Appendix A Course Notes
advertisement

Basic Results in Probability and
Statistics
KNNL – Appendix A
A.1 Summation and Product Operators
Summation Operator
n
n
Y Y ... Y
i
i 1
1
If k is a constant:
n
n
i 1
n
n
Y Z Y Z
i
i 1
i
i 1
i
i 1
i
n
If a, c are constants:
n
a cY na c Y
i
i 1
n
m
n
Y Y
i 1 j 1
ij
i 1
i1
Y1 j ... Ynj Yij
m
j 1
j 1 i 1
Product Operator
Y Y
i 1
1
2
Y3 ...Yn
i 1
i
... Yim Y11 ... Y1m Y21 ... Y2 m ... Yn1 ... Ynm
m
n
k nk
n
A.2 Probability
Addition Theorem
Ai , Aj are 2 events defined on a sample space.
P Ai Aj P Ai P Aj P Ai Aj
P Ai Aj Probability at least one occurs
where:
P Ai Aj Probability both occur
Multiplication Theorem (Can be obtained from counts when data are in contingency table)
P A A
i
j
P A | A
i j
P A
j
P A | A
j i
where P A | A Probabilty A occurs given A has occured
i
j
i j
P A A
j
i
P A A P A P A | A P A P A | A
j
i j i
i
j i j
P A
i
Complementary Events
i
P Ai 1 P A
where Ai event A does not occur
i
P Ai Aj P Ai A j
A.3 Random Variables (Univariate)
Probability (Density) Functions
Discrete (RV Y takes on masses of probability at specific points Y1 ,...,Yk ):
f Ys P Y Ys s 1,..., k
Continuous (RV Y takes on density of probability over ranges of points on continuum)
f Y density at Y (confusing notation, often written f y where y is specific point and Y is RV)
Expected Value (Long Run Average Outcome, aka Mean)
k
Discrete: Y E Y Ys f Ys
s 1
Continuous: Y E Y Yf Y dY yf y dy
a, c constants E a cY a cE Y a c Y E a a E cY cE Y c Y
Variance (Average Squared Distance from Expected Value)
Y2 2 Y E Y E Y E Y Y
2
2
Equivalently (Computationally easier): Y2 2 Y E Y 2 E Y E Y 2 Y2
2
a, c constants 2 a cY c 2 2 Y c 2 Y2 2 a 0 2 cY c 2 2 Y c 2 Y2
A.3 Random Variables (Bivariate)
Joint Probability Function - Discrete Case (Generalizes to Densities in Continuous Case)
Random Variables (Outcomes observed on same unit) Y , Z (k possibilities for Y , m for Z ) :
g Ys , Z t P Y Ys Z Z t s 1,..., k ; t 1,..., m
Probability Y Ys and Z Z t
Marginal Probability Function - Discrete Case (Generalizes to Densities in Continuous Case):
m
f Ys g Ys , Z t Probability Y Ys
t 1
k
h Z t g Ys , Z t
s 1
Probability Z Z t
Continuous: Replace summations with integrals
Conditional Probability Function - Discrete Case (Generalizes to Densities in Continuous Case) :
f Ys | Z t
h Z t | Ys
g Ys , Z t
h Zt
g Ys , Z t
f Ys
h Z t 0; s 1,..., k
f Ys 0; t 1,..., m
Probability Y Ys given Z Z t
Probability Z Z t given Y Ys
A.3 Covariance, Correlation, Independence
Covariance - Average of Product of Distances from Means
