Linear regression
advertisement

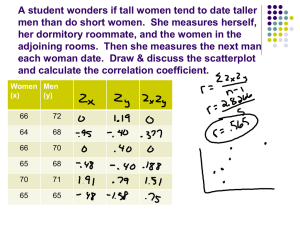
Objectives 2.3 Least-squares regression Regression lines Prediction and Extrapolation Correlation and r2 Transforming relationships Adapted from authors’ slides © 2012 W.H. Freeman and Company Straight Line Regression A regression is a formula that describes how a response variable y changes (on average) as an explanatory variable x changes. We often use a regression line to predict the value of y for a given value of x. The predicted value for y is often denoted yˆ. In regression, the distinction between explanatory and response variables is important. A straight line regression has the form yˆ b0 b1x y is the observed value yˆ is the predicted y value (y hat) b1 is the slope b0 is the y-intercept The least squares regression line The least-squares regression line is the unique line such that the sum of the squared vertical (y) differences between the data points and the line is as small as possible. (These differences are called residuals.) This is the line that best predicts y from x (not the other way). Distances between the points and line are squared so that they all are positive values. How to compute the slope and intercept: First we calculate the slope of the line, b1, from statistics we have already computed. b1 r r is the correlation. sy is the standard deviation of the response variable y. sx is the standard deviation of the explanatory variable x. sy sx Interpretation: b1 is the (average) change in the value of y when x is changed by 1 unit. Once we know b1, we can calculate b0, the y-intercept. b0 y b1 x x and y are the sample means of the x and y variables. Interpretation: b0 is the predicted value when x = 0 (although this value of x is not always meaningful). Different scale different intercept and slope It is important to note that if we change the scale of either the x or y axis that the slope and intercept will also change. To see this look at the yearly temperature data in (can be downloaded from Dostat) in Statcrunch and observe the effect it has when we change year to a different scale (observe that year is rather arbitrary, why use 2012 and not 10008?). Do not be fooled by the size of the slope. If it is small (what ever that means), it does not mean it is insignificant, or the correlation is small. The size of a slope depends on the scaling that we use. The significance depends on the standard error (more of this later on). Efficiency of a biofilter, by temperature In StatCrunch: Stat-Regression-Simple Linear yˆ 97.5 0.0757 x. For every degree that temperature goes up, the efficiency can be expected to increase by b1 = 0.0757 units. The predicted efficiency when temperature equals 10 is yˆ 97.5 0.0757 10 98.26. Relationship between ozone and carbon pollutants In StatCrunch: Stat-Regression-Simple Linear yˆ 0.0515 0.005708x. For each unit that carbon goes up, ozone can be expected to increase by b1 = 0.005708 units. The predicted efficiency when carbon equals 15 is yˆ .0515 0.005708 15 .1371. However, the relationship is not strong so the prediction may not be all that accurate. Categorical variables in scatterplots Often, things are not simple and one-dimensional. We need to group the data into categories to reveal trends. What may look like a positive linear relationship is in fact a series of negative linear associations. Here, the habitat for each observation is a lurking variable. Plotting data points from different habitats in different colors allows us to make that important distinction. Comparison of racing records over time for men and women. Each group shows a very strong negative linear relationship that would not be apparent without the gender categorization. Relationship between lean body mass and metabolic rate in men and women. Both men and women follow the same positive linear trend, but women show a stronger association. As a group, males typically have larger values for both variables. Correlation versus regression The correlation is a measure In regression we examine of spread (scatter) in both the the variation in the response x and y directions in the linear variable (y) given the relationship. explanatory variable (x). Coefficient of determination, R2 R2 is called the coefficient of determination. R2 represents the percentage of the variation of y that can be explained by the prediction from x. (That is, it is the amount of vertical scatter from the regression line relative to the overall vertical scatter.) R2 is meaningful for any fit of the response variable to one or more explanatory variables. In the case of straight line fit only, however, R2 = r2, where r is the correlation coefficient (positive or negative). The r-squared and the linear model The basic idea in statistical modeling is to fit the simplest model, which best explains the data. In the case of simple regression this means fitting a line through the points. The only model simpler than that is fitting a flat line (the slope is zero) through the points. The R-squared is a way of comparing the gain by fitting slope over a flat line. If the R-squared is 1, then the residuals are zero and the y-axis is totally determined by the x-axis (the linear model is best). If the rsquared is zero, then the constant model is best. Usually the Rsquared is somewhere in between. Note that the value of the slope can be very small (say 0.00003), but the R-squared can still be one. Efficiency of a biofilter, by temperature yˆ 97.5 0.0757 x. R2 = 79.4% is the proportion of the variation in Efficiency that is explained by the