 0.742 PLS 5.25 0.689 4.56 0.739 Neural Net 4.60 0.757 4.20 0.780 Support Vector Machines 112 Support Vector Machines (SVMs) • SVMs are predictive statistical models developed in 1963 by Vapnik that were significantly expanded in the 90’s • These models were initially developed for classification models, but were later adapted for regression models 113 Objective Functions • Recall that linear regression estimates parameters by calculating: – the model residuals – the total sum of the squared residuals (SSR) • The parameters with the smallest SSR are optimal 114 Objective Functions • Support vector machine regression models create a “funnel” around the regression line – residuals within the funnel are not counted in the parameter estimation – the sum of the residuals outside the funnel are used as the objective function (no squared term) • A funnel size is set to 1 SD of the outcome is not a bad place to start 115 The SVM Model Optimization • Like Huber-type robust regression, outliers have a linear effect on the objective function • Overfitting can be controlled by using a penalized objective function (more later) • Quadratic programming methods are needed to solve these equations 116 Support Vectors and Data Reduction • The points that are outside the funnel (or on it’s boundary) are the support vectors • It turns out that the prediction function only uses the support vectors – the prediction equation is more compact and efficient – the model may be more robust to outliers 117 Support Vectors and Data Reduction • The model fitting routine produces values () that are non-zero for all of the support vectors • To predict a new sample, the original training data for the non-zero values are needed: 118 Nonlinear Boundaries • Nonlinear boundaries can be computed using the “kernel trick” • The predictor space can be expanded by adding nonlinear functions of the predictors • Common kernel functions are: 119 Nonlinear Boundaries • The “trick” is that the computations can operate only on the inner-products of the extended predictor set • In this way, the predictor space dimension can be greatly expanded without much computational impact 120 Cost functions • Support vector machines also include a regularization parameter that controls how much the regression line can adapt to the data – smaller values result in more linear (i.e. flat) surfaces • This parameter is generally referred to as “Cost” • For example, this link show the effect of the cost function for a highly nonlinear problem – SvmRegMovieA.gif • This one shows the robustness of SVM regression models – SvmRegMovieB.gif 121 Boston Housing Data • As previously mentioned, there is a way to analytically estimate the tuning parameter for the RBF – here, a fixed value of 0.0219 is used • The remaining parameter (cost) shows a clear optimum 122 Summary • Currently, the SVM model is best at prediction (but worst at interpretation) Training Data (bootstrap) 123 Test Data RMSE Q2 RMSE R2 Linear Reg 5.23 0.691 4.53 0.742 PLS 5.25 0.689 4.56 0.739 Neural Net 4.60 0.757 4.20 0.780 SVM (radial) 3.79 0.834 3.28 0.861 Multivariate Adaptive Regression Splines 124 Multivariate Adaptive Regression Splines • MARS is a nonlinear statistical model • The model does an exhaustive search across the predictors (and each distinct value of the predictor) to find the best way to sub-divide the data • Based on this “split” value, MARS creates new features based on that variable • These artificial features are used to model the outcome 125 MARS Features • MARS uses “hinge” functions that are two connected lines • For a data point x of a predictor, MARS creates a function that models the data on each side of x: • These features are created in sets of two (switching which side is “zeroed”) 126 x h(x-6) h(6-x) 2 0 2 4 0 4 8 8 0 10 10 0 Prediction Equation and Model Selection • The model iteratively adds the two new features and uses ordinary regression methods to create a prediction equation. The process then continues iteratively. • MARS also includes a built-in feature selection routine that can remove model terms – the maximum number of retained features (and the feature degree) are the tuning parameters • The Generalized CrossValidation statistic (GCV) is used to select the most important terms 127 Sine Wave Example • As an example, we can use MARS to model one predictor with a sinusoidal pattern • The first MARS iteration produces a split at 4.3 – two new features are created – a regression model is fit with these features – the red line shows the fit 128 Sine Wave Example • On the second iteration, a split was found at 7.9 – two new features are created • However, the model fit on the left side was already pretty good – one of the new surrogate predictors was removed by the automatic feature selection • The model now has three features 129 Sine Wave Example • The third split occurred at 5.5 • Again, only the “right-hand” feature was retained in the model • This process would continue until – no more important features are found – the user-defined limit is achieved 130 Higher Order Features • Higher degree features can also be used – two or more hinge functions can be multiplied together to for a new feature – in two dimensions, this means that three of four quadrants of the feature can be zero if some features are discarded 131 Boston Housing Data • We tried only additive models – the model could retain from 4 to 36 model terms • The “best” model used 18 terms 132 Boston Housing Data • Since the model is additive, we can look at the prediction profile of each factor while keeping the others constant 133 Summary • SVMs are still optimal, but the respectable performance and interpretability of MARS might make us reconsider Training Data (bootstrap) 134 Test Data RMSE Q2 RMSE R2 Linear Reg 5.23 0.691 4.53 0.742 PLS 5.25 0.689 4.56 0.739 Neural Net 4.60 0.757 4.20 0.780 SVM (radial) 3.79 0.834 3.28 0.861 MARS 4.29 0.791 3.98 0.804 Regression Trees 135 Regression Trees • A regression tree searches through each predictor to find a value of single predictor that best splits the data into two groups. – the best split minimizes the mean squared error of the model. • For the two resulting groups, the process is repeated until a hierarchical structure (a "tree") is created. – in effect, trees partition the predictor space into rectangular sections that assign a single average to compounds within the rectangle. 