YZ Y , Z E Y E Y Z E Z E Y Y Z Z
Equivalently (for computing): YZ Y , Z E YZ E Y E Z E YZ Y Z
k
m
Note: Discrete: E YZ Ys Z t g Ys , Z t
(Replace summations with integrals in continuous case)
s 1 t 1
a1 , c1 , a2 , c2 are constants a1 c1Y , a2 c2 Z c1c2 YZ c1c2 Y , Z
c1Y , c2 Z c1c2 YZ c1c2 Y , Z a1 Y , a2 Z YZ Y , Z
Correlation: Covariance scaled to lie between -1 and +1 for measure of association strength
Standardized Random Variables (Scaled to have mean=0, variance=1) Y '
YZ Y , Z Y ', Z '
Y , Z
Y Z
Y E Y
Y
1 Y , Z 1
Y , Z Y , Z 0 Y , Z are uncorrelated (not necessarily independent)
Independent Random Variables
Y , Z are independent if and only if g Ys , Z t f Ys h Z t s 1,..., k ; t 1,..., m
If Y , Z are jointly normally distributed and Y , Z 0 then Y , Z are independent
Y Y
Y
Linear Functions of RVs
n
U aiYi
i 1
ai constants Yi random variables
E Yi i 2 Yi i2 Yi , Y j ij
n
n
n
E U E aiYi ai E Yi ai i
i 1
i 1
i 1
n
n 1 n
n
n n
2 2
U aiYi ai a j ij ai i 2 ai a j ij
i 1
i 1 j i 1
i 1
i 1 j 1
2
2
n 2 E a1Y1 a2Y2 a1 E Y1 a2 E Y2 a11 a2 2
2 a1Y1 a2Y2 a12 2 Y1 a22 2 Y2 2a1a2 Y1 , Y2 a12 12 a22 22 2a1a2 12
Linear Functions of RVs
n
n 2 2
Y1 ,..., Yn independent U aiYi ai i
i 1
i 1
2
2
Special Cases Y1 , Y2 independent :
U1 Y1 Y2
2 U1 2 Y1 Y2 (1) 2 12 (1) 2 22 12 22
U 2 Y1 Y2
2 U 2 2 Y1 Y2 (1) 2 12 (1) 2 22 12 22
n
n
n
Y1 ,..., Yn independent aiYi , ciYi ai ci i2
i 1
i 1
i 1
Special Case Y1 , Y2 independent :
U1 ,U 2 Y1 Y2 , Y1 Y2 (1)(1) 12 (1)( 1) 22 12 22
Central Limit Theorem
• When random samples of size n are selected from any
population with mean and finite variance 2, the
sampling distribution of the sample mean will be
approximately normally distributed for large n:
n
Y
Y
i 1
n
i
2
1
Yi ~ N ,
n
i 1 n
n
approximately, for large n
Z-table can be used to approximate probabilities of ranges of values for sample
means, as well as percentiles of their sampling distribution
Normal (Gaussian) Distribution
• Bell-shaped distribution with tendency for individuals to
clump around the group median/mean
• Used to model many biological phenomena
• Many estimators have approximate normal sampling
distributions (see Central Limit Theorem)
• Notation: Y~N(,2) where is mean and 2 is variance
1 (Y ) 2
1
f Y
exp
Y , , 0
2
2
2
Obtaining Probabilities in EXCEL:
To obtain: F(y)=P(Y≤y)
Use Function:
=NORMDIST(y,,,1)
Table B.1 (p. 1316) gives the cdf for standardized normal random variables: z=(y-)/
~ N(0,1) for values of z ≥ 0 (obtain tail probabilities by complements and symmetry)
Normal Distribution – Density Functions (pdf)
Normal Densities
