A Fast Algorithm for Multi
advertisement

A Fast Algorithm for
Multi-Pattern Searching
Sun Wu, Udi Manber
Tech. Rep. TR94-17,Department of Computer
Science, University of Arizona, May 1994
1
Outline
Introduction
Boyer-Moore algorithm review
Fast algorithm for Multi-Pattern Search
Preprocessing Stage
Scanning Stage
Performance
Experiments
Conclusion
2
Introduction
Given a algorithm to find all occurrences
of all the pattern of P in T.
P={p1, p2, ......, pk} be the ser of patterns,
which are strings of characters from a
fixed alphabet Σ.
T = t1, t2, ...., tN be a large text, consisting
of character from Σ.
3
Boyer-Moore algorithm review
Symbol used:
Σ : the set of alphabets
patlen : the length of pattern
m : the last m characters of pattern matched
char : the mismatched character
char
………
………
string
pattern
m
4
Bad Character Heuristic
Observation 1:
If the char doesn’t occur in pat:
Pattern Shift : j character
String pointer shift: patlen character
Example:
string ptr
......a c d a b b a c d e a f e c a ........ text
a b c e pat
5
Bad Character Heuristic (cont.)
Observation 2:
If the char occur in the pattern
The rightmost char in pattern in position δ1[char]
and the pointer to the pattern is in j
If j < δ1 [char] we shift the pattern right by 1
If j > δ1 [char] we shift the pattern right by
j- δ1 [char]
We say δ1 is SHIFT table
6
Bad Character Heuristic (cont.)
Example:
j < δ1 [char]
δ1[A] = 7 and j = 4
shift pattern right by 1
string ptr
......A C F D B A D A E C A D A E....... text
DAECECA
j
j δ1 [char]
string ptr
......A C F D B A D A E
δ1[A] = 2 and j = 4
C A D A E.......
text
shift
pattern right by 2
DAECEC
j
7
Multi-Pattern Searching
Instead looking at character from text one by
one, we consider them in blocks of size B.
text
size = B
A good value of B is in the order of logc2M. In
practice, we use either B=2 or B=3.
M is the total size of all patterns.
c is the size of the alphabet.
8
Multi-Pattern Searching (cont.)
Preprocessing Stage built three tables for
the set of patterns:
SHIFT table :
like Boyer-Moore’s Shift table with little different.
HASH table and PREFIX table:
used when the shift value = 0.
9
Preprocessing Stage
First Compute the minimum length m of a
pattern, and consider first m character of
each pattern.
SHIFT table contains all possible string of
size B
Table size is cB
We can use hash function to compress table.
10
SHIFT table
Let X = x1x2.....xB be the B characters in the text,
and X is mapped into i’th entry of SHIFT table.
Case 1:
X doesn’t appear as a substring in P, we shift text
m-B+1 characters.
D A B C A D B A A B
A D B A
text
m =4, B =2
so we shift pattern
m-B+1
11
SHIFT table (cont.)
Case 2:
X appears in some patterns:To find the rightmost
occurrence of X in any of the patterns.
G A
B
C A
C
A
A
B
A
C
A
D
D
C
E
B
D
text
X ends at position q of Pj, and q is the largest in all
possible patterns.
We shift text m-j characters-> SHIFT[i] = m-j.
12
SHIFT table (cont.)
The value of SHIFT table are the largest
possible safe value for shifts.
To do pre-scan all of the patterns, set
SHIFT value min(current value, m-j)
Initial value is m-B+1
We can map several different strings into
the same entry.
13
HASH table
When SHIFT[i] = 0, we match some
patterns.
HASH[i] records the pointer PAT_POINT
which point to the patterns.
…
…..
list of PAT_POINT
patterns which sorted by the hash value of the last B
characters of each pattern.
14
HASH table (cont.)
HASH[i] = p, point to the beginning of the
list of patterns whose hash value
mapped to h.
To find the end of this list, we keep
incrementing this pointer until it’s value
equal to the value in HASH[i+1]
15
PREFIX table
Nature language isn’t random. The suffix
“ion”, “ing” is common in English Text.
It may appear in several of the patterns.
We use PREFIX table to speed up this
process.
Mapping the first B’ characters of all
patterns into Prefix function.
It can filter patterns whose suffix is the
same but whose prefix is different.
16
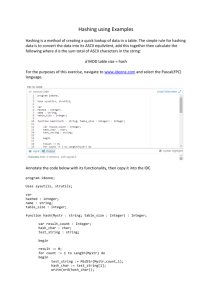
Scanning Stage
while (text <= textend) {
h = Huchfunct(B); /* The hash function (we use Hbits=5) */
shift = SHIFT[h];
Text possible shift
1.Compute the hash value
if (shift == 0) {
zero. Some
h based on the B character
text_prefix =is(*(text-m+1)<<8)
+ *(text-m+2);
from the text
p = HASH[h];match happened.
p_end = HASH[h+1];
while (p++ < p_end) {
if(text_prefix != PREFIX[p]) continue;
px = PAT_POINT[p];
qx = text-m+1;
while (*(px++) == *(qx++));
if (*(px-1) == 0) { /* 0 indicates the end of a string */
Check for each p HASH[i] report a match
}
<= p < HASH[i+1] where
shift = 1;
PREFIX[p] = text_prefix.
}
text += shift;
}
17
Performance
The SHIFT table is constructed in O(M)
M=m*P
B = logc2M
cB = clogc2M 2Mc
18
Performance (cont.)
Lemma:
The probability of random string of size B leads to a
shift value of i, is <=1/2m
Prof:
1. P = M/m strings lead to shift value of i
2. the number of possible strings of size B is
2M at least
19
Performance (cont.)
Lemma implies that the expected value
of shift is >= m/2
total amount of non-zero shift is O(BN/m)
shift = 0, the amount of cost is
O(m) * O(1/2m)
The total amount is O(BN/m)
20
Experiment
21
Experiment (cont.)
22
Conclusion
This algorithm use three table : SHIFT,
HASH, Prefix, to save scanning time.
Preprocessing stage cost is low.
It can use in many application, such as
file search in database,
23