136 Computational Difficulties • Suppose we have n observations and p predictors. – For each level of the tree, there are at most p(n-1) possible splits • As tree depth increases, the number of possible split combinations multiplies – The total number of possible split combinations is bounded above by [p(n-1)]depth – Suppose we have 100 observations and 100 dimensions. – The number of possible trees is bounded above by 10400! 137 A Greedy Approach • Instead of trying to find the best global set of regions for which the responses are similar, we recursively partition the data to find an optimal set of decision rules. • A regression tree searches through each predictor to find a value of a single predictor that best splits the data into two groups. 138 Objective at Each Split • Let [Xnxp|Ynx1] represent the data matrix • We seek a predictor, Xj, and split point, s, that solve: 2 2 yi c1 min yi c2 min c2 xij R2 c1 xij R1 where xij R1 x xij sand xij R2 x xij s, for i 1,2,...,n and j 1,2,..., p. • The best c1 and c2 are the average responses for the observations in each region • For the two resulting groups, the process is repeated 139 Splitting Example – Boston Housing • We start with all of the training data • Searching through all the data yields the first split – a lower status value of 9.6% provides the best decrease in MSE 140 Splitting Example – Boston Housing • Searching though the first left split (), the best split again uses the lower status % • In the initial right split (), the split was based on the mean number of rooms • Now, there are 4 possible predicted values 141 Tree Fitting Process • This process would continue until some criterion for stopping is met – such as the minimum number of compounds in a node • The largest possible tree may over-fit • “Pruning” is the process of iteratively removing terminal nodes – looking for drops in resampling performance 142 Tree Fitting Process • There are many possible pruning paths – how many possible trees are there with 6 terminal nodes? • We can index the possible trees by a complexity parameter, Cp. – Cp = 0 is the largest tree possible – as Cp increases, the tree shrinks – there are a discrete set of Cp values for a data set • Algorithmically, we can control the complexity by setting the maximum tree depth 143 Comparison • For these data, we tried 6 possible tree sizes • For each value, resample the data and calculate performance • After a depth of 4, the model cannot improve performance Training Data (bootstrap) Single Tree 144 Test RMSE Q2 RMSE R2 5.18 0.700 4.28 0.780 Boston Housing Example • A depth of 4 was optimal (see righthand branch) • This model has a test set performance of 0.78 – so far the best is 0.86 • However, we can clearly get a sense of what the model is saying 145 Single Trees • Advantages – can be computed very quickly and have simple interpretations. – have built-in predictor selection: if a predictor was not used in any split, the model is completely independent of that data. • Disadvantages – instability due to high variance: small changes in the data can drastically affect the structure of a tree – data fragmentation – high order interactions 146 Ensemble Methods 147 Ensemble Methods • Ensembles of trees have been shown to provide more predictive models than individual trees and are less variable than individual trees • Common ensemble methods are: – Bagging – Random forests, and – Boosting 148 Bagging Trees • Bootstrap Aggregation – Breiman (1994, 1996) Bootstrap Sample Bootstrap Sample Prediction Prediction ... Bootstrap Sample – Bagging is the process of 1. creating bootstrap samples of the data, 2. fitting models to each sample 3. aggregating the model predictions – The largest possible tree is built for each bootstrap sample 149 Final Prediction Prediction Bagging Model Prediction of an observation, x: M F ( x) 150 f x m 1 m M Comparison • Bagging can significantly increase performance of trees – from resampling: Training Data (bootstrap) Test RMSE Q2 RMSE R2 Single Tree 5.18 0.700 4.28 0.780 Bagging 4.32 0.786 3.69 0.825 • The cost is computing time and the loss of interpretation • One reason that bagging works is that single trees are unstable – small changes in the data may drastically change the tree 151 Random Forests • Random forests models are similar to bagging – separate models are built for each bootstrap sample – the largest tree possible is fit for each bootstrap sample • However, when random forests starts to make a new split, it only considers a random subset of predictors – The subset size is the (optional) tuning parameter • Random forests defaults to a subset size that is the square root of the number of predictors and is typically robust to this parameter 152 Random Predictor Illustration Randomly select a subset of variables from original data Dataset 1 Dataset 2 Dataset M | | | Build trees Predict Predict Final Prediction 153 Predict Random Forests Model Prediction of an observation, x: M F ( x) 154 f x m 1 m M Properties of Random Forests • Variance reduction – Averaging predictions across many models provides more stable predictions and model accuracy (Breiman, 1996) • Robustness to noise – All observations have an equal chance to influence each model in the ensemble – Hence, outliers have less of an effect on individual models for the overall predicted values 155 Comparison • Comparing the three methods using