0.045
0.04
0.035
0.03
0.025
f(y)
N(100,400)
0.02
N(100,100)
0.015
N(100,900)
0.01
N(75,400)
0.005
N(125,400)
0
0
50
100
y
150
200
Second Decimal Place of z
Integer
part and
first
decimal
place of
z
F(z)
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2.0
2.1
2.2
2.3
2.4
2.5
2.6
2.7
2.8
2.9
3.0
0.00
0.5000
0.5398
0.5793
0.6179
0.6554
0.6915
0.7257
0.7580
0.7881
0.8159
0.8413
0.8643
0.8849
0.9032
0.9192
0.9332
0.9452
0.9554
0.9641
0.9713
0.9772
0.9821
0.9861
0.9893
0.9918
0.9938
0.9953
0.9965
0.9974
0.9981
0.9987
0.01
0.5040
0.5438
0.5832
0.6217
0.6591
0.6950
0.7291
0.7611
0.7910
0.8186
0.8438
0.8665
0.8869
0.9049
0.9207
0.9345
0.9463
0.9564
0.9649
0.9719
0.9778
0.9826
0.9864
0.9896
0.9920
0.9940
0.9955
0.9966
0.9975
0.9982
0.9987
0.02
0.5080
0.5478
0.5871
0.6255
0.6628
0.6985
0.7324
0.7642
0.7939
0.8212
0.8461
0.8686
0.8888
0.9066
0.9222
0.9357
0.9474
0.9573
0.9656
0.9726
0.9783
0.9830
0.9868
0.9898
0.9922
0.9941
0.9956
0.9967
0.9976
0.9982
0.9987
0.03
0.5120
0.5517
0.5910
0.6293
0.6664
0.7019
0.7357
0.7673
0.7967
0.8238
0.8485
0.8708
0.8907
0.9082
0.9236
0.9370
0.9484
0.9582
0.9664
0.9732
0.9788
0.9834
0.9871
0.9901
0.9925
0.9943
0.9957
0.9968
0.9977
0.9983
0.9988
0.04
0.5160
0.5557
0.5948
0.6331
0.6700
0.7054
0.7389
0.7704
0.7995
0.8264
0.8508
0.8729
0.8925
0.9099
0.9251
0.9382
0.9495
0.9591
0.9671
0.9738
0.9793
0.9838
0.9875
0.9904
0.9927
0.9945
0.9959
0.9969
0.9977
0.9984
0.9988
0.05
0.5199
0.5596
0.5987
0.6368
0.6736
0.7088
0.7422
0.7734
0.8023
0.8289
0.8531
0.8749
0.8944
0.9115
0.9265
0.9394
0.9505
0.9599
0.9678
0.9744
0.9798
0.9842
0.9878
0.9906
0.9929
0.9946
0.9960
0.9970
0.9978
0.9984
0.9989
0.06
0.5239
0.5636
0.6026
0.6406
0.6772
0.7123
0.7454
0.7764
0.8051
0.8315
0.8554
0.8770
0.8962
0.9131
0.9279
0.9406
0.9515
0.9608
0.9686
0.9750
0.9803
0.9846
0.9881
0.9909
0.9931
0.9948
0.9961
0.9971
0.9979
0.9985
0.9989
0.07
0.5279
0.5675
0.6064
0.6443
0.6808
0.7157
0.7486
0.7794
0.8078
0.8340
0.8577
0.8790
0.8980
0.9147
0.9292
0.9418
0.9525
0.9616
0.9693
0.9756
0.9808
0.9850
0.9884
0.9911
0.9932
0.9949
0.9962
0.9972
0.9979
0.9985
0.9989
0.08
0.5319
0.5714
0.6103
0.6480
0.6844
0.7190
0.7517
0.7823
0.8106
0.8365
0.8599
0.8810
0.8997
0.9162
0.9306
0.9429
0.9535
0.9625
0.9699
0.9761
0.9812
0.9854
0.9887
0.9913
0.9934
0.9951
0.9963
0.9973
0.9980
0.9986
0.9990
0.09
0.5359
0.5753
0.6141
0.6517
0.6879
0.7224
0.7549
0.7852
0.8133
0.8389
0.8621
0.8830
0.9015
0.9177
0.9319
0.9441
0.9545
0.9633
0.9706
0.9767
0.9817
0.9857
0.9890
0.9916
0.9936
0.9952
0.9964
0.9974
0.9981
0.9986
0.9990
Chi-Square Distribution
