Chapter 4A
advertisement

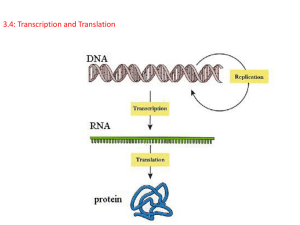
Chap. 4. Basic Molecular Genetic Mechanisms (Part A) Topics • Structure of Nucleic Acids • Transcription of Protein-coding Genes and Formation of Functional mRNA • Decoding of mRNA by tRNAs • Stepwise Synthesis of Proteins on Ribosomes • DNA Replication Goals To learn the basic mechanisms of transcription, RNA processing, translation, and replication Fig. 4.1. The “Incredible Hulk of Hounds” The “double muscle” phenotype commonly occurs due to defective splicing of the myostatin gene in animals. Myostatin is a protein that limits skeletal muscle development. Nucleic Acid Strands Nucleic acids are polymers derived from nucleotides. As shown in Fig. 4.2a, the backbone consists of repetitive [-phosphate-(deoxy)ribose-] units. Individual nucleotides are joined by phosphodiester linkages. Like proteins, nucleic acid chains have a polarity which is defined by the 5' and 3' ends of the sequence. By convention, the sequence of bases in a strand is written left-to-right from the 5' to 3' end (Fig. 4.2b). Structure of Double-helical DNA Cellular DNA exists primarily in a right-handed double-helical form (Fig. 4.3). The double helix contains two interwound, antiparallel DNA strands (see arrows). The strands are complementary and pair together via Watson-Crick base pairs (A.T; G.C). The backbones of the strands are located on the outside of the helix, while the bases are stacked inside. In the most common conformation of the double helix (B DNA), ~10 bp occur per turn. B DNA molecules contain wide (major) and narrow (minor) grooves in which parts of the bases are exposed to the outside. DNA binding proteins locate and interact with specific base sequences exposed in the grooves. DNA Bending DNA can be bent because it lacks stabilizing bonds oriented parallel to the axis of the double helix. Bending commonly occurs on binding of transcription factors, e.g., TATA boxbinding protein (TBP) (Fig. 4.5), and DNA-binding proteins such as histones. Bending is crucial for the packaging of DNA in chromatin inside eukaryotic cells. Supramolecular Structure In many cases, multimeric proteins achieve extremely large sizes, e.g., 10s-100s of subunits. Such complexes exhibit the highest level of structural organization known as supramolecular structure. Examples include mRNA transcription preinitiation complexes (Fig. 3.12), ribosomes, proteasomes, and spliceosomes. Typically, supramolecular complexes function as ”macromolecular machines" in reference to the fact that the activities of individual subunits are coordinated in the performance of some overall task (e.g., protein synthesis by the ribosome). Base-catalyzed Hydrolysis of RNA DNA and RNA differ w.r.t. the sugar found in their nucleotide monomer units (2-deoxyribose vs ribose). The phosphodiester bonds of RNA are susceptible to hydrolysis in basic solution due to the presence of the 2’-hydroxyl group of ribose (Fig. 4.6). In contrast, the phosphodiester bonds in DNA are much less susceptible because 2-deoxyribose lacks this group. It is thought that DNA was selected over RNA as the preferred molecule for long-term storage of genetic information because it is a less reactive molecule due to its containing 2-deoxyribose. DNA Denaturation/Renaturation DNA denaturation refers to the unwinding and separation (melting) of the two strands of a double-helical DNA molecule. In vivo, enzymes such as helicases, for example, separate DNA strands. In vitro, denaturation is achieved by heating (Fig. 4.7a) or by treatment with low ionic strength buffers or extremes of pH. DNA denaturation can be monitored by UV absorption spectroscopy. Because G.C base pairs are held together by 3 H-bonds, whereas A.T base pairs are connected by 2 H-bonds, the melting point of double helical DNA increases with G+C content (Fig. 4.7b). In DNA renaturation, double helical molecules are formed by the annealing of single-stranded molecules. DNA Supercoiling Processes such as replication that unwind double-helical DNA introduce torsional stress that results in supercoiling. This is most evident in circular DNA molecules such as bacterial plasmids and some viruses (Fig. 4.8a), but occurs in linear eukaryotic chromosomes as well. Replication causes over-winding ahead of the strand separation site and positive supercoiling. Underwinding can occur resulting in negative supercoiling. Enzymes called topoisomerases regulate the amount of supercoiling in DNA in vivo. Topoisomerase I relaxes supercoiled DNA (Fig. 4.8b). Topoisomerase II introduces negative supercoils into DNA. Cellular DNA naturally exists in a slightly negatively supercoiled state. Negative supercoiling facilitates processes such as replication and transcription, where DNA is unwound. Nick RNA Structure Most cellular RNAs consist of a single strand. However, doublehelical regions are common in RNA where complementary sequence regions occur. Common types of RNA secondary structure elements are hairpins and stem-loop structures (Fig. 4.9a). Stem regions form A DNA-type double helices. The turns connecting the helices are shorter in hairpins than in stem-loops. RNAs also form elaborate 3D structures in molecules such as tRNA and rRNA. The ”pseudoknot” tertiary structure found in the human telomerase RNA is illustrated in Fig. 4.9b. The 3D structures of ribozymes rival those of proteins with respect to complexity. Mechanism of