resampling: Training Data (bootstrap) Test RMSE Q2 RMSE R2 Single Tree 5.18 0.700 4.28 0.780 Bagging 4.32 0.786 3.69 0.825 Rand Forest 3.55 0.857 3.00 0.885 • Both bagging and random forests are “memoryless” – each bootstrap sample doesn’t know anything about the other samples 156 Boosting Trees • A method to “boost” weak learning algorithms (small trees) into strong learning algorithms – Kearns and Valiant (1989), Schapire (1990), Freund (1995), Freund and Schapire (1996a) • Boosted trees try to improve the model fit over different trees by considering past fits 157 Boosting Trees • First, an initial tree model is fit (the size of the tree is controlled by the modeler, but usually the trees are small (depth < 8)) – if a sample was not predicted well, the model residual will be different from zero – samples that were predicted poorly in the last tree will be given more weight in the next tree (and vice-versa) • After many iterations, the final prediction is a weighted average of the prediction form each tree 158 Boosting Illustration Stage 2 1 n=200 Build weighted tree X1 > 5.2 n=90 X1 < 5.2 n=110 n 2 e i 32.9 Compute stage weight βstage 1 = f(32.9) 159 M n=200 Compute error Reweigh observations (wi=1,2,..., n) ... i 1 Determine weight of ith observation: The larger the error, the higher the weight X27 > 22.4 n=64 n=200 X27 < 22.4 X6 > 0 X6 < 0 n=136 n=161 n=39 n 2 e i 26.7 i 1 βstage 2 = f(26.7) Determine weight of ith observation n 2 e i 29.5 i 1 βstage M = f(29.5) Boosting Trees • Boosting has three tuning parameters: – number of iterations (i.e. trees) – complexity of the tree (i.e. number of splits) – learning rate: how quickly the algorithm adapts • This implementation is the most computationally taxing of the tree methods shown here 160 Final Boosting Model Prediction of an observation, x: M F ( x) m f m x m 1 where the βm are constrained to sum to 1. 161 Properties of Boosting • Robust to overfitting – As the number of iterations increases, the test set error does not increase – Schapire, et al. (1998), Friedman, et al. (2000), Freund, et al. (2001) • Can be misled by noise in the response – Boosting will be unable to find a predictive model if the response is too noisy. – Kriegar, et al. (2002), Wyner (2002), Schapire (2002), Optiz and Maclin (1999) 162 Boosting Trees • One approach to training is to set the learning rate to a high value (0.1) and tune the other two parameters • In the plot to the right, a grid of 9 combinations of the 2 tuning parameters were used to optimize the model • The optimal settings were: – 500 trees with high complexity 163 Comparison Summary • Comparing the four methods: Training Data (bootstrap) 164 Test RMSE Q2 RMSE R2 Single Tree 5.18 0.700 4.28 0.780 Bagging 4.32 0.786 3.69 0.825 Rand Forest 3.55 0.857 3.00 0.885 Boosting 3.64 0.847 3.19 0.870 Model Building Training Model Comparisons 165 Which Model is Best? • The “No Free Lunch Theorem”: – over the set of all possible problems, each algorithm will do on average as well as any other or, in other words, – if one model is better than another, it is because of the particular problem at hand; no one method is uniformly best • Despite this statement, the next slide has some (subjective) ratings of models 166 Top Level Comparisons Model Speed Performance Interpretability Robustness Boosted Tree Random Forest Linear Model PLS MARS Neural Net SVM RDA FDA Naϊve Bayes Excellent 167 Very Good Average Fair Poor Top Level Comparisons Model Boosted Tree Random Forest Linear Model PLS MARS Neural Net SVM RDA FDA Naïve Bayes Missing #Param Pre-Process P > N ? Data ? 2-3 0-1 0 1 2 2 2-3 2 2 0-1 None None ZV, NZV, HCP CS ZV, NZV, HCP ZV, CS, HCP CS ZV None ZV Yes Yes No Yes Yes Yes Yes No Yes Yes ZV = zero var predictor, NZV = near-zero var predictor, CS = center+scale, HCP = highly correlated predictor * Depends on implementation 168 Yes* Yes* No No Yes No No No Yes Yes Boston Housing Data • The correlation between the results on the training set (n=337) via cross-validation and the results from the test set (n=169) were 0.971 (RMSE) and 0.965 (R2) 169 Some Advice • There is an inverse relationship between performance and interpretability • We want the best of both worlds: great performance and a simple, intuitive model Interpretability Tree Regression PLS MARS • Try this: – Fit a high performance model to get an idea of the best possible performance – Move up the line and see if a less complex model can keep performance up with some interpretability NNet Boosted Tree SVM RF/Bagging Performance 170 Regression Datasets 171 Internet Move Data Base • IMDB is an on-line resource that catalogs movies and TV programs from many countries. • Basic information about the program is maintained and users can rate each program on a five point scale. • We extracted information about movies and captured: – the average vote – the number of votes – basic information: run time, rating (if any), year of release, etc – genre: drama, comedy etc and – keywords: based on novel, female lead, title spoken by character… • Can we predict the movie rating based on these data? 172 Tecator Spectroscopy Data • From Statlib: “These data are recorded on a Tecator Infratec Food and Feed Analyzer working in the wavelength range 850 - 1050 nm by the Near Infrared Transmission (NIT) principle. Each sample contains finely chopped pure meat with different moisture, fat and protein contents. For each meat sample the data consists of a 100 channel spectrum of absorbances and the contents of moisture (water), fat and protein. The absorbance is -log10 of the transmittance measured by the spectrometer. The three contents, measured in percent, are determined by analytic chemistry.” 173 Tecator Spectroscopy Data • The variables are spectral measurements at specific wavelengths and are highly autocorrelated. • We wish to predict the percent fat for each sample. 