• Indexed by “degrees of freedom (n)” X~cn2
• Z~N(0,1) Z2 ~c12
• Assuming Independence:
X 1 ,..., X n ~ cn i
2
i 1,..., n
n
X
i 1
i
~ c2 n
i
Density Function:
1
n
f x
x
n
2n 2
2
2 1 x 2
e
x 0,n 0
Obtaining Probabilities in EXCEL:
To obtain: 1-F(x)=P(X≥x)
Use Function: =CHIDIST(x,n)
Table B.3, p. 1319 Gives percentiles of c2 distributions: P{c2(n) ≤ c2(A;n)} = A
Chi-Square Distributions
Chi-Square Distributions
0.2
0.18
df=4
0.16
0.14
df=10
df=20
0.12
f(X^2)
f1(y)
df=30
0.1
f2(y)
f3(y)
df=50
f4(y)
0.08
f5(y)
0.06
0.04
0.02
0
0
10
20
30
40
X^2
50
60
70
Critical Values for Chi-Square Distributions (Mean=n, Variance=2n)
df\F(x)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
40
50
60
70
80
90
100
0.005
0.000
0.010
0.072
0.207
0.412
0.676
0.989
1.344
1.735
2.156
2.603
3.074
3.565
4.075
4.601
5.142
5.697
6.265
6.844
7.434
8.034
8.643
9.260
9.886
10.520
11.160
11.808
12.461
13.121
13.787
20.707
27.991
35.534
43.275
51.172
59.196
67.328
0.01
0.000
0.020
0.115
0.297
0.554
0.872
1.239
1.646
2.088
2.558
3.053
3.571
4.107
4.660
5.229
5.812
6.408
7.015
7.633
8.260
8.897
9.542
10.196
10.856
11.524
12.198
12.879
13.565
14.256
14.953
22.164
29.707
37.485
45.442
53.540
61.754
70.065
0.025
0.001
0.051
0.216
0.484
0.831
1.237
1.690
2.180
2.700
3.247
3.816
4.404
5.009
5.629
6.262
6.908
7.564
8.231
8.907
9.591
10.283
10.982
11.689
12.401
13.120
13.844
14.573
15.308
16.047
16.791
24.433
32.357
40.482
48.758
57.153
65.647
74.222
0.05
0.004
0.103
0.352
0.711
1.145
1.635
2.167
2.733
3.325
3.940
4.575
5.226
5.892
6.571
7.261
7.962
8.672
9.390
10.117
10.851
11.591
12.338
13.091
13.848
14.611
15.379
16.151
16.928
17.708
18.493
26.509
34.764
43.188
51.739
60.391
69.126
77.929
0.1
0.016
0.211
0.584
1.064
1.610
2.204
2.833
3.490
4.168
4.865
5.578
6.304
7.042
7.790
8.547
9.312
10.085
10.865
11.651
12.443
13.240
14.041
14.848
15.659
16.473
17.292
18.114
18.939
19.768
20.599
29.051
37.689
46.459
55.329
64.278
73.291
82.358
0.9
2.706
4.605
6.251
7.779
9.236
10.645
12.017
13.362
14.684
15.987
17.275
18.549
19.812
21.064
22.307
23.542
24.769
25.989
27.204
28.412
29.615
30.813
32.007
33.196
34.382
35.563
36.741
37.916
39.087
40.256
51.805
63.167
74.397
85.527
96.578
107.565
118.498
0.95
3.841
5.991
7.815
9.488
11.070
12.592
14.067
15.507
16.919
18.307
19.675
21.026
22.362
23.685
24.996
26.296
27.587
28.869
30.144
31.410
32.671
33.924
35.172
36.415
37.652
38.885
40.113
41.337
42.557
43.773
55.758
67.505
79.082
90.531
101.879
113.145
124.342
0.975
5.024
7.378
9.348
11.143
12.833
14.449
16.013
17.535
19.023
20.483
21.920
23.337
24.736
26.119
27.488
28.845
30.191
31.526
