Tutorial on Bayesian techniques for inference
advertisement

Tutorial on
Bayesian Techniques
for Inference
A. Asensio Ramos
Instituto de Astrofísica de Canarias
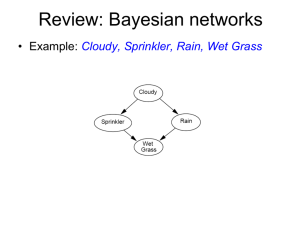
Outline
• General introduction
• The Bayesian approach to inference
• Examples
• Conclusions
The Big Picture
Deductive Inference
Predictions
Testable
Hypothesis
(theory)
Observation
Data
Hypothesis testing
Parameter estimation
Statistical Inference
The Big Picture
Available information is always incomplete
Our knowledge of nature is necessarily probabilistic
Cox & Jaynes demonstrated that probability calculus
fulfilling the rules
can be used to do statistical inference
Probabilistic inference
H1, H2, H3, …., Hn are hypothesis that we want to test
The Bayesian way is to estimate p(Hi|…) and select
depending on the comparison of their probabilities
But…
What are the p(Hi|…)???
What is probability? (Frequentist)
In frequentist approach, probability describes “randomness”
If we carry out the experiment many times, which is the distribution of
events (frequentist) p(x) is the histogram of random variable x
What is probability? (Bayesian)
We observe
this value
In Bayesian approach, probability describes “uncertainty”
Everything can be a random variable as we will see later
p(x) gives how probability is distributed among the possible
choice of x
Bayes theorem
It is trivially derived from the product rule
• Hi proposition asserting the truth of a hypothesis
• I proposition representing prior information
• D proposition representing data
Bayes theorem - Example
• Model M1 predicts a star at d=100 ly
• Model M2 predicts a star at d=200 ly
• Uncertainty in measurement is Gaussian with s=40 ly
• Measured distance is d=120 ly
Likelihood
Posteriors
Bayes theorem – Another example
2.3% false positive
1.4% false negative
(98.6% reliability)
Bayes theorem – Another example
You take the test and you get it positive. What is the
probability that you have the disease if the incidence is 1:10000?
H you have the disease
H you don’t have the disease
D1 your test is positive
Bayes theorem – Another example
10-4
10-4
0.986
0.986
0.9999
0.023
What is usually known as inversion
One proposes a model to explain observations
All inversion methods work by adjusting the parameters of
the model with the aim of minimizing a merit function that
compares observations with the synthesis from the model
Least-squares solution (maximum-likelihood) is the solution to the
inversion problem
Defects of standard inversion codes
• Solution is given as a set of model parameters (max. likelihood)
• Not necessary the optimal solution
• Sensitive to noise
• Error bars or confidence regions are scarce
• Gaussian errors
• Not easy to propagate errors
• Ambiguities, degeneracies, correlations are not detected
• Assumptions are not explicit
• Cannot compare models
Inversion as a probabilistic inference problem
Observations
Model
Parameter 1
Noise
Parameter 2
Parameter 3
Use Bayes theorem to propagate information
from data to our final state of knowledge
Likelihood
Posterior
Evidence
Prior
Priors
Contain information about model parameters that
we know before presenting the data
Assuming statistical independence for all
parameters the total prior can be calculated as
Typical priors
Top-hat function
(flat prior)
qmin
qmax
qi
Gaussian prior
(we know some values
are more probable
than others)
qi
Likelihood
Assuming normal (gaussian) noise, the likelihood can be calculated as
where the c2 function is defined as usual
In this case, the c2 function is specific for the the case of Stokes profiles
Visual example of Bayesian inference
Advantages of Bayesian approach
• “Best fit” values of parameters are e.g., mode/median of the posterior
• Uncertainties are credible regions of the posterior
• Correlation between variables of the model are captured
• Generalized error propagation (not only Gaussian and including correl.)