174 Towson Home Sales • Information about homes sold in the Towson, Maryland area (north of Baltimore) were collected. • The area encompasses the northern border of Baltimore city (Idlewydle), suburban areas (Annelsie, Rodgers Forge, Wiltondale) and more expensive areas (Stoneleigh, Ruxton). • Variables include: – The lot size – The sale date and – Square footage – The year built – Number of baths • Can we accurately predict the sale price of a home? 175 Regression Backup Slides 176 SVM Model Fit – Test Set Results 177 MARS Model Fit – Test Set Results 178 Regression Tree Model Fit – Test Set Results 179 Boosting Tree Model Fit – Test Set Results 180 Variable Importance for PLS • To understand the importance of each factor, we can look at a weighted sum of the absolute regression coefficients – the weights are based on the decrease in error as more components are added • We can also look at the loadings to get a more detailed assessment 181 Variable Importance for PLS • Here, we can look at the increase in R2 as model terms are added • If the variable is never used in a term, it has an importance of zero 182 Variable Importance for Regression Trees • Here, we can look at the decrease in MSE as model terms are added • If the variable is never used in a split, it has an importance of zero 183 Variable Importance for Random Forests • A permutation approach is used • Each training data for variable is scrambled in turn and the % increase in the out-of-bag MSE is tracked 184 Boosting, Formally… • Boosting fits a forward stagewise additive model (Hastie, Tibshirani and Friedman, 2001) through the following steps: 1. Let f 0 x 0 2. For m 1, 2,, M do stepsa and b N a. βm , hm arg min ,h yi f m1 xi hxi i 1 where R, and h is a tree. b. f m x f m1 x m hm x 185 2 Boosting’s Underlying Model • λ acts as a shrinkage parameter and is called the learning rate. – a parameter that controls the rate of learning of observations that overlap on a decision boundary (Friedman, 2001) • Shrinkage boosting can be viewed as fitting this additive model: f M x hm H d Hd h x m m m m 1 where hm(x) Hd , and Hd represents a dictionary of trees of depth d. (Hastie, 2001) 186 Linear Regression Pre-Processing • Linear regression models will fail if there are zerovariance predictors included – They will also fail during cross-validation if any nearzero variance predictors are in the data • As just discussed, removing highly correlated predictors is strongly suggested • Centering and scaling are not required, but can greatly increase the numerical stability of the model 187 PLS Pre-Processing • Because of its dimension reduction abilities, PLS is resistant to zero- and near-zero variance predictors • Also, since PLS can handle (and perhaps exploit) correlated predictors, it is not necessary to remove them • Centering and scaling are extremely important for PLS models – otherwise, the predictors with large variability can dominate the selection of components 188 Neural Network Pre-Processing • Neural network models will not fail with zero-variance predictors • However, these models use a large number of parameters and near-zero variance predictors may lead to numerical issues such as a failure to converge • Highly correlated predictors should be removed; multicollinearity can have a significant effect on model performance • Centering and scaling are required 189 MARS Pre-Processing • MARS models are resistant to zero- and near-zero variance predictors • Highly correlated predictors are allowed, but this can lead to significant amount of randomness during the predictor selection process – The split choice between two highly correlated predictors becomes a toss-up • Centering and scaling are not required but are suggested 190 Tree Pre-Processing • A basic regression tree requires very little preprocessing – missing predictor values are allowed – centering and scaling are not required • centering and scaling do not affect results – highly correlated predictors are allowed • Including highly correlated descriptors can cause instability and make descriptor importance rankings somewhat random – zero- and near-zero variance predictors are allowed 191 Model Building Training Classification-type Models 192 Setting Variables Pred. 1 Obs 1 3.231 Obs 2 5.249 Obs 3 7.534 ... Obs n 6.878 Pred. 2 99.30 63.78 84.53 77.21 ... Pred. p 20104 30128 10021 Response 50249 Inactive Inactive Active Active Response is categorical Response may have more than two categories 193 Objective To construct a model of predictors that can be used to predict a response Data Model Prediction 194 Classification Methods • Discriminant analysis framework – Linear, quadratic, regularized, flexible, and partial least squares discriminant analysis • Modern classification methods – Tree-based ensemble methods • Boosting and random forests – Neural networks – Support vector machines – k-nearest neighbors – Naive Bayes • Each of these methods seek to find a partitioning of the data that minimizes classification error 195 Evaluating Classification Model Performance • Like regression models, we desire to understand the predictive ability of a classification model. • We can evaluate a model’s performance by using crossvalidation or a test set of data. • For regression models, the measure of performance was RMSE (or RMSPE)—a function of the deviation of the observed value from the predicted value. – This is a valid measure of performance when the response is continuous, but not when the response is categorical. • Instead, we need a measure of predictive ability that is appropriate for categorical data. 196 Objective • Minimize classification error (or maximize accuracy) – Determine how well the model prediction agrees with the actual classification of observations. Predicted 197 Active Inactive Total Active A B A+B Inactive C D C+D Total A+C B+D N=A+B+C+D Intuition • An intuitive measure of accuracy is (A + D) / N – When the actual classes are balanced, this is an appropriate measure of model performance. • But, this measure produces the same values for different tables: Active Inactive Active 50 50 Inactive 50 4850 vs Active Inactive Active 95 5 Inactive 95 4805 Accuracy for both tables is 0.98 Does one table show more agreement than the other? 