32.852
34.170
35.479
36.781
38.076
39.364
40.646
41.923
43.195
44.461
45.722
46.979
59.342
71.420
83.298
95.023
106.629
118.136
129.561
0.99
6.635
9.210
11.345
13.277
15.086
16.812
18.475
20.090
21.666
23.209
24.725
26.217
27.688
29.141
30.578
32.000
33.409
34.805
36.191
37.566
38.932
40.289
41.638
42.980
44.314
45.642
46.963
48.278
49.588
50.892
63.691
76.154
88.379
100.425
112.329
124.116
135.807
0.995
7.879
10.597
12.838
14.860
16.750
18.548
20.278
21.955
23.589
25.188
26.757
28.300
29.819
31.319
32.801
34.267
35.718
37.156
38.582
39.997
41.401
42.796
44.181
45.559
46.928
48.290
49.645
50.993
52.336
53.672
66.766
79.490
91.952
104.215
116.321
128.299
140.169
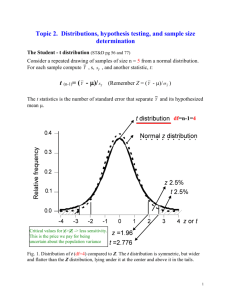
Student’s t-Distribution
• Indexed by “degrees of freedom (n)” X~tn
• Z~N(0,1), X~cn2
• Assuming Independence of Z and X:
T
Z
~ t n
Xn
Obtaining Probabilities in EXCEL:To obtain: 1-F(t)=P(T≥t)
Use Function: =TDIST(t,n)
Table B.2 pp. 1317-1318 gives percentiles of the t-distribution:
P{t(n) ≤ t(A;n)} = A for A > 0.5
for A < 0.5: P{t(n) ≤ -t(A;n)} = 1-A
t(3), t(11), t(24), Z Distributions
0.45
0.4
0.35
0.3
0.25
Density
f(t_3)
0.2
f(t_11)
f(t_24)
0.15
Z~N(0,1)
0.1
0.05
0
-3
-2
-1
0
1
t (z)
2
3
Critical Values for Student’s t-Distributions (Mean=n, Variance=2n)
df\F(t)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
40
50
60
70
80
90
100
0.9
3.078
1.886
1.638
1.533
1.476
1.440
1.415
1.397
1.383
1.372
1.363
1.356
1.350
1.345
1.341
1.337
1.333
1.330
1.328
1.325
1.323
1.321
1.319
1.318
1.316
1.315
1.314
1.313
1.311
1.310
1.303
1.299
1.296
1.294
1.292
1.291
1.290
0.95
6.314
2.920
2.353
2.132
2.015
1.943
1.895
1.860
1.833
1.812
1.796
1.782
1.771
1.761
1.753
1.746
1.740
1.734
1.729
1.725
1.721
1.717
1.714
1.711
1.708
1.706
1.703
1.701
1.699
1.697
1.684
1.676
1.671
1.667
1.664
1.662
1.660
0.975
12.706
4.303
3.182
2.776
2.571
2.447
2.365
2.306
2.262
2.228
2.201
2.179
2.160
2.145
2.131
2.120
2.110
2.101
2.093
2.086
2.080
2.074
2.069
2.064
2.060
2.056
2.052
2.048
2.045
2.042
2.021
2.009
2.000
1.994
1.990
1.987
1.984
0.99
31.821
6.965
4.541
3.747
3.365
3.143
2.998
2.896
2.821
2.764
2.718
2.681
2.650
2.624
2.602
2.583
2.567
2.552
2.539
2.528
2.518
2.508
2.500
2.492
2.485
2.479
2.473
2.467
2.462
2.457
2.423
2.403
2.390
2.381
2.374
2.368
2.364
0.995
63.657
9.925
5.841
4.604
4.032
3.707
3.499
3.355
3.250
3.169
3.106
3.055
3.012
2.977
2.947
2.921
2.898
2.878
2.861
2.845
2.831
2.819
2.807
2.797
2.787
2.779
2.771
2.763
2.756
2.750
2.704
2.678
2.660
2.648
2.639
2.632
2.626
F-Distribution
• Indexed by 2 “degrees of freedom (n1,n2)” W~Fn1,n2