straight line regression on Temperature. Relationship between ozone and carbon pollutants In StatCrunch: Stat-Regression-Simple Linear yˆ 0.0515 0.005708x. R2 = 44.7% is the proportion of the variation in Ozone Level that is explained by the straight line regression on Carbon Pollutant Level. The distinction between explanatory and response variables is crucial in regression. If you exchange y for x in calculating the regression line, you will get a different line which is a predictor of x for a given value of y. This is because the least squares regression of y on x is concerned with the distance of all points from the line in the y direction only. Here is a plot of Hubble telescope data about galaxies moving away from earth. The solid line is the best prediction of y = velocity from x = distance. The dotted line is the best prediction of x = velocity from y = distance. Examples For example, if you want to predict the girth of a 8 week calf given his 8 week weight, then the response variable is the girth (it should be on the yaxis) and the explanatory variable is the weight (on the x-axis). Another example, is trying to predict your midterm scores. It makes sense to predict your midterm 3 score based on your midterm 2 score. Thus midterm 3 is the response variable (on y-axis) and midterm 2 is the explanatory variable in the x-axis. Residuals The distances from each point to the least-squares regression line give us potentially useful information about the contribution of individual data points to the overall pattern of scatter. These distances are called residuals, because they are what is “left over” after fitting the line. Points above the line have a positive residual. The sum of the residuals is always 0. Points below the line have a negative residual. Predicted ŷ Observed y y yˆ residual Residual plots Residuals are the differences between y-observed and y-predicted. We plot them in a residual plot, which plots residuals vs. x. If the data are best predicted simply by using a straight line then the residuals will be scattered randomly above and below 0. The x-axis in a residual plot is the same as on the scatterplot. Only the y-axis is different. Constant mean and spread. Residuals are randomly scattered – good! Non-constant mean. Curved pattern—means the relationship you are looking at (e.g., a straight line) has not been fit properly. Non-constant spread. A change in variability across a plot indicates that the response variable is less predictable for some values of x than for others. This can affect the accuracy of statistical inference. Outliers and influential points Outlier: an observation that lies outside the overall pattern of observations. Influential observation: an observation that markedly changes the regression if removed. This is often an outlier on the x-axis. Child 19 = outlier in y direction Child 19 is an outlier of the relationship. Child 18 = outlier in x direction Child 18 is only an outlier in the x direction and thus might be an influential point. outlier in y-direction All data Without child 18 Without child 19 Are these points influential? influential Always plot your data A correlation coefficient and a regression line can be calculated for any relationship between two quantitative variables. However, outliers greatly influence the results, and running a linear regression on a nonlinear association is not only meaningless but misleading. So make sure to always plot your data before you run a correlation or regression analysis. Anscombe’s examples: The four data sets below were constructed so that they each have correlation r = 0.816, and the regression lines are all approximately ŷ = 3 + 0.5x. For all four sets, we would predict ŷ = 8 when x = 10. Anscombe’s examples: The four scatterplots show that the correlation or regression analysis is not appropriate for just any data set with two numerical variables. A moderate linear association. A straight line is regression OK. Statistical inference for SLR is OK. An obviously nonlinear relationship. A straight line regression is not OK. Fit a different curve. One point deviates from the highly linear pattern. This influential outlier must be examined closely before proceeding. Just one very influential point; all other points have the same x value. What experiment was conducted here? Vocabulary: lurking vs. confounding A lurking variable is a variable that is not among the explanatory or response variables in the analysis and yet, if observed and considered, may influence the interpretation of relationships among those variables. Two variables are confounded when their effects on a response variable cannot be distinguished (statistically) from each other. The confounded variables can be explanatory variables or lurking variables. Association is not causation. Even if a statistical association is very strong, this is not by itself good evidence that a change in x will cause a change in y. The association would be just as strong if we reversed the roles of x and y. Cautions before rushing into a correlation or a regression analysis Do not use a regression on inappropriate data. Clear pattern in the residuals Presence of large outliers Clustered data falsely appearing linear Use residual plots for help in seeing these. Beware of lurking variables. Avoid extrapolating (predicting beyond values in the data set). Recognize when the correlation/regression is being performed on values that are averages of another variable. An observed relationship in the data, however strong it is, does not imply causation just on its own.