198 Another Measure: Kappa • To provide a measure of agreement for unbalanced tables, Cohen (1960) proposed comparing the observed agreement to the expected agreement • To compute Kappa, we need – The observed agreement: O = (A + D) / N – The expected agreement A C A B B D C D E N2 • Kappa is defined as: k = (O – E) / (1 – E) 199 Kappa Properties • Generally: -1 k 1 – values close to 0 indicate poor agreement – values close to 1 indicate near perfect agreement • for complete disagreement, k = -1 – “Values of 0.4 or above are considered to indicate moderate agreement, and values of 0.8 or higher indicate excellent agreement.” (Stokes, Davis, and Koch, 2001) • Can be generalized to > 2 classes k = 0.49 Active Inactive k = 0.65 Active Inactive Active 50 50 Active 95 5 Inactive 50 4850 Inactive 95 4805 Note: When the observed classes are balanced, kappa = accuracy 200 Another Measure: Receiver Operating Characteristic (ROC) Curves • ROC curves can be used to assess a classification model’s performance or to compare several models’ performance • Building an ROC curve requires that the model produces a continuous prediction • For each predicted value of the response, we construct a 2x2 table using the predicted value as the cutoff. 201 ROC Curves Observed Class Positive Negative Predicted Class Positive Negative TP FN FP TN • Terminology: – Sensitivity = True Positive Rate = TP / (TP + FN) – Specificity = True Negative Rate = TN / (FP + TN) • An ROC curve is a plot of 1 – specificity versus sensitivity for each predicted value of the response – false positive rate versus true positive rate • A perfect classification model has both a sensitivity and specificity of 1. 202 ROC Example Predicted Observed Prob Class 0.05 0.35 0.37 0.60 + 0.61 0.63 0.83 0.88 + 0.89 + 0.99 + Cutoff = 0.99 Observed Class Predicted Class + - + 0 0 4 6 Sensitivity Specificity 0/4 6/6 Sensitivity 1 0.8 0.6 0.4 0.2 0 0 0.2 0.4 0.6 0.8 1 1 - Specificity Cutoff = 0.89 Observed Class Predicted Class + - + 1 0 3 6 Sensitivity Specificity 1/4 6/6 Cutoff = 0.61 Observed Class Predicted Class + - + 3 3 Sensitivity Specificity 3/4 3/6 All observations with predicted probabilities ≤ the cutoff are classified as negative. 203 1 3 Classification Model Predictions • Several classification models generate a predicted value for each class in the original data – PLSDA, FDA, and NN • The class with the largest predicted outcome is the predicted class – Predictions from the model are generally between 0 and 1, but are not guaranteed to be within this range. • The softmax technique is used to transform the predicted outcomes to “probability-like” values that can be interpreted as class probabilities – On the [0, 1] scale and add up to 1 204 Softmax Function • Let gik be the classification score of the ith observation into group k. • The probability that the observation is in group k g ik is: e K e g ip p 1 where K is the total number of groups 205 Discriminant Models 206 Classical Discriminant Models • These models form a discriminant function that can be used to classify samples • The discriminant function is a linear function of the predictors that attempts to: • This is a latent variable method similar to PLS and others that we have seen – how the latent variable is created differs between methods 207 Linear Discriminant Analysis • Assumption: the within group variability is the same for each group. • For a two-class problem, the classification boundary is a straight line – The function uses the within-class means and the overall covariance structure to create the latent variable • Because it uses the covariance matrix, there must be – at least as many compounds as predictors – no zero-variance or linearly dependent predictors • LDA is not optimal for groups separated by curvature 208 Example where LDA works • The plot on the right shows a three class example where a linear method like LDA is most effective 209 Aside: LDA and Logistic Regression • It turns out that LDA and logistic regression are fitting models that are very similar – LDA assumes that the predictors are measured with error and that the classification of the observations is known – LR assumes that the predictors are known and that the classification of the observations are measured with error • Assuming that the response error is Normal, the optimal separating plane for logistic regression is: • LDA estimates a large number of parameters and has fairly strict constraints on the data • Also, logistic models may be more forgiving of skewed predictor distributions 210 Example Data • For our example data set, LDA doesn’t do a very good job since the boundary is nonlinear • The linear predictor is determined to be (1.18 Predictor A) (0.25 Predictor B) 211 Aside: LDA and Large Number of Predictors • Some classification models are not drastically affected by large numbers of predictors – In many cases, a number of predictors will be noise • LDA has the potential to overfit – LDA class probability estimates become more extreme as the number of predictors becomes large even when there is no underlying difference • A similar issue occurs in LR – For LR, at some point a random predictor will perfectly split the classes 212 Aside: LDA and Large Number of Predictors • For example, we simulated a data set that was complete noise • For a small number of predictors, the posterior probabilities were grouped around 0.50 • As the number of predictors was increased, the “certainty” of these probabilities became more extreme 213 PLS for Discrimination • In regression PLS seeks to find linear combinations of the