• X1 ~cn12, X2 ~cn22
• Assuming Independence of X1 and X2:
W
X1 n1
~ F n 1 ,n 2
X2 n2
Obtaining Probabilities in EXCEL: To obtain: 1-F(w)=P(W≥w) Use Function:
=FDIST(w,n1,n2)
Table B.4 pp.1320-1326 gives percentiles of F-distribution:
P{F(n1,n2) ≤ F(A;n1,n2)} = A For values of A > 0.5
For values of A < 0.5 (lower tail probabilities):
F(A;n1 ,n2) = 1/ F(A;n1,n2)
F-Distributions
0.9
0.8
0.7
Density Function of F
0.6
0.5
f(5,5)
f(5,10)
0.4
f(10,20)
0.3
0.2
0.1
0
0
1
2
3
4
5
-0.1
F
6
7
8
9
10
Critical Values for F-distributions P(F ≤ Table Value) = 0.95
df2\df1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
40
50
60
70
80
90
100
1
161.45
18.51
10.13
7.71
6.61
5.99
5.59
5.32
5.12
4.96
4.84
4.75
4.67
4.60
4.54
4.49
4.45
4.41
4.38
4.35
4.32
4.30
4.28
4.26
4.24
4.23
4.21
4.20
4.18
4.17
4.08
4.03
4.00
3.98
3.96
3.95
3.94
2
199.50
19.00
9.55
6.94
5.79
5.14
4.74
4.46
4.26
4.10
3.98
3.89
3.81
3.74
3.68
3.63
3.59
3.55
3.52
3.49
3.47
3.44
3.42
3.40
3.39
3.37
3.35
3.34
3.33
3.32
3.23
3.18
3.15
3.13
3.11
3.10
3.09
3
215.71
19.16
9.28
6.59
5.41
4.76
4.35
4.07
3.86
3.71
3.59
3.49
3.41
3.34
3.29
3.24
3.20
3.16
3.13
3.10
3.07
3.05
3.03
3.01
2.99
2.98
2.96
2.95
2.93
2.92
2.84
2.79
2.76
2.74
2.72
2.71
2.70
4
224.58
19.25
9.12
6.39
5.19
4.53
4.12
3.84
3.63
3.48
3.36
3.26
3.18
3.11
3.06
3.01
2.96
2.93
2.90
2.87
2.84
2.82
2.80
2.78
2.76
2.74
2.73
2.71
2.70
2.69
2.61
2.56
2.53
2.50
2.49
2.47
2.46
5
230.16
19.30
9.01
6.26
5.05
4.39
3.97
3.69
3.48
3.33
3.20
3.11
3.03
2.96
2.90
2.85
2.81
2.77
2.74
2.71
2.68
2.66
2.64
2.62
2.60
2.59
2.57
2.56
2.55
2.53
2.45
2.40
2.37
2.35
2.33
2.32
2.31
6
233.99
19.33
8.94
6.16
4.95
4.28
3.87
3.58
3.37
3.22
3.09
3.00
2.92
2.85
2.79
2.74
2.70
2.66
2.63
2.60
2.57
2.55
2.53
2.51
2.49
2.47
2.46
2.45
2.43
2.42
2.34
2.29
2.25
2.23
2.21
2.20
2.19
7
236.77
19.35
8.89
6.09
4.88
4.21
3.79
3.50
3.29
3.14
3.01
2.91
2.83
2.76
2.71
2.66
2.61
2.58
2.54
2.51
2.49
2.46
2.44
2.42
2.40
2.39
2.37
2.36
2.35
2.33
2.25
2.20
2.17
2.14
2.13
2.11
2.10
8
238.88
19.37
8.85
6.04
4.82
4.15
3.73
3.44
3.23
3.07
2.95
2.85
2.77
2.70
2.64
2.59
2.55
2.51
2.48
2.45
2.42
2.40
2.37
2.36
2.34
2.32
2.31
2.29
2.28
2.27
2.18
2.13
2.10
2.07
2.06
2.04
2.03
9
240.54
19.38
8.81
6.00
4.77
4.10
3.68
3.39
3.18
3.02
2.90
2.80
2.71
2.65
2.59
2.54
2.49
2.46
2.42
2.39
2.37
2.34
2.32
2.30
2.28
2.27
2.25
2.24
2.22
2.21
2.12
2.07
2.04
2.02
2.00
1.99
1.97
10
241.88
19.40
8.79
5.96
4.74
4.06
3.64
3.35
3.14
2.98
2.85
2.75
2.67
2.60
2.54
2.49
2.45
2.41
2.38
2.35
2.32
2.30
2.27
2.25
2.24
2.22
2.20
2.19
2.18
2.16
2.08
2.03
1.99
1.97
1.95
1.94
1.93