Integration over nuissance parameters (marginalization)
Bayesian inference – an example
Hinode
Beautiful posterior distributions
Field strength
Field inclination
Field azimuth
Filling factor
Not so beautiful posterior distributions - degeneracies
Field inclination
Inversion with local stray-light – be careful
si is the variance of the numerator
But… what happens if we propose a model like Orozco Suárez et al. (2007)
with a stray-light contamination obtained from a local
average on the surrounding pixels
From observations
Variance becomes dependent on stray-light contamination
It is usual to carry out inversions with a stray-light contamination
obtained from a local average on the surrounding pixels
Spatial correlations: use global stray-light
It is usual to carry out inversions with a stray-light contamination
obtained from a local average on the surrounding pixels
If M correlations tend to zero
Spatial correlations
Lesson: use global stray-light contamination
But… the most general inversion method is…
Model 1
Model 5
Model 2
Observations
Model 4
Model 3
Model comparison
Choose among the selected models the one
that is preferred by the data
Posterior for model Mi
Model likelihood is just the evidence
Model comparison (compare evidences)
Model 1
Model 5
Model 2
Model
comparison
Model 4
Model 3
Model comparison – a worked example
H0 : simple Gaussian
H1 : two Gaussians of equal width but unknown amplitude ratio
Model comparison – a worked example
H0 : simple Gaussian
H1 : two Gaussians of equal width but unknown amplitude ratio
Model comparison – a worked example
Model comparison – a worked example
Model H1 is 9.2 times more probable
Model comparison – an example
Model 1
1 magnetic component
Model 2
1 magnetic+1 non-magnetic
component
Model 3
2 magnetic components
Model 4
2 magnetic components
with (v2=0, a2=0)
Model comparison – an example
Model 1
1 magnetic component
9 free parameters
Model 2
1 magnetic+1 non-magnetic
component
17 free parameters
Model 2 is preferred by the data
“Best fit with the smallest number of parameters”
Model 3
2 magnetic components
20 free parameters
Model 4
2 magnetic components
with (v2=0, a2=0)
18 free parameters
Model averaging. One step further
Models {Mi, i=1..N} have a common subset of parameters y of interest
but each model depends on a different set of parameters q
or have different priors over these parameters
Posterior for y including all models
What all models have to say about parameters y
All of them give a “weighted vote”
Model averaging – an example
Hierarchical models
In the Bayesian approach, everything can be considered a random variable
PRIOR
PRIOR
PAR.
MODEL
LIKELIHOOD
MARGINALIZATION
NUISANCE PAR.
DATA
INFERENCE
Hierarchical models
In the Bayesian approach, everything can be considered a random variable
PRIOR
PRIOR
PAR.
MODEL
LIKELIHOOD
PRIOR
MARGINALIZATION
NUISANCE PAR.
PRIOR
DATA
INFERENCE
Bayesian Weak-field
Bayes theorem
Advantage: everything is close to analytic
Bayesian Weak-field – Hierarchical priors
Priors depend on some hyperparameters over which
we can again set priors and marginalize them
Bayesian Weak-field - Data
IMaX data
Bayesian Weak-field - Posteriors
Joint posteriors
Bayesian Weak-field - Posteriors
Marginal posteriors
Hierarchical priors - Distribution of longitudinal B
Hierarchical priors – Distribution of longitudinal B
We want to infer the distribution of longitudinal B from
many observed pixels taking into account uncertainties
Parameterize the distribution in terms of a vector a
Mean+variance
if Gaussian
Height of bins
if general
Hierarchical priors – Distribution of longitudinal B
Hierarchical priors – Distribution of longitudinal B
We generate N
synthetic profiles with
noise with
longitudinal field
sampled from a
Gaussian distribution
with standard deviation
25 Mx cm-2
Hierarchical priors – Distribution of any quantity
Bayesian image deconvolution
Bayesian image deconvolution
Maximum-likelihood solution (phase-diversity, MOMFBD,…)
PSF blurring
using linear expansion
Image is sparse
in any basis
Inference in a Bayesian framework
• Solution is given as a probability over model parameters
• Error bars or confidence regions can be easily obtained,
including correlations, degeneracies, etc.
• Assumptions are explicit on prior distributions
• Model comparison and model averaging is easily accomplished
• Hierarchical model is powerful for extracting information from data
Hinode data
Continuum
Total polarization
Asensio Ramos (2009)
Observations of Lites et al. (2008)
How much information? – Kullback-Leibler divergence
Measures “distance” between posterior and prior distributions
Field strength (37% larger than 1)
Field inclination (34% larger than 1)
Posteriors
Stray-light
Field inclination
Field strength
Field azimuth
Field inclination – Obvious conclusion
Linear polarization is fundamental to obtain reliable inclinations
Field inclination – Quasi-isotropic
Isotropic field
Our prior
Field inclination – Quasi-isotropic
Representation
Marginal distribution for each parameter
Sample N values from the posterior and all values are
compatible with observations
Field strength – Representation
All maps compatible with observations!!!
Field inclination
All maps compatible with observations!!!
In a galaxy far far away… (the future)
RAW
DATA
INSTRUMENTS
WITH SYSTEMATICS
PRIORS
MODEL
PRIORS
POSTERIOR+
MARGINALIZATION
NON-IMPORTANT
PARAMETERS
INFERENCE
Conclusions
• Inversion is not an easy task and has to be considered
as a probabilistic inference problem
• Bayesian theory gives us the tools for inference
• Expand our view of inversion as a model comparison/averaging
problem (no model is the absolute truth!)
Thank you
and be Bayesian, my friend!