original variables (scores) that are highly correlated with the response. • For classification problems we can use PLS to find linear combinations of the original variables that optimally separate the data. – Unlike regression, the response for classification is a binary matrix, with each column indicating the class of the observation 214 Response Matrix 1 1 0 Y 0 0 0 0 0 0 0 1 0 1 0 0 1 0 1 PLS Optimization (many predictors, many responses) • Like the regression setting, we must solve an optimization problem that is subject to constraints: 1. The X-space and Y-space PLS directions have unit length 2. Either a.Successively derived scores in each space are uncorrelated to previously derived scores, OR b.Successively derived directions in each space are orthogonal to previously derived directions 215 Solution: Same as PLS for Regression • The optimization problem defined by PLS can be solved through the following formulation: 2 T T Cov a X, b Y arg max , T T a a b b a,b subject to constraints 2a. or b. T T 2 T T var a X var b Y corr a X, b Y arg max T T a a b b a,b 216 Facts • Barker and Rayens (2003) showed: – The PLS directions are the eigenvectors of a modified between-class covariance matrix, B. – Coding of the response matrix does not matter • either g columns or g-1 columns provides the same answer – The constraint in the Y-space does not make sense • Why constrain a response that denotes class membership? – If the Y-space constraint is removed, the PLS directions are exactly the eigenvectors of the betweenclass covariance matrix, B. – LDA is optimal if dimension reduction is not necessary • The optimal directions for LDA are the eigenvectors of W-1B. 217 PLS Discriminant Analysis Example 1 The softmax function is used to determine classification boundaries. 218 PLS Discriminant Analysis Example 2 PLSDA 219 LDA Quadratic Discriminant Analysis • Assumption: the within group variability is different for each group. • The decision rule is – where k represents group k. – The class with the largest score is the predicted class – A function of squared distance of each observation from each group’s center • The decision rule depends on the covariance matrix for each group 220 Quadratic Discriminant Analysis • QDA extends the LDA model by using quadratic (i.e nonlinear) classification boundaries • However, the data requirements are more stringent – at least as many compounds as predictors in each class – no zero-variance or linearly dependent predictors 221 Regularized Discriminant Analysis • The method tries to split the difference between LDA and QDA. • It uses two tuning parameters, gamma and lambda: – gamma controls the correlation assumption for the predictors • as gamma 1 the model assumes less predictor correlations – lambda toggles between linear and quadratic boundaries • gamma = 0 & lambda = 1 LDA • gamma = 0 & lambda = 0 QDA • Other combinations of gamma and lambda produce models that are compromises between LDA and QDA 222 Regularized Discriminant Analysis • To see the effect of changing gamma: – RdaMovieA.gif • To see the effect of changing lambda: – RdaMovieB.gif • We can find the optimal gamma and lambda by cross-validation 223 Flexible Discriminant Analysis • FDA generalizes LDA to highly nonlinear boundaries • In addition to the original predictors, nonlinear functions of the predictors are added to the data – This is known as a “basis expansion” of the original data • This procedure essentially builds a set of “one versus all” classification models – a 0/1 outcome is used for each model – the softmax function is used to convert the model output to class probabilities 224 Flexible Discriminant Analysis • For example, the MARS “hinge functions” can be used • For each 0/1 outcome, the best predictor/split of the data is determined and two hinge functions are added • Hinge functions are added until a pre-specified number of terms is reached • Like the MARS model, the number of features is reduced until the fit begins to suffer 225 FDA Example • FDA uses the MARS procedure to determine new hinge features – for these data, 3 sets of features were used in to discriminate the classes 226 Modern Classification Methods 227 Classification Trees • Like regression trees, classification trees search through each predictor to find a value of single predictor that splits the data into two (or more) groups that are more pure than the original group. • For each partition, each predictor is evaluated at all possible split points and the best predictor and split are selected. – Process continues until some criterion for stopping is met (like minimum number of observations in a node) 228 Splitting Example Pred A A > Thresh 1 A Thresh 1 Pred B B > Thresh 2 Pred D B Thresh 2 Pred A A > Thresh 3 229 1 2 D > Thresh 4 D Thresh 4 A Thresh 3 1 2 1 2 1 2 1 2 Impurity Measures • There are several measures for determining the purity of the split. For a two-class, two common measures are – Misclassification error – Gini index 230 Impurity Measure Definitions x<k Class 1 a Class 2 c x≥k b d c a p1 min , ac ac d b p2 min , bd bd ac bd w1 , w2 n n • Misclassification error: w1p1 + w2p2 – When w1 = w2= 0.5, ME = 0.5*(p1 + p2) • Gini index: w1p1(1-p1) + w2p2(1-p2) – When w1 = w2= 0.5, GI = 0.5*(p1(1-p1) + p2(1-p2)) 231 Impurity Measure Comparison 232 Simple Example 10 • In this example a few possible partitions clearly stand out: 8 – x1 = 5, 0 • How does each impurity measure rank these partitions? 