A.5 Statistical Estimation - Properties
Properties of Estimators:
Parameter:
Estimator: function of Y1 ,..., Yn
1) Unbiased: E
2) Consistent: lim P 0
n
for any > 0
3) Sufficient if conditional joint probability of sample, given does not depend on
4) Minimum Variance:
2
2
*
for all
*
Note: If an estimator is unbiased (easy to show) and its variance goes to zero as its
sample size gets infinitely large (easy to show), it is consistent. It is tougher to show
that it is Minimum Variance, but general results have been obtained in many standard
cases.
A.5 Maximum Likelihood and Least Squares
Maximum Likelihood (ML) Estimators:
Y ~ f Y ; Probability function for Y that depends on parameter
Random Sample (independent) Y1 ,..., Yn with joint probability function:
n
g Y1 ,..., Yn f Y ;
i 1
When viewed as function of , given the observed data (sample):
n
Likelihood function: L f Y ;
Goal: maximize L with respect to .
i 1
Under general conditions, ML estimators are consistent and sufficient
Least Squares (LS) Estimators
Yi fi i
where fi is a known function of the parameter and i are random variables, usually with E i =0
n
Sum of Squares: Q Yi fi
2
Goal: minimize Q with respect to .
i 1
In many settings, LSestimators are unbiased and consistent.
One-Sample Confidence Interval for
• SRS from a population with mean is obtained.
• Sample mean, sample standard deviation are obtained
• Degrees of freedom are df= n-1, and confidence level
(1-a) are selected
• Level (1-a) confidence interval of form:
Y t 1 a / 2; n 1 s Y
s
s Y
n
Procedure is theoretically derived based on normally distributed data,
but has been found to work well regardless for moderate to large n
1-Sample t-test (2-tailed alternative)
• 2-sided Test: H0: = 0
• Decision Rule :
Ha: 0
– Conclude > 0 if Test Statistic (t*) > t(1-a/2;n-1)
– Conclude < 0 if Test Statistic (t*) <- t(1-a/2;n-1)
– Do not conclude Conclude 0 otherwise
• P-value: 2P(t(n-1) |t*|)
• Test Statistic:
t
*
Y 0
s Y
s Y s/ n
See Table A.1, p. 1307 for decision rules on 1-sided tests
Comparing 2 Means - Independent Samples
• Observed individuals from the 2 groups are samples from
distinct populations (identified by (1,12) and (2,22))
• Measurements across groups are independent
• Summary statistics obtained from the 2 groups:
Group 1: Mean: Y Std. Dev.: s1 Sample Size: n1
Group 2: Mean: Z Std. Dev.: s2 Sample Size: n2
Y
Y
i 1 i
n1
Y Y
n1
n1
s1
i 1
i
n1 1
2
obvious for Z
Sampling Distribution of
Y Z
• Underlying distributions normal sampling distribution is
normal, and resulting t-distribution with estimated std. dev.