Transcription In transcription, a sequence in DNA is copied into RNA in a reaction catalyzed by RNA polymerase. The RNA synthesized is complementary to, and runs antiparallel to the template strand (Fig. 4.10a). The RNA sequence is the same as the coding strand (not shown). Growth of the RNA chain occurs in the 5' to 3' direction. The mechanism of the nucleotide polymerization reaction proceeds with the elimination of inorganic pyrophosphate (PPi). The transcription start site is numbered +1. DNA sequences preceding the start site are located "upstream" whereas sequences after the start site are located "downstream." Conventions for Describing RNA Transcription The primary RNA transcript produced in transcription has the same sequence as the coding or nontemplate strand of DNA (Fig. 4.10b). It is complementary to the template strand of DNA. The promoter is a DNA sequence in the nontemplate strand of DNA that tells RNA polymerase where to begin transcription (+1 site) of a gene. Transcription Initiation Transcription by RNA polymerase occurs in 3 stages-initiation, elongation, and termination (Fig. 4.11). In initiation, RNA polymerase binds to a promoter, typically with the assistance of transcription factors. About 14 base pairs of DNA are melted (the transcription bubble), and the enzyme synthesizes a 2-nucleotide RNA complementary to the template strand. Transcription is regulated primarily at the initiation stage. Transcription Elongation After initiation, RNA polymerase clears the promoter, leaving transcription factors behind. It maintains a 14-residue bubble as it moves downstream elongating the RNA, which grows in the 5' to 3' direction. The nascent RNA remains H-bonded to the template strand via its last 8 nucleotides (the DNA-RNA hybrid region). Elongation proceeds at ~1,000 nucleotides per minute in eukaryotes. Transcription Termination When RNA polymerase encounters a termination sequence, transcription stops and the polymerase and the completed "primary transcript" are released from the DNA. RNA polymerase then is free to initiate transcription at another promoter. Gene Organization in Prokaryotes About half of the genes in prokaryotic cells occur in transcription units known as operons. Operons are transcribed from a single promoter and usually contain genes that participate in a common process such as synthesis of tryptophan, e.g., the trp operon of E. coli (Fig. 4.13a). The trp operon mRNA is polycistronic and encodes 5 different proteins. Each cistron coding sequence is translated into a protein. Gene Organization in Eukaryotes Most eukaryotic genes are transcribed separately, even in simple organisms such as yeast. The TRP biosynthesis genes, for example, each have their own promoter and actually are encoded on different chromosomes in yeast (Fig. 4.13b). In addition, gene coding sequences in higher eukaryotes typically are interrupted with non-translated sequences known as introns. Intron sequences in pre-RNA are removed by RNA processing reactions prior to formation of the final functional mRNA. Eukaryotic pre-mRNA Processing: Capping Bacterial mRNAs are functionally active as transcribed. Eukaryotic pre-mRNAs must be extensively processed to attain their final functional forms. The modification that occurs at the 5' end of the primary transcript is called the 5' cap (m7Gppp) (Fig. 4.14). In this modification, a 7-methylguanylate residue is attached to the first nucleotide of the pre-mRNA by a 5'-5' linkage. The 2'-hydroxyl groups of the ribose residues of the first 2 nucleotides may also be methylated. The 5' cap is important for transport of the mRNA to the cytoplasm, protection against nuclease degradation, and initiation of translation. Eukaryotic pre-mRNA Processing: Splicing & Polyadenylation Eukaryotic pre-mRNAs are capped at the 5' end while being transcribed. They also are modified at the 3' end by polyadenylation (Fig. 4.15). This involves cleavage of the longer pre-mRNA at the polyadenylation site and the addition of up to 250 adenylate residues by template-independent poly(A) polymerase. Non-coding RNA intron sequences are excised and the coding exon sequences are ligated to form the functional mRNA by the process known as splicing. The mRNA retains 5' and 3' untranslated regions (UTRs) at each end.The poly(A) tail helps protect the mRNA from nuclease digestion. The “Incredible Hulk of Hounds” The “double muscle” phenotype commonly occurs due to defective splicing of the myostatin gene in animals. Myostatin is a protein that limits skeletal muscle development. Alternative Splicing & Gene Regulation Protein domains can be encoded by a single exon or by a small collection of exons within a larger gene. The coding regions for domains can be spliced in or out of the primary transcript by the process of alternative splicing. The resulting mRNAs encode different forms of the protein, known as isoforms. Alternative splicing is an important method for regulation of gene expression in different tissues and different physiological states. It is estimated that 60% of all human genes are expressed as alternatively spliced mRNAs. Alternative splicing is illustrated in Fig. 4.16 for the fibronectin gene. The fibroblast and hepatocyte isoforms differ in their content of the EIIIA and EIIIB domains which mediate cell surface binding.Twenty different isoforms of fibronectin produced by alternative splicing have been identified.