2 4 x2 – x2 = 1.5 6 – x2 = 7.5, or 0 2 4 6 x1 233 8 10 Classification Results Black Red Total x1 ≥ 5 40 7 47 x1 < 5 11 42 53 Black Red Total x2 < 7.5 x2 ≥ 7.5 51 0 32 17 83 17 Black Red Total x2 < 1.5 14 0 14 Partition Misclassification Error Gini Index x1 ≥ 5 0.15 0.25 x1 < 5 0.21 0.33 (0.47)(0.15)+(0.53)(0.21) (0.47)(0.25)+(0.53)(0.33) Total = 0.18 = 0.29 x2 < 7.5 x2 ≥ 7.5 Total x2 < 1.5 x2 ≥ 1.5 Total 234 0.39 0 (0.83)(0.39) + (0.17)(0) = 0.32 0.47 0 (0.83)(0.47) + (0.17)(0) = 0.39 0.43 0 (0.14)(0) + (0.86)(0.43) = 0.37 0.49 0 (0.14)(0) + (0.86)(0.49) = 0.42 x2 ≥ 1.5 37 49 86 Ensemble Methods • Like individual regression trees, single classification trees – are not optimal classification methods. – have high variability—small changes in the data can drastically affect the structure of the tree. • Bagging, random forests, and boosting can also be implemented for classification problems 235 Bagging, Random Forests, and Boosting • Each of these ensemble methods are implemented in the same way as in regression. • The objective is to minimize misclassification error – The loss function changes to exponential loss rather than squared error loss. • Tuning parameters for these methods are the same as in regression 236 Neural Networks • Like PLS, neural networks for classification translate the classes to a set of binary (zero/one) variables. • The binary variables are modeled using the predictors and the softmax technique is used to make sure that the model outputs behave like probabilities 237 Fitting Neural Networks • As in regression models, there are two complexity parameters: – The number of hidden units – The amount of weight decay • The second parameter helps determine the smoothness of the classification boundaries • For the example data: – nnetMovie.gif 238 Support Vector Machines (SVMs) • SVMs for classification use a completely different objective function: – the margin • Suppose we have two predictors and a bunch of compounds • We may want to classify compounds as active or inactive • Let’s further suppose that these two predictors completely separate these classes 239 The Margin • There are an infinite number of straight lines that we can use to separate these two groups – some must be better than others • The margin is a defined by equally spaced boundaries on each side of the line 240 The Margin • To maximize the margin, we try to make it as large as possible – without capturing any compounds • As the margin increases, the solution becomes more robust • SVMs maximize the margin to estimate parameters 241 Support Vectors and Data Reduction • When the classes overlap, points are allowed within the margin – the number of points is controlled by a cost parameter • The points that are within the margin (or on it’s boundary) are the support vectors • It turns out that the prediction function only uses the support vectors – the prediction equation is more compact and efficient – the model may be more robust to outliers 242 Nonlinear Boundaries • Similar to regression models, the “kernel trick” can be used to generate highly nonlinear class boundaries • For classification, there are two common kernel functions – polynomial (3 tuning variables) – radial basis functions (2 parameters) 243 SVM Example Class Boundary RBF Kernel 244 79 SVs (31.6%) The Effect of the Cost Parameter • As the cost parameter is increased, the model will work very hard to correctly classify the compounds – This can lead to over-fitting • To see the effect of the cost parameter, the link below shows an animation for a radial basis function SVM – SvmMovieB.gif • Note that, as the boundary becomes more complicated, the #SV decreases – The margin is becoming very small 245 Nearest Neighbor Classifiers • To predict the class of a new compound, this procedure uses the most frequent class of the closest k neighbors – if a tie, randomly pick from the most frequent classes • k, the number of neighbors, is the tuning parameter • Since distance is used to define the nearest points, the predictors should be centered and scaled 246 Nearest Neighbor Classifiers • For the simulated data, the model was tuned across k values from 1 to 20 – 7 neighbors was found to be optimal • k-NN class boundaries tend to be somewhat jagged but smooth out as k increases 247 Naïve Bayes • Recall Bayes theorem: • Of course, the predictor distributions are usually multivariate and these probabilities would involve multidimensional integration 248 Naïve Bayes • In “naïve Bayes,” aka “Idiot’s Bayes,” the relationships between predictors are ignored – i.e all predictors are treated as uncorrelated 249 Naïve Bayes • Despite this assumption, this model usually is very competitive, even with strong correlations • How do we estimate continuous predictor distributions? – parametrically: assume normality and use the sample mean and variance – non-parametrically: use a nonparametric density estimator 250 Naïve Bayes • For example, looking at only the distribution of predictor A in our example, we see a slight shift between the distributions of the predictor for each class: 251 Naïve Bayes • If a new sample has a value of predictor A = 1, it is more likely to be active – active density ~ 0.40 – inactive density ~ 0.17 252 Naïve Bayes • For predictor B, the inactive probability is much larger for values between -0.5 and 0.5 • For each predictor, the distributions are modeled – class probabilities can be computed for each predictor • The final class probability is calculated by multiplying all the probabilities together 253 A Tale of Two Samples Sample 1 254 Sample 2 Pred A Pred B Pred B Pred A -1 0 Total -1 -1 Total Active 0.40 0.14 0.06 0.40 0.30 0.12 Inactive 0.17 0.62 0.10 0.17 0.08 0.01 Naïve Bayes and Many Predictors • Like LDA, naïve Bayes models can overfit when many noisy predictors are included in the model • As with LDA, we simulated noise data and were able to see class separation increase as the number of predictors went up 255 Naïve Bayes Classifiers • Class boundaries for naïve Bayes models can show circular or elliptical islands • Since the predictors are treated as uncorrelated, there cannot be any diagonal ellipses 256 Example: Prediction of Spam • These data were collect by HP. 4,601 e-mails were classified as spam or not spam. • Predictor variables are derived form the emails related to the frequency of words or characters