• Mean, variance, standard error (Std. Dev. of estimator)
E Y Z Y Z 1 2
2 Y Z Y2 Z
2
1
2
2
12
n1
22
n2
Y Z
s Y Z
1
1
1
where: s Y Z s
n1 n2
Y Z
2
12
n1
22
n2
~ t with df = n1 n2 2
2
2
n
1
s
n
1
s
1
2
2
s2 1
n1 n2 2
Inference for 12 Normal Populations – Equal variances
1 a 100% Confidence Interval:
Y Z t 1 a / 2; n1 n2 2 s Y Z
• Interpretation (at the a significance level):
– If interval contains 0, do not reject H0: 1 = 2
– If interval is strictly positive, conclude that 1 > 2
– If interval is strictly negative, conclude that 1 < 2
H 0 : 1 2 0
Test Stat : t*
H A : 1 2 0
Y Z
s Y Z
Reject Reg : t * t 1 a / 2; n1 n2 2
Sampling Distribution of s2 (Normal Data)
• Population variance (2) is a fixed (unknown)
parameter based on the population of measurements
• Sample variance (s2) varies from sample to sample
(just as sample mean does)
• When Y~N(,2), the distribution of (a multiple of) s2
is Chi-Square with n-1 degrees of freedom.
• (n-1)s2/2 ~ c2 with df=n-1
(1-a)100% Confidence Interval for 2 (or )
• Step 1: Obtain a random sample of n items from the
population, compute s2
• Step 2: Obtain c2L = and c2U from table of critical
values for chi-square distribution with n-1 df
• Step 3: Compute the confidence interval for 2 based
on the formula below and take square roots of
bounds for 2 to obtain confidence interval for
2
2
(
n
1)
s
(
n
1)
s
2
(1 a )100% CI for :
,
2
2
cL
cU
where: cU2 c 2 1 a / 2; n 1
c L2 c 2 a / 2; n 1
Statistical Test for 2
• Null and alternative hypotheses
– 1-sided (upper tail): H0: 2 02 Ha: 2 > 02
– 1-sided (lower tail): H0: 2 02 Ha: 2 < 02
– 2-sided: H0: 2 = 02 Ha: 2 02
• Test Statistic
2
c obs
(n 1) s 2
02
• Decision Rule based on chi-square distribution w/ df=n-1:
– 1-sided (upper tail): Reject H0 if cobs2 > cU2 = c2(1-a;n-1)
– 1-sided (lower tail): Reject H0 if cobs2 < cL2 = c2(a;n-1)
– 2-sided: Reject H0 if cobs2 < cL2 = c2(a/2;n-1)(Conclude 2 < 02)
or if cobs2 > cU2 = c2(1-a/2;n-1) (Conclude 2 > 02 )
Inferences Regarding 2 Population Variances
• Goal: Compare variances between 2 populations
12
• Parameter: 2 (Ratio is 1 when variances are equal)
2
• Estimator:
s12
s22
(Ratio of sample variances)
• Distribution of (multiple) of estimator (Normal Data):
s12 12 s12 s22
2 2 ~F
2
2
s2 2 1 2
with df1 n1 1 and df 2 n2 1
F-distribution with parameters df1 = n1-1 and df2 = n2-1
Test Comparing Two Population Variances
• Assumption: the 2 populations are normally distributed
1-Sided Test: H 0 : 12 22
Test Statistic: Fobs
H a : 12 22
s12
2
s2
Rejection Region: Fobs F 1 a ; n1 1, n2 1
P value: P( F Fobs )
2-Sided Test: H 0 : 12 22
Test Statistic: Fobs
H a : 12 22
s12
2
s2
Rejection Region: Fobs F 1 a / 2; n1 1, n2 1
( 12 22 )
or Fobs F a / 2; n1 1, n2 1 =1/F 1 a / 2; n2 1, n1 1 ( 12 22 )
P value: 2min(P( F Fobs ), P( F Fobs ))
(1-a)100% Confidence Interval for 12/22
• Obtain ratio of sample variances s12/s22 = (s1/s2)2
• Choose a, and obtain:
– FL = F(a/2, n1-1, n2-1) = 1/ F(1-a/2, n2-1, n1-1)
– FU = F(1-a/2, n1-1, n2-1)
• Compute Confidence Interval:
s
s
FL , FU
s
s
2
1
2
2
2
1
2
2
Conclude population variances unequal if interval does not contain 1