3D_Object_Recognition_Slides_Lee
advertisement

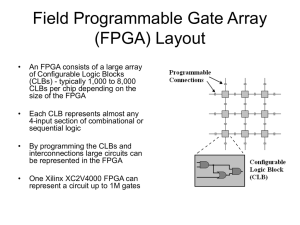
3D Object Recognition Using Computer Vision VanGogh Imaging, Inc. Kenneth Lee CEO/Founder klee@vangoghimaging.com Corporate Overview Founded in 2007, located in McLean VA Mission: “Provide easy to use, real-time 3D computer vision (CV) technology for embedded and mobile applications” – 2D to 3D for better visualization, higher reliability, and accuracy – Solve problems that require spatial measurements (e.g. parts inspection) Target customer: Application and System Developers – Enhance existing product or develop new products Product: ‘Starry Night’ 3D-CV Middleware (Unity Plugin) – Operating Systems: Android and Linux – 3D Sensor: Occipital Structure and Intel RealSense – Processors: ARM and Xilinx Zynq Our focus – Object recognition – Feature detection – Analysis (e.g., measurements) Potential Applications 3D Printing Parts Inspection Robotics Security Entertainment Automotive Safety Medical Imaging Challenges for Implementing Real-Time 3D Computer Vision – – – – – – – Busy uncontrolled real-world environment Limited processing power and memory Noisy and uncalibrated low-cost scanners Difficult to use libraries Hard to find proficient computer vision engineers Lack of standards Large development investment Starry Night Unity Plugin (patent pending) Starry Night Video: https://www.youtube.com/watch?v=IZX-9PH7Erw&feature=youtu.be The ‘Starry Night’ Template-Based 3D Model Reconstruction Reliable - The output is always a fully-formed 3D model with known feature points despite noisy or partial scans Easy to use – Fully automated process Powerful – Known data structure for easy analysis and measurement Fast – Real-time modeling Input Scan (Partial) + Reference Model = Full 3D Model 3D Object Recognition Algorithm for mobile and embedded Devices Challenges - Scene Busy scene, object orientation, and occlusion Challenges - Platform Mobile and Embedded Devices – ARM – A9 or A15, <2G RAM – Existing libraries were built for laptop/desktop platform – GPU processing is not always available Previous Approaches (2D) Texture-Based Methods – Color-based → depends heavily on lighting or color of the object – Machine learning → robust, but requires training for each object – Neither method provides transform (i.e., orientation) (3D) Methods – – – – Hough transform and geometric hashing → slow Geometric hashing → even slower Tensor matching → not good for noisy and sparse scene Correspondence-based methods using rigid geometric descriptors – The models must have distinctive feature points which is not true for most models (i.e., cylinder) Tried General Concept for CV-Based Object Recognition Reference Object Descriptor Distance & Normal Match Criteria Compare Scene Distance & Normal of Random Sample Points Fine-Tune Orientation Location Transpose Block Diagram Model Descriptor (Pre-Processed) Sample all point pairs in the model that are separated by the same distance D Use the surface normal of the pair to group them into the hash tablet Note: In the bear example, D = 5 cm which resulted in 1000 pairs Note: The keys are angles derived from the normal of the points. alpha(α) = first normal to second point beta(β) = second normal to first point omega(Ω) = angle of the plane between two points key (α1,β1,Ω1) P1, P2 P3, P4 (α2,β2,Ω2) P5, P6 P7, P8 (α3,β3,Ω3) P13, P14 P9, P10 P11, P12 Object Recognition Workflow Grab Scene Sample point pair w/ distance D using RANSAC Generate key using same hash function Use key to retrieve similarly oriented points in the model & rough transform Match criteria to find the best match Note: The example scene has around 16K points Note: We iterated this sampling process 100 times Note: Entire process can be easily parallelized Very Important: Multiple models can be found using a single hash table, for example, sampled point pair in the scene Use ICP to refine transform Implementation Result Object Recognition Video: https://www.youtube.com/watch?v=h7whfei0fTw&feature=youtu.be Object Recognition Examples * CONFIDENTIAL * 18 Adaptive 3D Object Recognition Algorithm Resize and Reshape Object Recognition for Different Sizes & Shape Objects in the real world are not always identical Similarity Factor, S%, can be used to denote % of shape difference – This allows recognition