in the e-mail. Variables include: – A set of word frequency variables. For example, the variable make measures the relative frequency of that word in the email – Variables related to numbers: words that start with numbers are also measured. For example, the variable num415 measures how often the number 415 appears – Other variables relate to special characters (e.g. the variable charExclamation) or capital letters (capitalAve) 257 Example: Prediction of Spam • We would like to classify emails as being spam with an emphasis on high specificity, i.e. a low probability of nonspam being labeled as spam • For training, an 80% split was used via stratified random sampling 258 Method Comparison 259 Method Comparison 260 ROC Comparison 261 Classification Datasets 262 Glaucoma Data • 62 variables are derived from a confocal laser scanning image of the optic nerve head, describing its morphology. Observations are from normal and glaucomatous eyes, respectively. Examples of variables are: – as: superior area – vbss: volume below surface temporal – mhcn: mean height contour nasal – vari: volume above reference inferior, etc • We would like to predict whether a subject has glaucoma given their imaging data 263 Predicting Diabetes in Pima Indians • These data are from Pima Indian women living in Arizona. Several variables were collected, such as: – pregnant: number of pregnancies – glucose: plasma glucose levels – pressure: diastolic BP – mass: body mass index – pedigree: diabetic pedigree function, – age – diabetes: negative or positive – triceps: skin fold thickness – insulin: serum insulin • We would like to predict a new Indian woman's diabetic status given their other information. 264 Classification Backup Slides 265 FDA Pre-Processing • FDA models often use the MARS hinge functions, so they share similar properties. • FDA models are resistant to zero- and near-zero variance predictors • Highly correlated predictors are allowed, but this can lead to significant amount of randomness during the predictor selection process – The split choice between two highly correlated predictors becomes a toss-up • Centering and scaling are not required but are suggested 266 Tree Pre-Processing • Same as for regression… – missing predictor values are allowed – centering and scaling are not required • centering and scaling do not affect results – highly correlated predictors are allowed • Including highly correlated predictors can cause instability and make predictor importance rankings somewhat random – zero- and near-zero variance predictors are allowed 267 RDA Pre-Processing • RDA models are cannot deal with zero- and near-zero variance predictors – they must be removed • Highly correlated predictors are allowed, but not suggested – However, perfectly correlated predictors will cause the model to fail • Centering and scaling are not required but are suggested • Additionally, there cannot be linear dependencies between predictors 268 Neural Network Pre-Processing • Neural network models will not fail with zero-variance predictors • However, these models use a large number of parameters and near-zero variance predictors may lead to numerical issues such as a failure to converge • Highly correlated predictors should be removed. • Centering and scaling are required 269 Nearest Neighbor Pre-Processing • These models are resistant to zero- and near-zero variance predictors as well as highly correlated predictors • Centering and scaling are required 270 Naïve Bayes Pre-Processing • These model will not fail with zero-variance predictors • Highly correlated predictors are also allowed. • Centering and scaling are not required 271 Model Building Training Other Considerations 272 Variables to Select • Variables thought to be related to the response should be included in the model • Sometimes we don’t know if a set of variables are related to the response • Should these be included in the analysis? • If the variables are not related to the response, then we are including noise into our predictor set • What happens to the performance of the techniques when noise is added? – Can we still find signal? 273 Illustration • To the blood brain barrier data of Mente and Lombardo (2005), we have added 10, 50, 100, and 200 random predictors • For each of these new data sets, we have built each regression model, using cross-validation to determine the optimal parameter settings • The results are on the following slides – Keep in mind that these results are for one example – Methods may have different rankings for other examples 274 Performance Comparison R2: CV for Training Set 0.5 0.4 0.3 0.2 0.1 0 0 50 Noise 275 100 150 200 Performance Comparison R2: Test Set 0.5 0.4 0.3 0.2 0.1 0 50 Noise 276 100 150 200 Variables to Select • Hopefully, we’ve demonstrated that resampling is a good way to avoid over-fitting • Realize that predictor selection is part of the modeling process • Doing predictor selection outside of crossvalidation can lead to sever predictor selection bias – and potential over-fitting (but you won’t know until a test set) 277 Effects of Categorizing a Continuous Response • A majority of responses are measured on a continuous scale • The continuous scale allows us to compare observations on their original scale • Sometimes the continuous response naturally falls into two or more modes – If the relative distance between these modes is not relevant, then the response can be binned – However, if the distance between modes is relevant, then we lose information by binning the response • Binning a continuous response that does not have natural modes will make us lose even more information and will degrade model 278 Thanks • Thanks for sitting through all this • More thanks to: – Benevolent overlords David Potter and Ed Kadyszewski – Nathan Coulter and Gautam Bhola for computing support – Pfizer Chemistry for feedback on earlier versions of this training 279