of object that’s similar but does not have the exact shape as the reference model Size Factor, Z%, can be used to note the % size the object can recognize – This allows recognition of object that’s of different sizes from the reference model General Approach Dynamically resizes the reference model Dynamically reshapes the reference model – Uses our ‘Shape-based Registration’ technique Hence, the reference model is ‘deformed’ to match the object in the scene Results in very robust object recognition The end reference model best represents the object in the scene both in size and shape Block Diagram – Adaptive Object Recognition with feedback Reference model is iteratively modified with every new frame until it converges into the same object in the scene Note: Currently in the process of being implemented and will be available in Version 1.2 later this year Object Recognition Performance Numbers Reliability (w/ bear model) Reliability – % false positives – depends on the scene – Clean scene: <1% – Noisy scene: 5% (1 out of 20 frames) – % negative results (cannot find the object) – Clean scene: <1% – Noisy scene: 10% (also takes longer) Effect of orientation on success ratio – Model facing front: >99% – Model facing backwards: >99% – Model facing sideways (narrower): 85% Performance - Mobile Performance on Cortex A-15 2GHz ARM (on Android mobile) – Amount of time it takes to find one object – Single thread: 2 seconds – Multi-thread & NEON: 0.3 second – Amount of time it takes to find two objects – Single thread: 2.5 seconds – Multi-thread & NEON: 0.5 second Note: Effective use of NEON led to significant performance gains of X2.5 for certain functions Hardware Acceleration Using FPGA • Xilinx Zynq SoC provides 20 to 1,000 parallel voxel processors depending on the size of the FPGA Zynq FPGA voxel voxel ARM voxel scan voxel voxel Processor 1 Processor 1 Processor 1 Processor 1 Processor 20+ Hardware Acceleration: FPGA (Xilinx Zynq) Select Functions to Be Implemented in Zynq – FPGA: Matrix operations – Dual-core ARM: Data management + Floating point – Entire implementation done in C++ (Xilinx Vivado-HLS) Performance: Embedded Using FPGA Note: Currently, only 30% of the computationally intensive functions are implemented on the FPGA with the rest still running on ARM A9. Speed will be much improved once the remaining high-intensity functions are transferred to the FPGA. Performance on Xilinx Zynq (Cortex A-9 800 MHZ + FPGA) – Amount of time it takes to find one object – Zynq 7020: 0.7 second – Zynq 7045 (est.): 0.1 second – No test results for two objects, but should scale the same way as for the ARM Future The chosen algorithm works well in most real-world conditions The chosen algorithm is tolerant to size and shape differences respect to the reference model The chosen algorithm can find multiple objects at the same time with minimal additional processing power Additional improvements in performance are needed – – – – Algorithm Application-specific parameters (e.g., size of the model descriptor) ARM - NEON Optimize the use of FPGA core Summary Key implementation issues – – – – Model descriptor Data structure Sampling technique Platform IMPORTANT – Both ARM & FPGA provide the scalability Therefore – Real-time 3D object recognition was very difficult but successfully implemented on both mobile and embedded platforms! LIVE DEMO AT THE Xilinx BOOTH! Resources www.vangoghimaging.com Android 3D printing: http://www.youtube.com/watch?v=7yCAVCGvvso “Challenges and Techniques in Using CPUs and GPUs for Embedded Vision” by Ken Lee, VanGogh Imaging—http://www.embeddedvision.com/platinum-members/vangogh-imaging/embedded-visiontraining/videos/pages/september-2012-embedded-vision-summit “Using FPGAs to Accelerate Embedded Vision Applications”, Kamalina Srikant, National Instruments— http://www.embeddedvision.com/platinum-members/national-instruments/embedded-visiontraining/videos/pages/september-2012-embedded-vision-summit “Demonstration of Optical Flow algorithm on an FPGA”— http://www.embedded-vision.com/platinum-members/bdti/embeddedvision-training/videos/pages/demonstration-optical-flow-algorithm-fpg * Reference: “An Efficient RANSAC for 3D Object Recognition in Noisy and Occluded Scenes” by Chavdar Papazov and Darius Burschka. Technische Universitat Munchen (TUM), Germany.